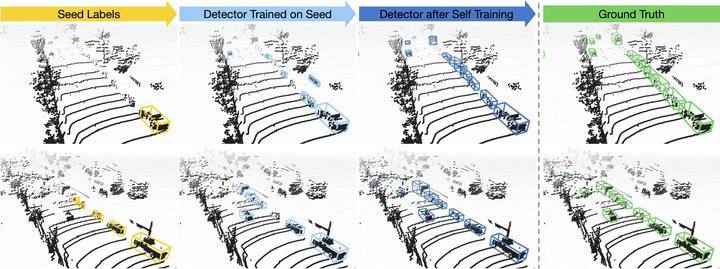
 Visualizations of MODEST outputs. We show LiDAR scans from two scenes in the Lyft dataset in two rows. From zero labels, our method is able to bootstrap a detector that achieves results close to the ground truth.
Visualizations of MODEST outputs. We show LiDAR scans from two scenes in the Lyft dataset in two rows. From zero labels, our method is able to bootstrap a detector that achieves results close to the ground truth.
Abstract
Current 3D object detectors for autonomous driving are almost entirely trained on human-annotated data. Although of high quality, the generation of such data is laborious and costly, restricting them to a few specific locations and object types. This paper proposes an alternative approach entirely based on unlabeled data, which can be collected cheaply and in abundance almost everywhere on earth. Our approach leverages several simple common sense heuristics to create an initial set of approximate seed labels. For example, relevant traffic participants are generally not persistent across multiple traversals of the same route, do not fly, and are never under ground. We demonstrate that these seed labels are highly effective to bootstrap a surprisingly accurate detector through repeated self-training without a single human annotated label. Code is available at https://github.com/YurongYou/MODEST.