![]()
![]()
![]()
Graphics

In this paper, we accelerate self-collision detection (SCD) for a deforming triangle mesh by exploiting the idea that a mesh cannot self collide unless it deforms enough. Unlike prior work on subspace self-collision culling which is restricted to low-rank deformation subspaces, our energy-based approach supports arbitrary mesh deformations while still being fast. Given a bounding volume hierarchy (BVH) for a triangle mesh, we precompute Energy-based Self-Collision Culling (ESCC) certificates on bounding-volume-related sub-meshes which indicate the amount of deformation energy required for it to self collide. After updating energy values at runtime, many bounding-volume self-collision queries can be culled using the ESCC certificates. We propose an affine-frame Laplacian-based energy definition which sports a highly optimized certificate preprocess, and fast runtime energy evaluation. The latter is performed hierarchically to amortize Laplacian energy and affine-frame estimation computations. ESCC supports both discrete and continuous SCD, detailed and nonsmooth geometry. We demonstrate significant culling on various examples, with SCD speed-ups up to 26X.
Changxi Zheng and Doug L. James,
Energy-based Self-Collision Culling for Arbitrary Mesh Deformations.
To appear in ACM Transaction on Graphics (SIGGRAPH 2012)
[Paper(PDF)], [Project Page]
To appear in ACM Transaction on Graphics (SIGGRAPH 2012)
[Paper(PDF)], [Project Page]

We introduce an efficient method for synthesizing acceleration noise due to rigid-body collisions using standard data provided by rigid-body solvers. We accomplish this in two main steps. First, we estimate continuous contact force profiles from rigid-body impulses using a simple model based on Hertz contact theory. Next, we compute solutions to the acoustic wave equation due to short acceleration pulses in each rigid-body degree of freedom. We introduce an efficient representation for these solutions - Precomputed Acceleration Noise - which allows us to accurately estimate sound due to arbitrary rigid-body accelerations. We find that the addition of acceleration noise significantly complements the standard modal sound algorithm, especially for small objects.
Jeffery Chadwick, Changxi Zheng and Doug L. James,
Precomputed Acceleration Noise for Improved Rigid-body Sound.
To appear in ACM Transaction on Graphics (SIGGRAPH 2012)
[Paper(PDF)], [Project Page]
To appear in ACM Transaction on Graphics (SIGGRAPH 2012)
[Paper(PDF)], [Project Page]

Contact sound models based on linear modal analysis are commonly used with rigid body dynamics. Unfortunately, treating vibrating objects as "rigid" during collision and contact processing fundamentally limits the range of sounds that can be computed, and contact solvers for rigid body animation can be ill-suited for modal contact sound synthesis, producing various sound artifacts. In this paper, we resolve modal vibrations in both collision and frictional contact processing stages, thereby enabling non-rigid sound phenomena such as micro-collisions, vibrational energy exchange, and chattering. We propose a frictional multibody contact formulation and modified Staggered Projections solver which is well-suited to sound rendering and avoids noise artifacts associated with spatial and temporal contact-force fluctuations which plague prior methods. To enable practical animation and sound synthesis of numerous bodies with many coupled modes, we propose a novel asynchronous integrator with model-level adaptivity built into the frictional contact solver. Vibrational contact damping is modeled to approximate contact-dependent sound dissipation. Results are provided that demonstrate high-quality contact resolution with sound.
Changxi Zheng and Doug L. James,
Toward High-Quality Modal Contact Sound.
ACM Transaction on Graphics (SIGGRAPH 2011), 30(4), August, 2011
[Paper(PDF)], [Project Page]
[Paper(PDF)], [Project Page]

We propose a physically based algorithm for synthesizing sounds synchronized with brittle fracture animations. Motivated by laboratory experiments, we approximate brittle fracture sounds using time-varying rigid-body sound models. We extend methods for fracturing rigid materials by proposing a fast quasistatic stress solver to resolve near-audio-rate fracture events, energy-based fracture pattern modeling and estimation of "crack"-related fracture impulses. Multipole radiation models provide scalable sound radiation for complex debris and level of detail control. To reduce soundmodel generation costs for complex fracture debris, we propose Precomputed Rigid-Body Soundbanks comprised of precomputed ellipsoidal sound proxies. Examples and experiments are presented that demonstrate plausible and affordable brittle fracture sounds.
Changxi Zheng and Doug L. James,
Rigid-Body Fracture Sound with Precomputed Soundbanks.
ACM Transaction on Graphics (SIGGRAPH 2010), 29(3), July, 2010
[Paper(PDF)], [Project Page]
[Paper(PDF)], [Project Page]

Fluid sounds, such as splashing and pouring, are ubiquitous and familiar but we lack physically based algorithms to synthesize them in computer animation or interactive virtual environments. We propose a practical method for automatic procedural synthesis of synchronized harmonic bubble-based sounds from 3D fluid animations. To avoid audio-rate time-stepping of compressible fluids, we acoustically augment existing incompressible fluid solvers with particle-based models for bubble creation, vibration, advection, and radiation. Sound radiation from harmonic fluid vibrations is modeled using a time-varying linear superposition of bubble oscillators. We weight each oscillator by its bubble-to-ear acoustic transfer function, which is modeled as a discrete Green's function of the Helmholtz equation. To solve potentially millions of 3D Helmholtz problems, we propose a fast dual-domain multipole boundary-integral solver, with cost linear in the complexity of the fluid domain's boundary. Enhancements are proposed for robust evaluation, noise elimination, acceleration, and parallelization. Examples of harmonic fluid sounds are provided for water drops, pouring, babbling, and splashing phenomena, often with thousands of acoustic bubbles, and hundreds of thousands of transfer function solves.
Changxi Zheng and Doug L. James,
Harmonic Fluids.
ACM Transaction on Graphics (SIGGRAPH 2009), 28(3), August, 2009
[Paper(PDF)], [Project Page]
Harmonic Fluid Sound Synthesis. Computer Animation Festival, SIGGRAPH 2009
[Paper(PDF)], [Project Page]
Harmonic Fluid Sound Synthesis. Computer Animation Festival, SIGGRAPH 2009
Robotics

Placing is a necessary skill for a personal robot to have in order to perform tasks such as arranging objects in a disorganized room. The object placements should not only be stable but also be in their semantically preferred placing areas and orientations. This is challenging because an environment can have a large variety of objects and placing areas that may not have been seen by the robot before.
In this paper, we propose a learning approach for placing multiple objects in different placing areas in a scene. Given point-clouds of the objects and the scene, we design appropriate features and use a graphical model to encode various properties, such as the stacking of objects, stability, object-area relationship and common placing constraints. The inference in our model is an integer linear program, which we solve efficiently via an LP relaxation. We extensively evaluate our approach on 98 objects from 16 categories being placed into 40 areas. Our robotic experiments show a success rate of 98% in placing known objects and 82% in placing new objects stably. We use our method on our robots for performing tasks such as loading several dish-racks, a bookshelf and a fridge with multiple items
Yun Jiang, Marcus Lim, Changxi Zheng and Ashutosh Saxena,
Learning to Place New Objects in a Scene.
To appear in International Journal of Robotics Research (IJRR), 2012
[Paper(PDF)], [Project Page]
[Paper(PDF)], [Project Page]

The ability to place objects in an environment is an important skill for a personal robot. An object should not only be placed stably, but should also be placed in its preferred location/orientation. For instance, a plate is preferred to be inserted vertically into the slot of a dish-rack as compared to be placed horizontally in it. Unstructured environments such as homes have a large variety of object types as well as of placing areas. Therefore our algorithms should be able to handle placing new object types and new placing areas. These reasons make placing a challenging manipulation task.
In this work, we propose a supervised learning algorithm for finding good placements given the point-clouds of the object and the placing area. It learns to combine the features that capture support, stability and preferred placements using a shared sparsity structure in the parameters. Even when neither the object nor the placing area is seen previously in the training set, our algorithm predicts good placements. In extensive experiments, our method enables the robot to stably place several new objects in several new placing areas with 98% success-rate; and it placed the objects in their preferred placements in 92% of the cases.
» Yun Jiang, Changxi Zheng, Marcus Lim and Ashutosh Saxena,
Learning to Place New Objects. To appear in IEEE Intl. Conference on Robotics and Automation (ICRA), 2012
[Paper(PDF)],
[Project Page]
» Yun Jiang, Changxi Zheng, Marcus Lim and Ashutosh Saxena, Learning to Place New Objects. RSS workshop on mobile manipulation, June 2011
[Paper(PDF)], [Project Page]
» Yun Jiang, Changxi Zheng, Marcus Lim and Ashutosh Saxena, Learning to Place New Objects. RSS workshop on mobile manipulation, June 2011
[Paper(PDF)], [Project Page]
Applied Mathematics
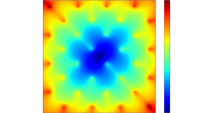
Alexander Vladimirsky and Changxi Zheng,
A fast implicit method for time-dependent Hamilton-Jacobi PDEs.
under revision to SIAM Journal on Scientific Computing. (authors listed in alphabetical order)
preprint coming out soon
preprint coming out soon
Networking
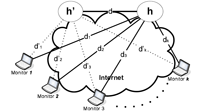
As more and more Internet IP prefix hijacking incidents are being reported, the value of hijacking detection services has become evident. Most of the current hijacking detection approaches monitor IP prefixes on the control plane and detect inconsistencies in route advertisements and route qualities. We propose a different approach that utilizes information collected mostly from the data plane. Our method is motivated by two key observations: when a prefix is not hijacked, 1) the hop count of the path from a source to this prefix is generally stable; and 2) the path from a source to this prefix is almost always a super-path of the path from the same source to a reference point along the previous path, as long as the reference point is topologically close to the prefix. By carefully selecting multiple vantage points and monitoring from these vantage points for any departure from these two observations, our method is able to detect prefix hijacking with high accuracy in a light-weight, distributed, and real-time fashion. Through simulations constructed based on real Internet measurement traces, we demonstrate that our scheme is accurate with both false positive and false negative ratios below 5%.
Changxi Zheng, Lusheng Ji, Dan Pei, Jia Wang and Paul Francis, A Light-Weight Distributed Scheme for Detecting IP Prefix Hijacks in Real-time.
Proc. of ACM SIGCOMM, Kyoto, Japan, August, 2007
Proc. of ACM SIGCOMM, Kyoto, Japan, August, 2007
Earlier Papers
- Guobin Shen, Changxi Zheng, Wei Pu and Shipeng Li, Distributed Segment Tree: A Unified Architecture to Support Range Query and Cover Query. Technical Report MSR-TR-2007-30, 2007
- Changxi Zheng, Guobin Shen, Shipeng Li, and Scott Shenker, Distributed Segment Tree: Support of Range Query and Cover Query over DHT. The 5th International Workshop on Peer-to-Peer Systems (IPTPS) Santa Barbara, US, February, 2006
- Ke Liang, Zaoyang Gong, Changxi Zheng, and Guobin Shen, MOVIF: A Lower Power Consumption Live Video Multicasting Framework over Ad-hoc Networks with Terminal Collaboration . International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hong Kong, December, 2005
- Changxi Zheng, Guobin Shen, and Shipeng Li, Distributed Prefetching Scheme for Random Seek Support in Peer-to-Peer Streaming Applications. Workshop on Advances in Peer-to-Peer Multimedia Streaming, ACM Multimedia 2005, Singapore, November, 2005
- Changxi Zheng, Guobin Shen, and Shipeng Li, Segment Tree Based Control Plane Protocol for Peer-to-Peer On-Demand Streaming Service Discovery. Proc. of Visual Communication and Image Processing (VCIP), Beijing, China, July, 2005
- Changxi Zheng, Guobin Shen, Shipeng Li and Qianni Deng, Joint Sender/Receiver Optimization Algorithm for Multi-Path Video Streaming Using High Rate Erasure Resilient Code. Proc. of IEEE International Conference on Multimedia and Expo (ICME), Amsterdam, Netherlands, July, 2005
