Iteration¶
It is often the case in programming – especially when dealing with randomness – that we want to repeat a process multiple times. For example, to check whether np.random.choice does in fact pick at random, we might want to run the following cell many times to see if Heads occurs about 50% of the time.
np.random.choice(make_array('Heads', 'Tails'))
We might want to re-run code with slightly different input or other slightly different behavior. We could copy-paste the code multiple times, but that's tedious and prone to typos, and if we wanted to do it a thousand times or a million times, forget it.
A more automated solution is to use a for statement to loop over the contents of a sequence. This is called iteration. A for statement begins with the word for, followed by a name we want to give each item in the sequence, followed by the word in, and ending with an expression that evaluates to a sequence. The indented body of the for statement is executed once for each item in that sequence.
for i in np.arange(3):
print(i)
It is instructive to imagine code that exactly replicates a for statement without the for statement. (This is called unrolling the loop.) A for statement simple replicates the code inside it, but before each iteration, it assigns a new value from the given sequence to the name we chose. For example, here is an unrolled version of the loop above:
i = np.arange(3).item(0)
print(i)
i = np.arange(3).item(1)
print(i)
i = np.arange(3).item(2)
print(i)
Notice that the name i is arbitrary, just like any name we assign with =.
Here we use a for statement in a more realistic way: we print 5 random choices from an array.
coin = make_array('Heads', 'Tails')
for i in np.arange(5):
print(np.random.choice(make_array('Heads', 'Tails')))
In this case, we simply perform exactly the same (random) action several times, so the code inside our for statement does not actually refer to i.
Augmenting Arrays¶
While the for statement above does simulate the results of five tosses of a coin, the results are simply printed and aren't in a form that we can use for computation. Thus a typical use of a for statement is to create an array of results, by augmenting it each time.
The append method in numpy helps us do this. The call np.append(array_name, value) evaluates to a new array that is array_name augmented by value. When you use append, keep in mind that all the entries of an array must have the same type.
pets = make_array('Cat', 'Dog')
np.append(pets, 'Another Pet')
This keeps the array pets unchanged:
pets
But often while using for loops it will be convenient to mutate an array – that is, change it – when augmenting it. This is done by assigning the augmented array to the same name as the original.
pets = np.append(pets, 'Another Pet')
pets
Example: Counting the Number of Heads¶
We can now simulate five tosses of a coin and place the results into an array. We will start by creating an empty array and then appending the result of each toss.
coin = make_array('Heads', 'Tails')
tosses = make_array()
for i in np.arange(5):
tosses = np.append(tosses, np.random.choice(coin))
tosses
Let us rewrite the cell with the for statement unrolled:
coin = make_array('Heads', 'Tails')
tosses = make_array()
i = np.arange(5).item(0)
tosses = np.append(tosses, np.random.choice(coin))
i = np.arange(5).item(1)
tosses = np.append(tosses, np.random.choice(coin))
i = np.arange(5).item(2)
tosses = np.append(tosses, np.random.choice(coin))
i = np.arange(5).item(3)
tosses = np.append(tosses, np.random.choice(coin))
i = np.arange(5).item(4)
tosses = np.append(tosses, np.random.choice(coin))
tosses
By capturing the results in an array we have given ourselves the ability to use array methods to do computations. For example, we can use np.count_nonzero to count the number of heads in the five tosses.
np.count_nonzero(tosses == 'Heads')
Iteration is a powerful technique. For example, by running exactly the same code for 1000 tosses instead of 5, we can count the number of heads in 1000 tosses.
tosses = make_array()
for i in np.arange(1000):
tosses = np.append(tosses, np.random.choice(coin))
np.count_nonzero(tosses == 'Heads')
Example: Number of Heads in 100 Tosses¶
It is natural to expect that in 100 tosses of a coin, there will be 50 heads, give or take a few.
But how many is "a few"? What's the chance of getting exactly 50 heads? Questions like these matter in data science not only because they are about interesting aspects of randomness, but also because they can be used in analyzing experiments where assignments to treatment and control groups are decided by the toss of a coin.
In this example we will simulate 10,000 repetitions of the following experiment:
- Toss a coin 100 times and record the number of heads.
The histogram of our results will give us some insight into how many heads are likely.
As a preliminary, note that np.random.choice takes an optional second argument that specifies the number of choices to make. By default, the choices are made with replacement. Here is a simulation of 10 tosses of a coin:
np.random.choice(coin, 10)
Now let's study 100 tosses. We will start by creating an empty array called heads. Then, in each of the 10,000 repetitions, we will toss a coin 100 times, count the number of heads, and append it to heads.
N = 10000
heads = make_array()
for i in np.arange(N):
tosses = np.random.choice(coin, 100)
heads = np.append(heads, np.count_nonzero(tosses == 'Heads'))
heads
Let us collect the results in a table and draw a histogram.
results = Table().with_columns(
'Repetition', np.arange(1, N+1),
'Number of Heads', heads
)
results
Here is a histogram of the data, with bins of width 1 centered at each value of the number of heads.
results.select('Number of Heads').hist(bins=np.arange(30.5, 69.6, 1))
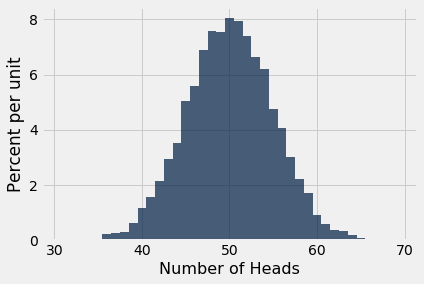
Not surprisingly, the histogram looks roughly symmetric around 50 heads. The height of the bar at 50 is about 8% per unit. Since each bin is 1 unit wide, this is the same as saying that about 8% of the repetitions produced exactly 50 heads. That's not a huge percent, but it's the largest compared to the percent at every other number of heads.
The histogram also shows that in almost all of the repetitions, the number of heads in 100 tosses was somewhere between 35 and 65. Indeed, the bulk of the repetitions produced numbers of heads in the range 45 to 55.
While in theory it is possible that the number of heads can be anywhere between 0 and 100, the simulation shows that the range of probable values is much smaller.
This is an instance of a more general phenomenon about the variability in coin tossing, as we will see later in the course.