Implementing the Classifier¶
We are now ready to impelment a $k$-nearest neighbor classifier based on multiple attributes. We have used only two attributes so far, for ease of visualization. But usually predictions will be based on many attributes. Here is an example that shows how multiple attributes can be better than pairs.
Banknote authentication¶
This time we'll look at predicting whether a banknote (e.g., a \$20 bill) is counterfeit or legitimate. Researchers have put together a data set for us, based on photographs of many individual banknotes: some counterfeit, some legitimate. They computed a few numbers from each image, using techniques that we won't worry about for this course. So, for each banknote, we know a few numbers that were computed from a photograph of it as well as its class (whether it is counterfeit or not). Let's load it into a table and take a look.
banknotes = Table.read_table('banknote.csv')
banknotes
Let's look at whether the first two numbers tell us anything about whether the banknote is counterfeit or not. Here's a scatterplot:
color_table = Table().with_columns(
'Class', make_array(1, 0),
'Color', make_array('darkblue', 'gold')
)
banknotes = banknotes.join('Class', color_table)
banknotes.scatter('WaveletVar', 'WaveletCurt', colors='Color')
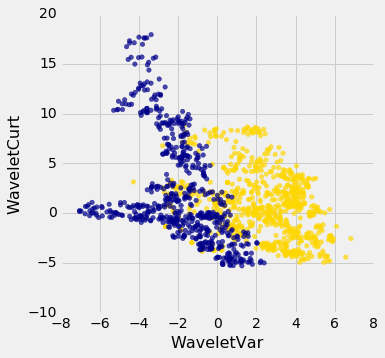
Pretty interesting! Those two measurements do seem helpful for predicting whether the banknote is counterfeit or not. However, in this example you can now see that there is some overlap between the blue cluster and the gold cluster. This indicates that there will be some images where it's hard to tell whether the banknote is legitimate based on just these two numbers. Still, you could use a $k$-nearest neighbor classifier to predict the legitimacy of a banknote.
Take a minute and think it through: Suppose we used $k=11$ (say). What parts of the plot would the classifier get right, and what parts would it make errors on? What would the decision boundary look like?
The patterns that show up in the data can get pretty wild. For instance, here's what we'd get if used a different pair of measurements from the images:
banknotes.scatter('WaveletSkew', 'Entropy', colors='Color')
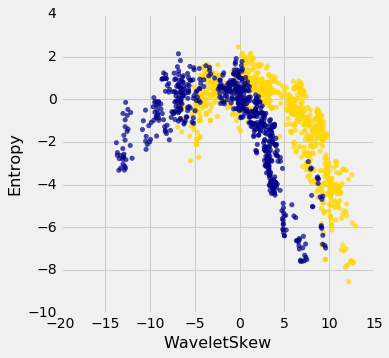
There does seem to be a pattern, but it's a pretty complex one. Nonetheless, the $k$-nearest neighbors classifier can still be used and will effectively "discover" patterns out of this. This illustrates how powerful machine learning can be: it can effectively take advantage of even patterns that we would not have anticipated, or that we would have thought to "program into" the computer.
Multiple attributes¶
So far I've been assuming that we have exactly 2 attributes that we can use to help us make our prediction. What if we have more than 2? For instance, what if we have 3 attributes?
Here's the cool part: you can use the same ideas for this case, too. All you have to do is make a 3-dimensional scatterplot, instead of a 2-dimensional plot. You can still use the $k$-nearest neighbors classifier, but now computing distances in 3 dimensions instead of just 2. It just works. Very cool!
In fact, there's nothing special about 2 or 3. If you have 4 attributes, you can use the $k$-nearest neighbors classifier in 4 dimensions. 5 attributes? Work in 5-dimensional space. And no need to stop there! This all works for arbitrarily many attributes; you just work in a very high dimensional space. It gets wicked-impossible to visualize, but that's OK. The computer algorithm generalizes very nicely: all you need is the ability to compute the distance, and that's not hard. Mind-blowing stuff!
For instance, let's see what happens if we try to predict whether a banknote is counterfeit or not using 3 of the measurements, instead of just 2. Here's what you get:
ax = plt.figure(figsize=(8,8)).add_subplot(111, projection='3d')
ax.scatter(banknotes.column('WaveletSkew'),
banknotes.column('WaveletVar'),
banknotes.column('WaveletCurt'),
c=banknotes.column('Color'));
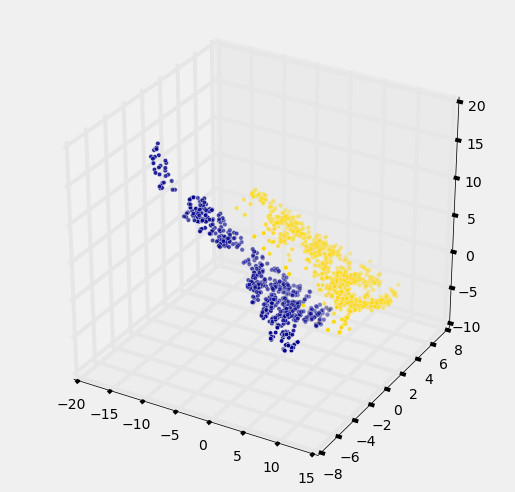
Awesome! With just 2 attributes, there was some overlap between the two clusters (which means that the classifier was bound to make some mistakes for pointers in the overlap). But when we use these 3 attributes, the two clusters have almost no overlap. In other words, a classifier that uses these 3 attributes will be more accurate than one that only uses the 2 attributes.
This is a general phenomenom in classification. Each attribute can potentially give you new information, so more attributes sometimes helps you build a better classifier. Of course, the cost is that now we have to gather more information to measure the value of each attribute, but this cost may be well worth it if it significantly improves the accuracy of our classifier.
To sum up: you now know how to use $k$-nearest neighbor classification to predict the answer to a yes/no question, based on the values of some attributes, assuming you have a training set with examples where the correct prediction is known. The general roadmap is this:
- identify some attributes that you think might help you predict the answer to the question.
- Gather a training set of examples where you know the values of the attributes as well as the correct prediction.
- To make predictions in the future, measure the value of the attributes and then use $k$-nearest neighbor classification to predict the answer to the question.
Distance in Multiple Dimensions¶
We know how to compute distance in 2-dimensional space. If we have a point at coordinates $(x_0,y_0)$ and another at $(x_1,y_1)$, the distance between them is
$$D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2}.$$
In 3-dimensional space, the points are $(x_0, y_0, z_0)$ and $(x_1, y_1, z_1)$, and the formula for the distance between them is
$$ D = \sqrt{(x_0-x_1)^2 + (y_0-y_1)^2 + (z_0-z_1)^2} $$
In $n$-dimensional space, things are a bit harder to visualize, but I think you can see how the formula generalized: we sum up the squares of the differences between each individual coordinate, and then take the square root of that.
In the last section, we defined the function distance which returned the distance between two points. We used it in two-dimensions, but the great news is that the function doesn't care how many dimensions there are! It just subtracts the two arrays of coordinates (no matter how long the arrays are), squares the differences and adds up, and then takes the square root. To work in multiple dimensions, we don't have to change the code at all.
def distance(point1, point2):
"""Returns the distance between point1 and point2
where each argument is an array
consisting of the coordinates of the point"""
return np.sqrt(np.sum((point1 - point2)**2))
Let's use this on a new dataset. The table wine contains the chemical composition of 178 different Italian wines. The classes are the grape species, called cultivars. There are three classes but let's just see whether we can tell Class 1 apart from the other two.
wine = Table.read_table('wine.csv')
# For converting Class to binary
def is_one(x):
if x == 1:
return 1
else:
return 0
wine = wine.with_column('Class', wine.apply(is_one, 0))
wine
The first two wines are both in Class 1. To find the distance between them, we first need a table of just the attributes:
wine_attributes = wine.drop('Class')
distance(np.array(wine_attributes.row(0)), np.array(wine_attributes.row(1)))
The last wine in the table is of Class 0. Its distance from the first wine is:
distance(np.array(wine_attributes.row(0)), np.array(wine_attributes.row(177)))
That's quite a bit bigger! Let's do some visualization to see if Class 1 really looks different from Class 0.
wine_with_colors = wine.join('Class', color_table)
wine_with_colors.scatter('Flavanoids', 'Alcohol', colors='Color')
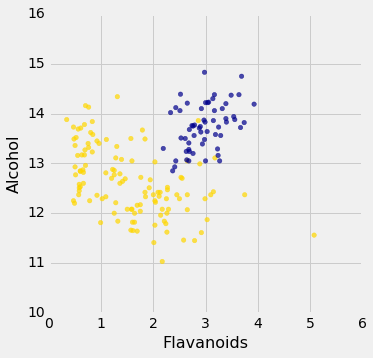
The blue points (Class 1) are almost entirely separate from the gold ones. That is one indication of why the distance between two Class 1 wines would be smaller than the distance between wines of two different classes. We can see a similar phenomenon with a different pair of attributes too:
wine_with_colors.scatter('Alcalinity of Ash', 'Ash', colors='Color')
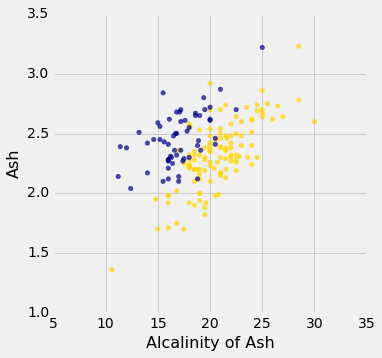
But for some pairs the picture is more murky.
wine_with_colors.scatter('Magnesium', 'Total Phenols', colors='Color')
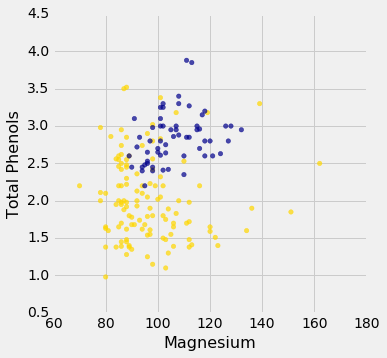
Let's see if we can implement a classifier based on all of the attributes. After that, we'll see how accurate it is.
A Plan for the Implementation¶
It's time to write some code to implement the classifier. The input is a point that we want to classify. The classifier works by finding the $k$ nearest neighbors of point from the training set. So, our approach will go like this:
Find the closest $k$ neighbors of
point, i.e., the $k$ wines from the training set that are most similar topoint.Look at the classes of those $k$ neighbors, and take the majority vote to find the most-common class of wine. Use that as our predicted class for
point.
So that will guide the structure of our Python code.
def closest(training, p, k):
...
def majority(topkclasses):
...
def classify(training, p, k):
kclosest = closest(training, p, k)
kclosest.classes = kclosest.select('Class')
return majority(kclosest)
Implementation Step 1¶
To implement the first step for the kidney disease data, we had to compute the distance from each patient in the training set to point, sort them by distance, and take the $k$ closest patients in the training set.
That's what we did in the previous section with the point corresponding to Alice. Let's generalize that code. We'll redefine distance here, just for convenience.
def distance(point1, point2):
"""Returns the distance between point1 and point2
where each argument is an array
consisting of the coordinates of the point"""
return np.sqrt(np.sum((point1 - point2)**2))
def all_distances(training, new_point):
"""Returns an array of distances
between each point in the training set
and the new point (which is a row of attributes)"""
attributes = training.drop('Class')
def distance_from_point(row):
return distance(np.array(new_point), np.array(row))
return attributes.apply(distance_from_point)
def table_with_distances(training, new_point):
"""Augments the training table
with a column of distances from new_point"""
return training.with_column('Distance', all_distances(training, new_point))
def closest(training, new_point, k):
"""Returns a table of the k rows of the augmented table
corresponding to the k smallest distances"""
with_dists = table_with_distances(training, new_point)
sorted_by_distance = with_dists.sort('Distance')
topk = sorted_by_distance.take(np.arange(k))
return topk
Let's see how this works on our wine data. We'll just take the first wine and find its five nearest neighbors among all the wines. Remember that since this wine is part of the dataset, it is its own nearest neighbor. So we should expect to see it at the top of the list, followed by four others.
First let's extract its attributes:
special_wine = wine.drop('Class').row(0)
And now let's find its 5 nearest neighbors.
closest(wine, special_wine, 5)
Bingo! The first row is the nearest neighbor, which is itself – there's a 0 in the Distance column as expected. All five nearest neighbors are of Class 1, which is consistent with our earlier observation that Class 1 wines appear to be clumped together in some dimensions.
Implementation Steps 2 and 3¶
Next we need to take a "majority vote" of the nearest neighbors and assign our point the same class as the majority.
def majority(topkclasses):
ones = topkclasses.where('Class', are.equal_to(1)).num_rows
zeros = topkclasses.where('Class', are.equal_to(0)).num_rows
if ones > zeros:
return 1
else:
return 0
def classify(training, new_point, k):
closestk = closest(training, new_point, k)
topkclasses = closestk.select('Class')
return majority(topkclasses)
classify(wine, special_wine, 5)
If we change special_wine to be the last one in the dataset, is our classifier able to tell that it's in Class 0?
special_wine = wine.drop('Class').row(177)
classify(wine, special_wine, 5)
Yes! The classifier gets this one right too.
But we don't yet know how it does with all the other wines, and in any case we know that testing on wines that are already part of the training set might be over-optimistic. In the final section of this chapter, we will separate the wines into a training and test set and then measure the accuracy of our classifier on the test set.