In this section, we provide a model that analyzes Zipf-like query distributions and provides closed-form optimal replication levels for the objects in order to achieve constant average lookup performance with low storage and bandwidth overhead.
In Zipf-like, or power law, query distributions, the number of queries to the ![]() most popular object is proportional to
most popular object is proportional to ![]() , where
, where ![]() is the parameter of the distribution.
The query distribution has a heavier tail for smaller values of the parameter
is the parameter of the distribution.
The query distribution has a heavier tail for smaller values of the parameter ![]() .
A Zipf distribution with parameter 0 corresponds to a uniform distribution.
The total number of queries to the most popular
.
A Zipf distribution with parameter 0 corresponds to a uniform distribution.
The total number of queries to the most popular ![]() objects,
objects, ![]() , is approximately
, is approximately
![]() for
for ![]() , and
, and
![]() for
for ![]() .
.
Using the above estimate for the number of queries received by objects, we pose an optimization problem to minimize the total number of replicas with the constraint that the average lookup latency is a constant ![]() .
.
Let ![]() be the base of the underlying DHT system,
be the base of the underlying DHT system, ![]() the number of objects, and
the number of objects, and ![]() the number of nodes in the system.
Initially, all
the number of nodes in the system.
Initially, all ![]() objects in the system are stored only at their home nodes, that is, they are replicated at level
objects in the system are stored only at their home nodes, that is, they are replicated at level ![]() .
Let
.
Let ![]() denote the fraction of objects replicated at level
denote the fraction of objects replicated at level ![]() or lower.
From this definition,
or lower.
From this definition, ![]() is
is ![]() , since all objects are replicated at level
, since all objects are replicated at level ![]() .
.
![]() most popular objects are replicated at all the nodes in the system.
most popular objects are replicated at all the nodes in the system.
Each object replicated at level ![]() is cached in
is cached in ![]() nodes.
nodes.
![]() objects are replicated on nodes that have exactly
objects are replicated on nodes that have exactly ![]() matching prefixes.
Therefore, the average number of objects replicated at each node is given by
matching prefixes.
Therefore, the average number of objects replicated at each node is given by
![]() .
Consequently, the average per node storage requirement for replication is:
.
Consequently, the average per node storage requirement for replication is:
The fraction of queries, ![]() , that arrive for the most popular
, that arrive for the most popular ![]() objects is approximately
objects is approximately
![]() .
The number of objects that are replicated at level
.
The number of objects that are replicated at level ![]() is
is
![]() .
Therefore, the number of queries that travel
.
Therefore, the number of queries that travel ![]() hops is
hops is
![]() .
The average lookup latency of the entire system can be given by
.
The average lookup latency of the entire system can be given by
![]() .
The constraint on the average latency is
.
The constraint on the average latency is
![]() , where
, where ![]() is the required constant lookup performance.
After substituting the approximation for
is the required constant lookup performance.
After substituting the approximation for ![]() , we arrive at the following optimization problem.
, we arrive at the following optimization problem.
Note that constraint 4 effectively reduces to
![]() , since any optimal solution to the problem with just constraint 3 would satisfy
, since any optimal solution to the problem with just constraint 3 would satisfy
![]() .
.
We can use the Lagrange multiplier technique to find an analytical closed-form optimal solution to the above problem with just constraint 3, since it defines a convex feasible space.
However, the resulting solution may not guarantee the second constraint,
![]() .
If the obtained solution violates the second constraint, we can force
.
If the obtained solution violates the second constraint, we can force ![]() to 1 and apply the Lagrange multiplier technique to the modified problem.
We can obtain the optimal solution by repeating this process iteratively until the second constraint is satisfied.
However, the symmetric property of the first constraint facilitates an easier analytical approach to solve the optimization problem without iterations.
to 1 and apply the Lagrange multiplier technique to the modified problem.
We can obtain the optimal solution by repeating this process iteratively until the second constraint is satisfied.
However, the symmetric property of the first constraint facilitates an easier analytical approach to solve the optimization problem without iterations.
Assume that in the optimal solution to the problem,
![]() , for some
, for some
![]() , and
, and
![]() .
Then we can restate the optimization problem as follows:
.
Then we can restate the optimization problem as follows:
| (5) | |||
| (6) | |||
This leads to the following closed-form solution:
![$\displaystyle x^*_i = [\frac{d^i(k^\prime - C^\prime)}{1 + d + \cdots + d^{k^\prime-1}}]^{\frac{1}{1-\alpha}}, \forall 0 \leq i < k^\prime$](img46.png) |
(7) | ||
| (8) | |||
We can derive the value of k' by satisfying the condition that
![]() , that is,
, that is,
![]() .
.
As an example, consider a DHT with base 32, Zipf parameter 0.9, 10,000 nodes, and 1,000,000 objects. Applying this analytical method to achieve an average lookup time of one hop yields k' = 2, x0 = 0.001102, x1 = 0.0519, and x2 = 1. Thus, the most popular 1102 objects would be replicated at level 0, the next most popular 50814 objects would be replicated at level 1, and all the remaining objects at level 2. The average per node storage requirement of this system would be 3700 objects.
The optimal solution obtained by this model applies only to the case ![]() .
For
.
For ![]() , the closed-form solution will yield a level of replication
that will achieve the target lookup performance, but the amount of replication may not be optimal because the feasible space is no longer convex.
For
, the closed-form solution will yield a level of replication
that will achieve the target lookup performance, but the amount of replication may not be optimal because the feasible space is no longer convex.
For ![]() , we can obtain the optimal solution by using the approximation
, we can obtain the optimal solution by using the approximation ![]() and applying the same technique.
The optimal solution for this case is as follows:
and applying the same technique.
The optimal solution for this case is as follows:
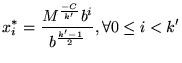 |
(9) | ||
| (10) |
This analytical solution has three properties that are useful for guiding the
extent of proactive replication.
First, the analytical model provides a solution to achieve any desired constant
lookup performance.
The system can be tailored, and the amount of overall replication controlled, for any level of performance by adjusting C over a continuous range.
Since structured DHTs preferentially keep physically nearby hosts in their top-level routing tables, even a large value for C can dramatically speed up end-to-end query latencies [4].
Second, for a large class of query distributions (![]() ), the solution provided by this model achieves the optimal number of object replicas required
to provide the desired performance.
Minimizing the number of replicas reduces per-node storage requirements, bandwidth consumption and aggregate load on the network.
Finally, k' serves as an upper bound for the worst case lookup time for any successful query, since all objects are replicated at least in level k'.
), the solution provided by this model achieves the optimal number of object replicas required
to provide the desired performance.
Minimizing the number of replicas reduces per-node storage requirements, bandwidth consumption and aggregate load on the network.
Finally, k' serves as an upper bound for the worst case lookup time for any successful query, since all objects are replicated at least in level k'.
We make two assumptions in the analytical model: all objects incur similar costs for replication, and objects do not change very frequently. For applications such as DNS, which have essentially homogeneous object sizes and whose update-driven traffic is a very small fraction of the replication overhead, the analytical model provides an efficient solution. Applying the Beehive approach to applications such as the web, which has a wide range of object sizes and frequent object updates, may require an extension of the model to incorporate size and update frequency information for each object. A simple solution to standardize object sizes is to replicate object pointers instead of the objects themselves. While effective and optimal, this approach adds an extra hop to C and violates sub-one hop routing.