Comparing Two Samples¶
The nearest neighbor approach to classification is motivated by the idea that an individual is likely to resemble its nearest neighbors. Looking at this another way, we can say that individuals in one class don't resemble individuals in another. Machine learning gives us a powerful way to spot this lack of resemblance and use it to classify. It illuminates patterns that we wouldn't necessarily be able to spot just by examining one or two attributes at at time.
However, there is much that we can learn from just a single attribute. To see this, we will compare the distributions of the attribute in the two classes.
Let's take a look at Brittany Wenger's breast cancer data and see whether using just one attribute has any hope of producing a reasonable classifier. As before, we'll do our exploration on a randomly chosen training set, and test our classifer on the remaining hold-out set.
patients = Table.read_table('breast-cancer.csv').drop('ID')
shuffled_patients = patients.sample(with_replacement=False)
training_set = shuffled_patients.take(np.arange(341))
test_set = shuffled_patients.take(np.arange(341, 683))
training_set
Let's see what the second attribute, Uniformity of Cell Size, can tell us about a patient's class.
training_cellsize = training_set.select('Class', 'Uniformity of Cell Size').relabel(1, 'Uniformity')
training_cellsize
The Class and Uniformity columns appear numerical but they're really both categorical. The classes are "cancerous" (1) and "not cancerous" (0). Uniformity was rated on a scale of 1 to 10, but those labels were determined by humans, and they could just as well have been ten labels like "pretty uniform", "not uniform at all", and so on. (A 2 isn't necessarily twice as uniform as a 1.) So we are comparing two categorical distributions, one for each class.
For each class, we need the number of training set patients who had each uniformity rating. The pivot method will do the counting for us.
training_counts = training_cellsize.pivot('Class', 'Uniformity')
training_counts
We now have something resembling a distribution of uniformity rating, for each class. And the two look rather different. However, let's be careful – while the total number of patients in the two classes is 341 (the size of the training set), more than half are in Class 0.
np.sum(training_counts.column('0'))
So to compare the two distributions we should convert the counts to proportions and then visualize.
def proportions(array):
return array/np.sum(array)
training_dists = training_counts.select(0).with_columns(
'0', proportions(training_counts.column('0')),
'1', proportions(training_counts.column('1'))
)
training_dists.barh('Uniformity')
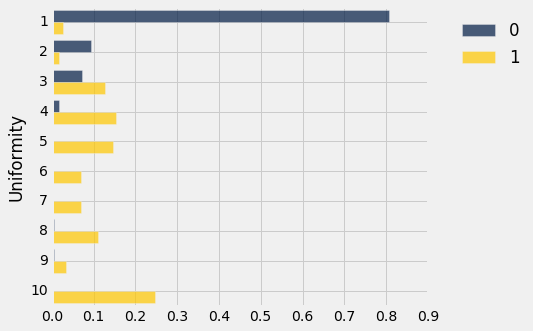
Those two distributions don't look the same at all! In fact they look so different that we should be able to construct a perfectly decent classifier based on a very straightforward observation about the difference. A simple classification rule would be, "If the uniformity is bigger than 3, say the Class is 1; that is, the cell is cancerous. Otherwise say the Class is 0."
Can something so crude be any good? Let's try it out. For any individual in the test set, all we have to do is see whether or not the uniformity rating is bigger than 3. For example, for the first 4 patients we'll get an array of four booleans:
test_set.take(np.arange(4)).column('Uniformity of Cell Size') > 3
Remember that True equals 1, which is the Class we're going to assign if the uniformity is bigger than 3. So to measure the accuracy of our crude classifier, all we have to do is find the proportion of test set patients for which the classification is the same as the patient's known class. We'll use the count_equal function we wrote in the previous section.
classification = test_set.column('Uniformity of Cell Size') > 3
count_equal(classification, test_set.column('Class'))/test_set.num_rows
That's pretty accurate, even though we're only using a one-attribute one-line-of-code classifier!
Does that mean that the nearest neighbor methods of the previous chapter are unnecessary? No, because those are even more accurate, and for cancer diagnoses any patient would want as accurate a method as possible. But it's reassuring to see that simple methods aren't bad.