| Main | Download | Approach | Papers | Support | Press | People |
Approach
Keyword Space
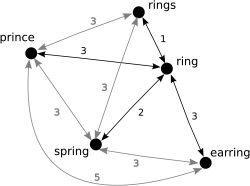
Figure 1: The edit-distance between keywords. The five keywords create a keyword space that cannot be accurately embedded into a plane.
Cubit uses the most common notion of distance on strings, the edit-distance. It is equal to the minimum number of insertions, deletions and substitutions needed to transform one string to another. The keywords then lie in the keyword space, illustrated in Figure 1, a metric space induced on keywords by the edit-distance.
Node ID Assignment
Cubit nodes are distributed in the same space as keywords. Each node in Cubit is assigned a unique string ID chosen from the set of keywords associated with previously inserted objects in the system. Specifically, at join time each node independently selects a random keyword, ensuring uniqueness by detecting ID collisions. The ID of a node determines its "position" in the keyword space. This position determines how a given node is used in Cubit. First, each Cubit node is responsible for storing the set of keywords for which it is the closest node. Second, Cubit implements a distributed protocol which navigates through nodes in the keyword space, gradually zooming in on a neighborhood of a given (possibly misspelled) keyword, and thus locates nodes that store possible matches.
Navigation
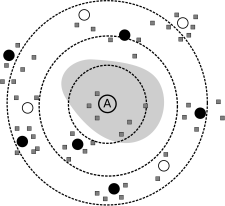
Figure 2: In this example, the solid circles represent peers in node A's peer-set, the empty circles represent other peers, and the squares represent object keywords in the system. The shaded region depicts the sub-space that is closer to A than any other node.
The desired property of the search protocol is to obtain the k closest objects to the set of keywords, as measured by the phrase distance metric. For each keyword in the search phrase, the protocol obtains the k closest objects from each node which meets the following edit distance criterion: its ID is within an edit-distance of q from the keyword, where q is the product of the keyword length and the expected number of perturbations per character (which is a parameter in the system). The protocol selects m closest nodes if fewer than m nodes meet edit-distance criterion, where m is called the search fan-out. The keyword search protocol is illustrated in Figure 3.
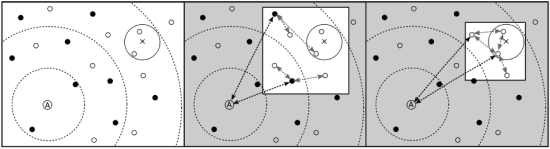
Figure 3: The Cubit search protocol operates iteratively to collect more and more information of the target region. In this example, x is the location of the search term in the keyword space, the solid circles are node A's peers, empty circles are additional nodes in the space, and the circle around x are all nodes within edit-distance q of x. Node A first finds the m = 2 closest nodes to x from its peer-set, and request their m closest nodes. In this example, two new closer nodes are discovered and subsequently sent the same query. The protocol terminates when all nodes within the circle around x, or the m closest nodes have been discovered. These nodes are queried for their closest objects to x.
Load Balancing
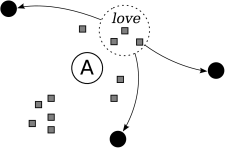
Figure 4: In this example, the keyword "love" is closest to node A and is generating a high degree of load. Node A creates a virtual node centered around the keyword love, which includes its leaf set and all objects in the region within p edit-distance from love. This virtual node is sent to A's nearest neighbors. Queries that arrive at these neighbors for keywords within an edit-distance p of love can be answered without node A.
In Cubit, if the load generated by queries for a popular keyword w overwhelms the available resources of node i, the node can send an off-loading request to its closest neighbors requesting them to create a synthetic node located at w. Nodes receiving such a request create a synthetic node at w whose IP address and port correspond to their own, thus enabling queries for that portion of the keyword space to be terminated at any one of the moff neighbors. The original requester is then tasked with keeping the virtual nodes updated with changes to objects in the off-loaded region as well as changes to its leaf-set. This off-loading operation disperses hot-spots in keyword popularity without requiring global information or coordination. Figure 4 illustrates the protocol.