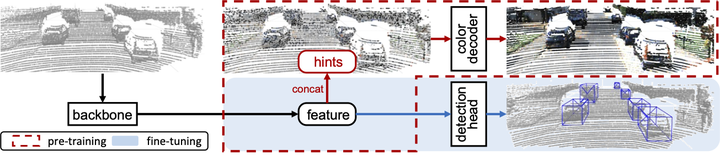
 Architecture of GPC. The key insight is grounding the pre-training colorization process on the hints, allowing the model backbone to focus on learning semantically meaningful representations that indicate which subsets (i.e., segments) of points should be colored similarly to facilitate downstream 3D object detection.
Architecture of GPC. The key insight is grounding the pre-training colorization process on the hints, allowing the model backbone to focus on learning semantically meaningful representations that indicate which subsets (i.e., segments) of points should be colored similarly to facilitate downstream 3D object detection.
Abstract
Accurate 3D object detection and understanding for self-driving cars heavily relies on LiDAR point clouds, necessitating large amounts of labeled data to train. In this work, we introduce an innovative pre-training approach, Grounded Point Colorization (GPC), to bridge the gap between data and labels by teaching the model to colorize LiDAR point clouds, equipping it with valuable semantic cues. To tackle challenges arising from color variations and selection bias, we incorporate color as “context” by providing ground-truth colors as hints during colorization. Experimental results on the KITTI and Waymo datasets demonstrate GPC’s remarkable effectiveness. Even with limited labeled data, GPC significantly improves fine-tuning performance; notably, on just 20% of the KITTI dataset, GPC outperforms training from scratch with the entire dataset. In sum, we introduce a fresh perspective on pre-training for 3D object detection, aligning the objective with the model’s intended role and ultimately advancing the accuracy and efficiency of 3D object detection for autonomous vehicles.