Chlorophyll: Synthesis-Aided Compiler for Low-Power Spatial Architectures
As energy efficiency is becoming a major concern in modern processor design, a spatial architecture with simple interconnects turns out to be an attractive design choice due to its high energy dedication to computation. The GreenArrays GA144 is an example of a low-power spatial processor, consisting of multiple simple identical cores on one chip. Naturally, energy efficiency comes at some expenses, which usually include limited programmability. GA144 originally can only be programmed at low-level stack-based language, and programs will need to be meticulously partitioned and laid out onto each core, presenting non-trivial challenges to programmers and compiler designers.
Chlorophyll is a synthesis-aided programming model targeting GA144. This work tackles the challenges exposed by designing an efficient compiler for a specific spatial processor, but the methodology can inspire similar approaches to other processors.
Motivation
One important motivation is the poor programmability of GA144. GA144 incorporates radical architectural design decisions, for example, simple interconnects, no message buffers, and tiny storage capacity, forcing programmers to carefully partition data and instructions, and manually handle communication code among cores. Moreover, GA144 is developed in ArrayForth, a low-level stack-based language, so it takes some learning effort for programmers who are only familiar with the main-stream register-based systems.
Rewrite-based classical compilers are not able to bridge the abstraction gap of programming difficulties presented by low-power spatial architectures. The reason is two-fold: it’s time-consuming to design an optimized compiler for the target hardware, and the hardware architecture itself is evolving rapidly. Instead of rewriting a program, synthesis-based compilers search for an implementation given some specifications. Chlorophyll abstracts away tedious low-level stack-based programming efforts from programmers, but it does not mean that the generated program is out of human intervention. Programmers are granted the privilege to provide high-level inputs such as partitioning key data structures and code.
Solving the Subproblem Chain
The biggest problem of implementing a synthesis-based compiler is that it may not scale to large programs. Chlorophyll decomposes the problem of compiling a high-level program to spatial machine code into four subproblems: partitioning, layout and routing, code separation, and code generation. While these problems are difficult for traditional compilers, synthesis-based techniques can naturally solve these consecutive subproblems and thus the methods can apply to large, practical applications.
Partitioning
Chlorophyll extends a simple type system to simplify reasoning about partitioning and to avoid explicit communication code. The partitioning subproblem takes input source programs with partition annotations which specify the logical core where code and data reside. The input does not need to contain all annotations - actually most data and operators can be unannotated. For example, in this input program
int@0 mult(int x, int y) { return x * y;}
there are no annotations on the locations of variables x, y and the operation *. The synthesizer will infer all unspecified partitions, and output a fully annotated program with the minimized amount of messages among partitions. Here is one possible mapping:
int@0 mult(int@2 x, int@1 y) { return (x!1 *@1 y)!0;}
Details on typing rules can be found in Figure 2 in the paper. The extended type system enables the type inference of unannotated partition types, which is essentially the job of the partitioning synthesizer. To infer the unannotated partition types, two cost models are constructed to guide the search of design space, the communication interpreter estimates the number of communications needed and the partition space checker ensures the code and data fit in the memory space for each core. For example, the send operation ! increases the communication amount by 1, and consumes the memory space with the size of the sending operand. As for control statements, since it is necessary for each body partition of a control flow to access the result of the control expression locally in order to reduce the amount of communications, the evaluated control logic value will be sent to all the body partitions. Therefore, conditional statements will add the communication amount by the number of body partitions, and the condition expression takes up the memory space in all body partitions.
The communication count interpreter and the partition space checker are implemented using Rosette, a language for building light-weight synthesizers. For partially annotated programs, unspecified partition annotations will be represented as a symbolic variable, and Rosette’s back-end solver will search for a set of assigned partitions under the constraints of communication count and memory space. The process is pushed forward by setting the new constraint results to be the upper bound of the next iteration. This iterative process guarantees the optimality of the output annotated program.
Loop splitting is performed before partitioning to divide a loop into several subloops which can reside in separate cores.
Layout
The layout process maps partition numbers to physical cores. This step is modeled as a Quadratic Assignment Problem (QAP). There are a set of F facilities and a set of L locations. A flow function is specified representing the number of messages transmitted between each pair of facilities, and a distance function is specified as Manhattan distance for each pair of locations. The problem is to find a mapping solution from facilities to locations with the goal of minimizing the sum of the distances multiplied by the corresponding flows. The cost function is in quadratic form, hence the name of the problem. The authors found that Simulated Annealing (SA) generated the best solutions in the most efficient way, so this subproblem is solved by a SA implementation.
Code Separation
In this step, the program is separated into multiple fragments on physical cores. In particular, read and write operations are inserted into the code, during which the original order of operations is preserved to avoid deadlock. For basic statements, the code for each partition is generated by traversing the AST in post-order and placing sub-expressions according to the partition types. For functions, a function call in the original program corresponds to calling the function at all partitions it resides. For arrays, one array can be partitioned into multiple cores and perform computations in parallel.
Code generation
The code generation procedure takes in a single-core program and generates machine code. A typical way to generate machine code is by using a bottom-up approach that performs local optimizations and gradually builds up the whole sequence. This method applies well to regular architectures where the designers can determine all the valid ways to generated code. While on unusual hardware structure, it is unclear whether local optimizations can be sufficient to leverage some special hardware structures such as circular buffers.
The authors applied superoptimization to search for the optimal code sequence. However, superoptimizers only scale to small programs, and it is non-trivial to apply superoptimization to real problems.
One challenge is that a straightforward set of specifications can prevent some hardware-specific optimizations. Take the use of data stack as an example, a simple way we consider two sequences of instructions $P$ and $P’$ to be equivalent is that the live regions $L$ and $L’$ after executing $P$ and $P’$ respectively contain the same elements and the stack pointers are pointing at the same locations. This strict specification results in longer programs with additional instructions dedicated to removing older operands at the bottom of the circular stack, which is actually non-hazardous. The authors tailored the specifications for modular superoptimization to maximize the benefits of spatial architecture.
The other challenge is that when breaking down the large program into smaller pieces, the selection of the boundary can be tricky. The authors applied superoptimization on a sliding window of superoptimization units and consecutively find valid superoptimized segments. Although dynamic programming is able to produce a better result, the sliding window technique turns out to be more efficient.
The authors used Z3 SMT solver to perform the search. The state of a program and communication channels are encoded as a large bitvector that is fed in Z3. The address space is compressed to speed up the searching process.
Limitations
There are some occasions when the proposed solution misses some optimization opportunities or fails to produce partitions that are small enough to fit in cores. Since both partitioning and routing stages are schedule-oblivious, the output can introduce performance loss. Moreover, some context-related optimizations can be missing as the scope of superoptimization is still local to individual segments. To deal with the oversized partitions generated from the partitioning synthesizer, the compiler employs an iterative refinement method which increases the estimate margin in each rerun after the output fails to fit in cores.
Evaluation
This paper organizes the experiments in a clear and concise manner. The benefits brought by the proposed framework are presented as several hypotheses, and experiments are designed to prove their validity.
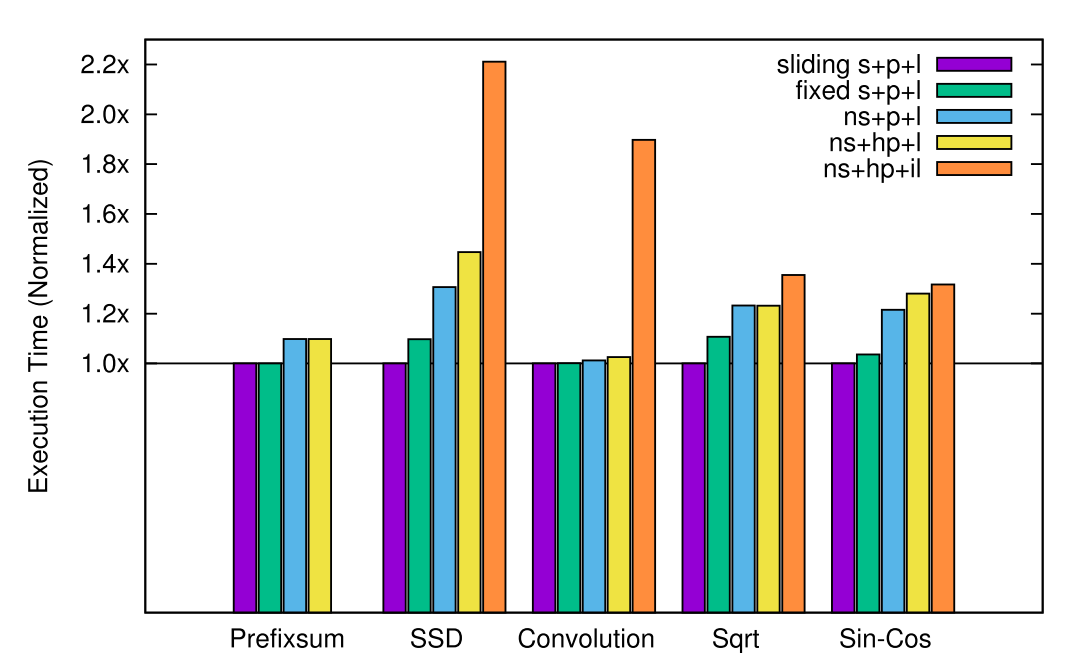
The first and foremost hypothesis is that the proposed partitioning synthesizer, layout synthesizer, superoptimizer and sliding windows technique indeed provide performance gain. The authors conducted experiments to compare against heuristic partitioner (hp), imprecise layout synthesizer (il), no superoptimizer (ns), and fixed-windows superoptimization (fixed s). The above figure shows the results, from which we can see the benefits breakdown for each technique.
Another advantage is that the partitioning synthesizer produces smaller programs that occupy fewer cores, compared with the heuristic algorithm. One drawback of a heuristic partitioner is it relies on manual parameter tuning to ensure that each program fragment fits within the space limit per core. The space estimation margin factor $k$ is an example of such parameters, varying with different applications. Hence, the synthesizer is more robust than the heuristic.
The superoptimizer can discover clever optimizations that traditional compilers may not, including logic simplification, strength reduction, and automatic CSE. The authors selected three bit logic computations as benchmarks and found that superoptimization provides 1.8x speedup and 2.6x code length reduction on average. This observation corresponds to the motivation of leveraging synthesis-aided compilers for unusual and evolving architectures. Traditional rewrite-based compilers only perform a limited number of optimizations, for which it is hard for them to catch up with emerging new hardware features.
The authors also evaluate results against expert-written programs on several single-core applications and one multi-core MD5 hash application. Compared to the experts’ implementation, the programs generated by Chlorophyll is 65% slower, 70% less energy-efficient and uses 2.2x more cores, which argues to be comparable. With the help of Chlorophyll, programmers can easily explore different implementations and get out a design with good performance in a short period of time. The compiler can also be improved by providing more human insights. For example, adding more highly optimized templates improves the performance of generated programs and scalability of the synthesizers.
Questions
- What are the unique advantages of synthesis-aided compilers over traditional compilers?
- Why did the authors tear apart the compilation problem into four subproblems?
- Why did the authors use superoptimization instead of dynamic programming when doing code generation? What benefits can be foreseen when choosing the algorithms?
- The paper mentioned some limitations in their methodology. What additional techniques do you think can help improve the results?