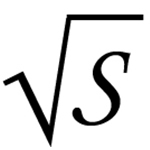A commmon problem in just about every distributed system is how to monitor and detect the failures of nodes efficiently. By "failure," we mean an inability to communicate with a remote host, regardless of the root cause. Often, a node will be tasked with monitoring a set of other nodes. The set of monitored nodes might be static and small, as in the case of monitoring a set of assigned DNS servers, or it may be dynamic and large, as in the case of a participant in a peer-to-peer network where a node needs to monitor a large number of dynamically changing peers. If bandwidth were infinite, the monitoring node could send a continuous stream of pings to every node in the set, and thus be notified of failures immediately. This is the kind of assumption that distributed systems theoreticians love to make, as it enables us to focus on more esoteric issues. Of course, bandwidth is not infinite, and sending a continuous stream of pings is untenable in a real network: it would clog the upstream link of the sending node, the downstream link of the monitored nodes, or bottleneck links inside the network, or all three! Such a system would detect failures and react to them very fast, but there would be no useful bandwidth left over from failure detection with which to carry out the intended task of the distributed system. In practice, implementors build ad hoc mechanisms for failure detection. They typically ping every node periodically, with some fixed period Τ. This approach is quite wasteful: whatever Τ might be, some nodes will be longer-lived and will not need to be pinged quite so frequently, and others have shorter lifetimes and will need to be monitored more closely. Some implementors have come up with strategies for using a different ping frequency for each host, and adaptively adjusting this frequency. While this is a step in the right direction, it is not clear which, if any, of the adaptation algorithms achieve good detection times with low overhead. In this work, we derive the best (optimal) strategy for a failure detector. We examine a multi-node failure detector, tasked with monitoring N other nodes. Unlike most of the theoretical literature on failure detection, we do not examine distributed failure detectors. Distributed failure detectors (which solve a different problem entirely) assume a multi-node failure detector underneath. We provide the basic multi-node failure detector on top of which more advanced functionality can be implemented. We identify two variants of failure detectors for achieving different goals. In many settings, it is crucial that the failure detector never exceed a particular allotted bandwidth for its monitoring. We call such failure detectors latency-minimizing, as their goal is to minimize failure detection latency subject to a bandwidth limit. In some settings, the detector is expected to detect failures within a targeted amount of time after they occur. We call such failure detectors bandwidth-minimizing, as their goal is to achieve the targeted detection latency using as little bandwidth as possible.
For latency-minimizing failure detectors, we show that the optimal probing period for each of the monitored nodes is given by the following equation:
where Τi is the target pinging frequency for node i, s is the size of the ping packet, q is the expected number of ping packets in a probe before the probe either successfully elicits a response or is unsuccessful, TB is the target bandwidth constraint, li is the estimated lifetime of node i, and N is the total number of nodes in the fail-detect set. The details of the analysis, as well as the closed-form equation for bandwidth-minimizing failure detectors, can be found in our papers.
The
Overall, the Sqrt-SComputer Science Department
|