Chapter 12
Voting: Barriers and Ways around Them
In this chapter, we continue our exploration of voting: we present a fundamental barrier to strategy-proof voting (the Gibbard–Satterthwaite theorem), and next exemplify some ways to circumvent this barrier.
12.1 The Gibbard–Satterthwaite Theorem
Roughly speaking, the Gibbard-Satterthwaite theorem shows that if we restrict to voting rules that are onto—where all candidates can win—then the only strategy-proof voting rule over three or more candidates is “dictatorship.”
We start by formalizing what it means for a voting rule to be onto (i.e., that it is feasible for every candidate to be able to win):
Definition 12.1. Given a complete social-choice context , we say a voting rule is onto if for every candidate , there exists some preference profile such that .
Let us turn to defining what it means for a voting rule to be dictatorial.
Definition 12.2. Given a complete social-choice context , we say that a voter is a dictator for with respect to if for every such that ranks first. We say that is simply a dictator for if for every , is a dictator for with respect to . We finally call a voting rule dictatorial if there exists some voter such that is a dictator for .
A useful property of the notion of dictatorship is that if a voter is a dictator for some candidate , then no other voter can be a dictator for some other candidate (since the situation where ranks first and ranks first would lead to a conflict).
Note that any dictatorial voting rule clearly is onto and strategy-proof. The Gibbard–Satterthwaite theorem shows a surprising converse of this observation:
Theorem 12.1 (The Gibbard–Satterthwaite theorem). Let be a voting rule that is onto and strategy-proof for some complete social-choice context with strict preferences over at least three outcomes. Then is a dictatorial.
Note that a direct corollary of this theorem is that voting rules for social-choice contexts with strict preferences, in general, we cannot DST-implement social value maximization (since for most social-choice contexts, dictatorship clearly will not implement social value maximization; we leave it as an exercise to prove this).
12.2 Proof of the Gibbard–Satterthwaite Theorem [Advanced]
For simplicity of notation, in the remainder of this section, we always have some fixed complete social-choice context over at least three outcomes and with strict preferences, in mind (and as such, whenever we write strategy-proof, or onto, we mean with respect to this social-choice context). Before turning to the actual proof, let us first demonstrate that strategy-proof voting rules satisfy two natural properties that we would expect from any “reasonable” voting rule.
Definition 12.3. A voting rule is monotone if for every two preference profiles and , if , and for every player and every candidate such that it is also true that , it follows that .
In other words, if a voting rule is monotone, then a winning candidate will continue to win as long as, for any player , all candidates that are dominated by continue being dominated by .
Definition 12.4. A voting rule is Pareto-optimal if for every profile and candidate such that for every player , we have that .
In other words, if a voting rule is Pareto-optimal, then no candidate , that is dominated by some candidate in every player’s preference ordering, can ever win. In particular, if a candidate is preferred by all players, that candidate must win.
The following two lemmas state that strategy-proof voting rules are both monotone and Pareto-optimal.
Lemma 12.1. Any strategy-proof voting rule is monotone.
Proof. Assume for contradiction that is not monotone; then, there exist profiles of preferences and so that and for every player and every candidate such that it is also true that , and yet .
We construct a sequence of “hybrid” preferences where we move from to one player at a time:
- if , and
- if .
(See Figure 12.1 for an illustration of the hybrid preference profiles.) Thus, and . Now let denote the smallest index where but . Clearly such an index must exist, since by assumption.
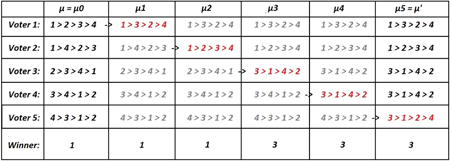
Figure 12.1: An example of the hybrid preference profiles in the proof of Lemma 12.1. In this case, we can see that the winner does change between and , despite the fact that every player who prefers 1 to any other candidate in still prefers 1 to the same candidates in . The example shows that the voting rule (here, plurality with ties broken by largest candidate number) is not monotone and hence not strategy-proof.
Furthermore, note that the only difference between and is that player is switching from to . Since is strategy-proof, we must have that , or else, given the preference profile , player would prefer to report , which would lead to the outcome that they strictly prefer to (by our assumption that preferences are strict). Since by the choice of , we have that for every player and every choice , if then , it follows that .
But, by the same argument, we have that (or else player would prefer to report given the preference profile ); this is a contradiction (since preferences are strict).
■
Lemma 12.2. Any strategy-proof and onto voting rule is Pareto-optimal.
Proof. Assume for the sake of contradiction that there exists some preference profile and some candidate such that for every player , yet . Now:
- Let be a modified version of where candidates are “pushed-up” so that is every player’s first choice and is every player’s second choice. (For instance, if we have two voters with preferences and in , respectively, their preferences in will become and .) By monotonicity, we must still have that (since all candidates dominated by still are dominated by it).
- Since is onto, there must exist some preference profile such that . Let be the modified version of where and are “pushed-up” in the same way as before. Again, by monotonicity, we have .
- Finally, by monotonicity applied to the transition from to , it follows that , since we are only moving around candidates that are dominated by (and )).
The conclusion of bullet 3 (i.e., that ) contradicts the conclusion of bullet 1 (i.e., that ), which concludes the proof of the lemma.
■
We are now ready to prove the Gibbard–Satterthwaite theorem.
Proof of the Gibbard–Satterthwaite theorem. First, note that the theorem for the case that directly follows from Pareto-optimality of . We next prove the theorem for the case that , and then proceed to prove the general case by induction.
The special case of 2 voters () Toward proving the theorem for the special case of 2 votes, let us first prove the following easier claim.
Claim 12.1. Consider some strategy-proof and onto voting rule for two voters, and any ordered pair of candidates where . Then, either player 1 is a dictator for with respect to , or player 2 is a dictator for with respect to .
Proof. Consider any two candidates and in . Let profile be some arbitrary ranking where is first and is second, and let be the same ranking except that we switch the order of and . (For instance, if we let be , then becomes .) Note that by Pareto-optimality either or must win the election (i.e., ), since all other candidates are dominated by both and for both players. Let us first consider the case that wins (i.e., ).
Now consider a new profile of rankings where is identical to except is ranked last for player 2. (For instance, in the example above, becomes .)
- By Pareto-optimality, we still have that either or must win, since all other candidates are still dominated by .
- However, by strategy-proofness, cannot win now, since in this case player 2 would have preferred to report in the original profile (where wins but player 2 prefers ).
- So, must still be winning with respect to the new profile .
- By monotonicity (transitioning from to ) it follows that for every profile of rankings where player 1 ranks on top, since in any such ranking still dominates all other candidates for player 1 (and monotonicity holds vacuously for player 2, since dominates no other candidate in ).
Thus, we conclude that player 1 is a dictator for with respect to . Symmetrically, in the case that , player 2 is a dictator for .
■
Now we can apply this claim to three candidates.
Claim 12.2. Consider some strategy-proof and onto voting rule for two voters. Given any set of candidates , we have that either player 1 or player 2 is a dictator for all three candidates with respect to .
Proof. We simply apply Claim 12.1 to different subsets of the three candidates:
- Applying Claim 12.1 to the pair , we get that either 1 is a dictator for or 2 is a dictator for . Assume, for now, that the first case holds (i.e., 1 is a dictator for ).
- Next, applying Claim 12.1 to the pair , we get that either 1 is a dictator for or 2 is a dictator for . But since we already assumed that 1 is a dictator for , 2 cannot be a dictator for (or else we would get a conflict in the definition of , as noted above). Hence, 1 must be a dictator for both and .
- Finally, applying Claim 12.1 to the pair , we get that either 1 is a dictator for or 2 is a dictator for . Again, 2 cannot be dictator for since we have shown that 1 is a dictator ; thus, 1 must also be a dictator for .
- We thus conclude that 1 is a dictator for all three candidates. By symmetry, if the second case held initially (i.e., player 2 was a dictator for ), player 2 would become a dictator for all candidates.
This concludes the proof of the claim.
■
We can finally conclude the proof of the theorem for the case that by applying Claim 12.2 to all triples , , and again observing that since 1 and 2 cannot simultaneously be dictators for both and , one of the players must be a dictator for every candidate.
The general case () Next, to prove the theorem for any number of voters, we proceed by induction. The base case () has already been proven above. For the induction step, assume that the theorem is true for voters; we shall prove it holds for voters. Assume for contradiction that this is not the case. That is, there exists some onto and strategy-proof voting rule with voters that is not dictatorial.
Let be a preference ordering where is ranked highest and all other candidates are ranked according to a lexicographic order, and define an -player voting rule, which simply runs but fixes the first player’s vote to ; that is,
First, note that since is strategy-proof, we have that for every candidate , is strategy-proof. Next, as we show below, also is onto. (Looking forward, we will then use the induction hypothesis to conclude that —which has voters—is dictatorial, and then use this fact to conclude that also must be dictatorial.)
Claim 12.3. For every , we have that is onto.
Proof. Toward showing this claim, consider a different voting rule for just 2 voters:
(That is, the 2-party voting rule repeats player 2’s vote times and next runs .) Note that must be onto, since for every ,
due to the fact that satisfies Pareto-optimality. Since is strategy-proof, must be strategy-proof for player 1; by the following argument, it must also be so for player 2:
- Assume for contradiction that is not strategy-proof for player 2; then there exists such that .
- Now, consider and switch one player at a time from to until we arrive at ; let , where denote the such “hybrid” preference profile.
- Since , there must exist some such that
and thus also
which contradicts strategy-proofness for player with respect to .
So (by the already proven base case) must be dictatorial. If player 1 is a dictator for , then, by monotonicity, it follows that 1 must be a dictator also for , which is a contradiction (since we assumed that was not dictatorial). Thus, player 2 must be the dictator for ; in other words, for every , and every preference ordering , it holds that
In particular, it holds that
so we conclude that is onto.
■
Thus, we have shown that for every , is both onto and strategy-proof. By the inductive hypothesis it thus follows that for every , (having participating voters) is dictatorial. This does not directly give us that also is dictatorial (which would conclude the proof) since apriori, there may exist , such that has a different dictator (say ) than has (say ). However, as we now show, if that were to happen, could not be strategy-proof for player .
Consider the preference profile where player has preferences (i.e., ranks highest) and all other players have preferences . If everyone votes truthfully, since player 1’s preferences are , the outcome will be
since is a dictator for , and chooses . If player 1, however, had misreported their preferences and instead reported , then the outcome would be since is a dictator and chooses . So player 1 prefers to misreport their preferences (reporting as opposed to ) and thus is not strategy-proof, which is a contradiction.
We conclude that there exists a single player such that for every , player is a dictator for , and thus player is a dictator also for ; this concludes the proof.
■
12.3 Single-peaked Preferences and the Median Voter Theorem
The above impossibility result (i.e., the Gibbard–Satterthwaite theorem) relies on the fact that voters’ preferences over candidates can be arbitrary. In other words, it relies on the fact that the social-choice context is complete. Under a natural restriction on the preferences, it can be overcome. In fact, as it turns out, under the same restriction, we can also overcome the impossibility of Condorcet voting.
Roughly speaking, we say that preferences are single-peaked if all candidates can be placed on a one-dimensional spectrum (e.g., think of the American political spectrum in terms of liberal/left and conservative/right), and voters’ valuations for candidates strictly decrease based on how far they are to the left or right of their “ideal outcome” on the spectrum—that is, the valuation decreases with distance to some ideal point, but might decrease differently depending on whether it is to the left or right of that point. See Figure 12.2 for an illustration.

Figure 12.2: An illustration of the intuition behind single-peaked preferences. In this example, seven candidates are arranged on a spectrum. We can imagine the voter’s preferences as a function over this spectrum; the only requirements for this function are that it must be maximized at the voter’s top choice (in this case, 3), and strictly decreasing as distance from that choice increases. In the first example (left), the preference diminishes directly with distance; in the second example (right), it does not, which preserves the voter’s top choice but changes the order of preferences. In fact, any preference where and is admissible as single-peaked.
More formally, we say that a social-choice context has single-peaked preferences if (a) has strict preferences, and (b) there exists some “global” ordering over the candidates in such that for each player , the type set is the set of preferences for which there exists some “ideal candidate” such that for all :
- if , then ;
- if , then .
The celebrated median voter theorem by Black [Bla48] shows that once we restrict to social-choice contexts with single-peaked preferences, a Condorcet winner always exists—in fact, the preferred choice of the so-called “median voter” will be a Condorcet winner. We additionally remark that this median-voter mechanism is also strategy-proof:
Theorem 12.2 (The median voter theorem). There exists a strategy-proof voting rule for all single-peaked social-choice contexts; furthermore, will always select a Condorcet winner for all single-peaked social-choice contexts.
Proof. For simplicity, let us begin by assuming an odd number of voters. Let denote the top choices of each voter’s reported preferences, ordered according to the one-dimensional spectrum. Let output (i.e., the preference of the median voter according to the spectrum). See Figure 12.3 for an example.
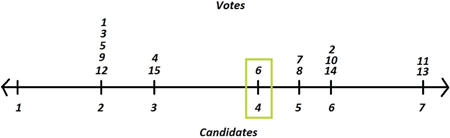
Figure 12.3: An example of the median voter rule with 15 voters and the seven candidates from the previous figure. If we order the 15 votes according to their positions on the spectrum, voter 6 is the median (eighth) vote, and so his candidate (4) wins, despite candidate 2 having a plurality of the votes. This rule is strategy-proof assuming single-peaked preferences, but may still leave a lot of voters unhappy and definitely does not maximize social welfare. (Exercise: Try to come up with a preference function for each voter to show this.)
produces a Condorcet winner Consider any alternative candidate such that (i.e., is to the “left” of on the spectrum). All voters including, and to the right of, must prefer to , by the single-peaked preferences requirement. Symmetrically, if is to the “right” of , then all voters including, and to the left of, must prefer to . So at least voters prefer to any other candidate, and so is a Condorcet winner.
is strategy-proof Clearly, the median voter is not incentivized to report his preference falsely, as they are receiving optimal utility (their top choice) by reporting truthfully. Voters to the left of the median cannot change the median by deviating, except by pushing it to the right by voting for a candidate to the right (and thus losing utility by the single-peaked preference rule); symmetrically, voters to the right can only push the median to the left by deviating (and again lose utility). Thus, the voting rule is strategy-proof.
Dealing with even Now, if is even, we can just take the median vote to be . We still have that is strategy-proof by the same logic as above. In addition, will still output a Condorcet winner; will be preferred to an alternative candidate to the left by voters (all voters including and to the right of ), and will be preferred to an alternative candidate to the right by at least voters (all voters including and to the left of ).
■
Notice that in case is odd, the above proof shows that there is a unique Condorcet winner, whereas when is even, there can be at most 2 ( and ).
12.4 Voting with Payments
Finally, let us revisit the question of designing mechanisms for social-choice contexts, but this time allowing for payments—that is, the mechanism can now charge players based on how they vote. For concreteness, consider again a specific social-choice context with two players (voters) and where the set of outcomes is ; recall that a mechanism for this social-choice context needs to output a winning candidate and prices for the voters to pay. There are just two types of players , and ; let the valuations for the players be such that player 1 (having type ) gets utility 10 if gets elected, and 0 if gets elected, whereas player 2 (having type ) gets utility if gets elected and if .1 (This example is essentially isomorphic to the airport vs. train station example from chapter 10, but using a different type space.)
Consider applying the VCG mechanism (with the Clarke pivot rule) to this context. The outcome maximizing social value is winning (with a social value of as opposed to for winning); thus, the VCG mechanism will pick this outcome assuming players truthfully report their types. Now, consider the externality of each player. If player 1 were not voting, would win and player 2 would receive 6 in utility; however, with player 1 voting and winning, player 2 only receives 4. Hence, player 1’s externality is 2. Player 2’s externality is 0, since the outcome is the same for player 1 regardless of whether player 2 votes or not. So in this case, player 1 would be charged a price of 2 by the VCG mechanism with the Clarke pivot rule, whereas player 2 would not be charged anything.
One interesting thing to note about this mechanism is that only a “pivotal player” who can actually change the outcome of the election has to pay anything (in the example above, player 1); they, in addition, never need to pay more than their difference in value between the two candidates.
Knowledge of valuations Note that to apply the VCG mechanism to a social-choice context, the mechanism needs to know by how much each player values their respective candidate (i.e., the the mechanism needs to know the utility function)—this is needed since the players’ types (that they report to the mechanism) are simply a ranked list of candidates. It is not clear how the voting authority (running the VCG mechanism) can obtain these valuations in a reliable way.
But there is an easy fix: just as we did in the airport vs. train station example in chapter 10, let us consider a more general mechanism design context for social choice where a player’s type not only specifies a preference order, but also specifies how valuable each candidate is to the player! We can still apply the VCG mechanism to such a context, and the result would be that players now are incentivized to truthfully report exactly how valuable each candidate is to them (and we would still recover the same outcome described above, except that now player 1 would report and player 2 would report ).
So, we have a practical mechanism that enables us to elect a candidate that maximizes social value. Why aren’t all the countries in the world switching to using this VCG mechanism? We highlight a few answers (think about others yourself!):
- As already mentioned, in the context of voting, maximizing social value may not be the “right” desiderata: a richer player may have more to gain/lose from the outcome of the election, and such a player’s preferences will receive a heavier weight. This, intuitively, seems unfair and undesirable.
- But even if we decide that social value maximization is what we want to achieve, there is a problem with running this mechanism in an uncontrolled environment: collusion. Consider a scenario with 100 voters, 98 of whom prefer , but the other two of them want to bias the election so that wins and they do not have to pay anything. Let us say that they both decide to bid an outrageous sum of money (say, 10 billion dollars), equal to far more than the combined sum of the supporters valuations. Clearly, if either one of them were to not vote, the outcome of the election would be , so, neither of them has any externality, and they would thus pay nothing! This is an example of how collusion between players breaks the truthfulness of the VCG mechanism. (We mention that the same problem occurs also in the case of auctions, which is why there are regulations against collusion when running, for example, spectral auctions.)
12.5 Summarizing the Voting Landscape
Let us informally summarize the key feasibility and infeasibility results obtained for strategy-proof voting:
- For the case of 2 candidates, there exists a strategy-proof voting rule that always selects a Condorcet winner: in fact, the most natural rule—plurality—of selecting the candidate with the most number of top-choice votes works.
- For the case of 3 or more candidates, the only strategy-proof voting rule is dictatorship (as shown by the Gibbard–Satterthwaite theorem), and no voting rule can always elect a Condorcet winner.
- But with restricted preferences (single-peaked ones, where the candidates can be placed on a one-dimensional spectrum), a natural voting rule (selecting the median voter’s top choice) is both strategy-proof and always selects a Condorcet winner.
- Finally, with payments, DST voting maximizing social value is possible (but the mechanism is vulnerable to attacks by collusion between two or more voters).
Notes
The Gibbard–Satterthwaite theorem was first proved in [Gib73, Sat75]; this result is closely related to an earlier impossibility result by Kenneth Arrow [Arr50], demonstrating that a different set of desirable properties for voting rules are inconsistent; Arrow received the Nobel Prize in Economic Sciences in 1972.
Our proof of the Gibbard–Satterthwaite theorem is new but follows high-level ideas from the proofs in [SR14] and [BP90]. Single-peaked preferences and the median voter theorem are due to Black [Bla48].
The Gibbard–Satterthwaite theorem can be extended in various ways. First, the theorem only talks about deterministic voting rules, but as shown by Gibbard [Gib77] it can also be extended to randomized ones. Additionally, the notion of strategy-proofness is quite strong as it requires an implementation in dominant strategies (that is, truthfully reporting your preferences is always a best response, no matter what the other players do). As mentioned in the previous chapters, a weaker form of truthful implementation is that of Bayes–Nash truthful implementation; in the context of voting, the notion of “Bayes–Nash strategy-proofness” would require that truthfully reporting your preferences maximizes expected utility assuming everyone else reports their true preferences, where the expected utility is computed assuming all other players’ types are independently drawn from some distribution —this distribution describes how players believe others will vote (e.g., could be obtained from polling). Unfortunately, as shown by McLennan [McL11], the Gibbard–Satterthwaite theorem actually extends also to this setting! However, as shown in [LLP15], McLennan’s result requires Bayes–Nash strategy-proofness to hold with respect to all distributions , even those that are very “complicated” in the sense that they require high precision (i.e., a large number of decimal points) to describe the probabilities assigned to various candidates. In contrast, [LLP15] demonstrates natural voting rules that satisfy Bayes–Nash strategy-proofness with respect to distributions , where only a small number of decimal points are used to describe probabilities (i.e., when players’ beliefs are “coarse” as one would expect them to be).
1Formally, player 1’s utility function is such that the player gets 10 in utility if their top choice wins (according to the player’s type) and 0 otherwise, whereas player 2’s utility is such that they get 6 if their top choice wins, and 4 otherwise.