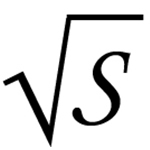
|
Optimal Failure Detector |
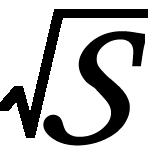 is an optimal
implementation of a multi-node failure detector,
where the detector is tasked with monitoring a set of N other nodes.
It has two modes of operation.
In latency-minimizing mode, it takes as input an amount of bandwidth to spend on failure detection, and pings the monitored nodes at just the right frequency such that it will detect failures as early as possible without exceeding the given bandwidth cap.
In bandwidth-minimizing mode, it takes as input a target failure detection latency, and pings the monitored nodes at just the right frequency such that it will detect failures within the targeted amount of detection latency using the minimal required amount of bandwidth.
The novelty of our failure detector lies in its use of an analytically
derived equation for determing the optimal pinging schedule to achieve
the desired performance goal. is an optimal
implementation of a multi-node failure detector,
where the detector is tasked with monitoring a set of N other nodes.
It has two modes of operation.
In latency-minimizing mode, it takes as input an amount of bandwidth to spend on failure detection, and pings the monitored nodes at just the right frequency such that it will detect failures as early as possible without exceeding the given bandwidth cap.
In bandwidth-minimizing mode, it takes as input a target failure detection latency, and pings the monitored nodes at just the right frequency such that it will detect failures within the targeted amount of detection latency using the minimal required amount of bandwidth.
The novelty of our failure detector lies in its use of an analytically
derived equation for determing the optimal pinging schedule to achieve
the desired performance goal.
is particularly suitable for systems where a node is tasked with monitoring the liveness status of a
large number of other nodes, such as peer-to-peer systems. While the derivation of the optimal schedule
is lengthy, the end-result is a closed form formula that is cheap to
evaluate. This yields a practical, simple implementation. We provide
an open-source implementation in Java and Python.
|
