

CS Associate Professor Alexander Sasha Rush has successfully moved the International Conference on Learning Representations (ICLR) to an entirely online environment. As reported on Medium:
From today, all content for the ICLR 2020 Virtual Conference is available in open-access for anyone across the world to learn from. A public archive of the virtual conference site is now available for everyone to explore the 2020 conference proceedings, and to get a sense of the virtual conference portal and its flow. The registered participants site remains available.
Organising the 8th international conference on learning representations (ICLR 2020) was highly challenging, but ultimately, highly rewarding for our organising committees. Our initial work for hosting the conference in Ethiopia was far along, but then COVID-19 pandemic gave us the opportunity to create a new way of hosting our conferences. We look back now on the virtual conference week satisfied that we were able to show that a virtual conference is a viable way for us to share our science and build an international machine learning community, and that many meaningful avenues for connection are already possible.
We thank everyone for their support, patience and kindness in this time of change and experimentation. We thank the authors, organisers of workshops and socials, our volunteers, and everyone who registered. Together you made ICLR 2020 a reality and a success.
We know that there is much more to do to create a better virtual conference experience for everyone. We hope this first virtual conference is one we can collectively build upon. Towards that aim, this post summarises some of our key reflections on the design and experience of the ICLR 2020 Virtual Conference.
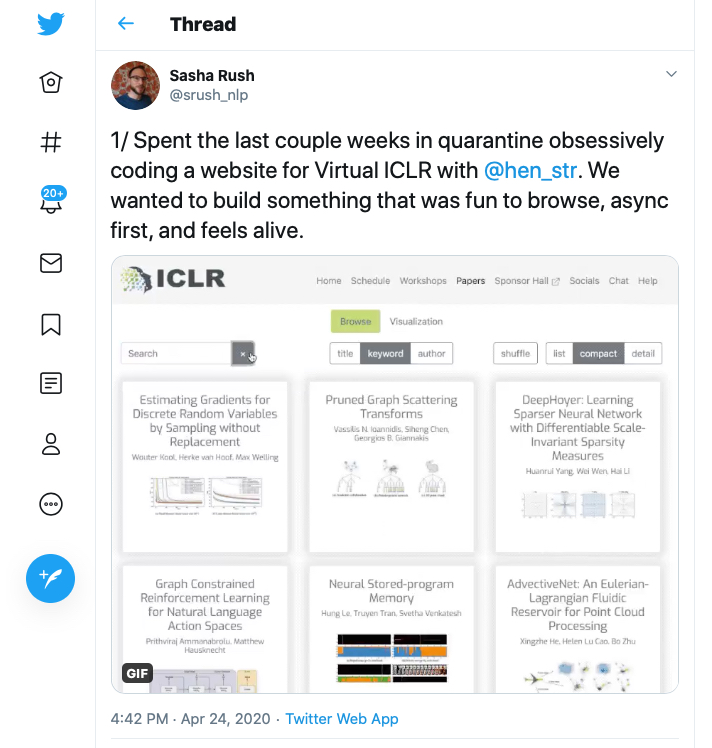
Rush also created a Twitter thread with substantive notes on the creation and implementation of the virtual event.
Rush joined the CS faculty at Cornell Tech in Fall 2019. Earlier he was an associate in computer science at the School of Engineering and Applied Sciences at Harvard and a Postdoctoral Fellow with Facebook Artificial Intelligence Research (FAIR) in New York. Sasha received his Ph.D. from MIT in 2014. Sasha’s interest lies in data-driven methods for understanding natural language. As part of this work, he develops algorithms and systems for efficient language processing with the overall goal of synthesizing large textual corpora, such as the web, into computationally useful information. His research focus is on modelling the structural aspects of language for tasks such as syntactic parsing, coreference resolution, language modelling, and part-of-speech tagging. For these problems, he utilizes formal methods from machine learning, combinatorial optimization, and deep learning.