Reconsidering Custom Memory Allocation
In this post, I review "Reconsidering Custom Memory Allocation", a 2002 paper which (1) argues against the then-pervasive wisdom that writing custom memory allocators gives you performance boosts, and (2) introduces a data structure called a "reap" to do hybrid region / heap memory management. All images in this post are taken directly from the paper, or Emery's slides.
Background on Custom Allocation
Memory is necessary, but creating and freeing it takes time, and the general purpose memory management offered by C may not be optimal for your purposes. You probably know much more about the memory patterns of your application than the designers of the default memory allocator, and might be able to exploit this to save resources. Moreover, there is an opportunity to save a lot of time, as up to 40% (and 17% on average) of the program time can be spent allocating and de-allocating memory1:

All of this makes writing custom memory allocators very appealing.
Saving Time with Custom Allocation
For instance, suppose you have a large number of objects which you know you will eventually create, and have some upper bound on how many you'll eventually get. Suppose further that you know there are relatively few objects that are freed during the first phase of the program, which takes the most time. By the second phase, which you know executes quickly, you don't need any of the objects anymore. Now, a custom memory allocator can:
- Reduce the allocation time, by using only a single call to malloc, and getting enough space for them all at once (even though you might not know the exact number, or use them all at the same time, and you can't create them all yet).
- Save time with free calls: you can free them all at once at a the end, rather than freeing each object individually (which could still happen regularly) during phase one of the program when all of its references go away.
Allocating memory in this way would in fact be creating a region allocator: you allocate one large chunk of memory at first, and then increment a pointer into it; the entire region must then be freed all at one time.
Saving Space with Custom Allocation
The example above actually uses more memory than a heap. That is more common, but they can also be used to reduce the memory footprint, primarily by preventing fragmentation. For instance, if memory fragmentation is a huge issue, but you know roughly what fraction of your memory is used by objects of different sizes, you can partition it into pieces, and deal with each size class separately, which offers much better guarantees about the worst and average case fragmentation. This is commonly done in practice; Mesh, for instance, requires that all pages in question are of the same size class. The paper we analyze refers to allocators like these as "per-class custom allocators".
For all of these reasons, in 2002, it was common practice and widely considered a good idea to write a custom memory allocation for your program to improve performance.
The Drawbacks to Custom Allocation
Of course, even without any experiments, it is easy to see how doing this could be a mistake: the effectiveness of any of these relies on certain assumptions about the programs, and so any modifications need to be done while keeping the custom allocator in mind. Moreover, non-standard allocation schemes make it much more difficult to use existing tools to analyze your code. In more detail:
- Accidentally calling the standard
freeon a custom-allocated object could corrupt the heap and lead to errors. - Custom memory allocation makes it impossible to use leak detection tools.
- It also prevents you from using a different custom allocator to do something else that's more valuable in the future.
- It keeps you from using garbage collection.
The Paper: Reconsidering Custom Memory Management
The paper at hand, "Reconsidering Custom Memory Allocation", is packaged and sold as the thesis that custom memory allocators in practice do not out perform general ones.
One of the key arguments of this paper is that standard baselines are not fair. Evidently the usual argument in favor of custom allocation in 2002 was a comparison against the win32 memory allocator, which was much slower than custom allocators. The first part of this paper is an evaluation against the Lea allocator (Doug Lea's dlmalloc, now often the default allocator), which greatly reduces and in some cases eliminates the margin of victory for custom allocators not exploiting regions.
The Taxonomy of Memory Allocators.
This paper uses the following three bins to classify allocators:
[1] Per-class allocators. You build a separate heap for every object size class, and optimize each one separately for objects of this size. This is fast, simple, and interacts with C well---but could be space inefficient if you don't know how much memory of each class size you will use.
[2] Regions. An allocator that allocates large chunks of memory, puts smaller pieces within it, and then must free them all at once. They are fast and convenient, but use a lot of space and are arguably dangerous because dangling references keep things from being freed. This (nominally) requires programmers to re-structure code to keep references to the region, and free the entire region at once, resulting in a usage pattern that looks somewhat like this:
``` createRegion(r); x1 = regionMalloc(r,8); x2 = regionMalloc(r,8); x3 = regionMalloc(r,16); x4 = regionMalloc(r,8); ```
[3] Custom patterns. Anything else---for example, those that exploit stack-like patterns in memory allocation (the relevant benchmark is 197.parser). The authors describe these as fast, but brittle.
Experimental Setup
Although this paper is well-regarded and remembered primarily for its evaluation, the actual experimental data involves only 8 programs, each run with a single input. The table containing the programs and their inputs can be seen in the figure below:
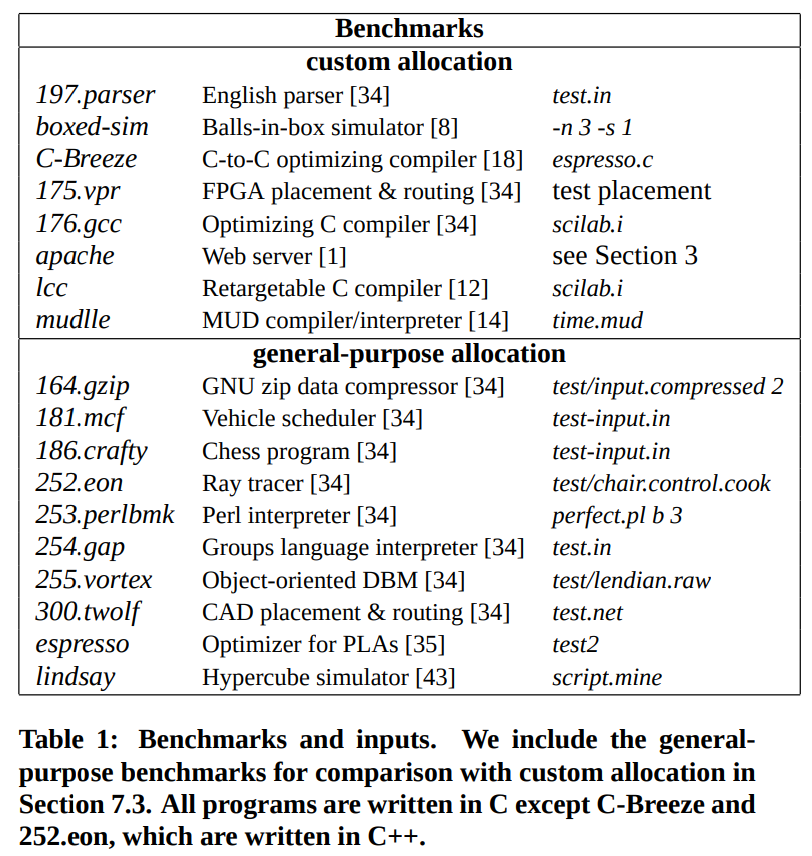
All of the other graphs in this blog post will reference the 8 benchmarks on the left, and run their experiments for a single input, a single time, not reporting variance, the impact of parameters, machine loads, or any other confounders. For a paper that is purported to be an exemplar takedown of a common design practice, and appears to have had a large impact on the state of memory allocation, its actual empirical backing could be more robust.
Given that there are only 8 data points, with no reported statistics, and more than 8 graphs presented in the paper alone (we must imagine the authors conducted far more that they did not report), that dozens of features were exposed, and that the authors were willing to consider non-linear decision boundaries (the is it a region decision stump2), makes things even more worrying. The authors also give very little attention to allocators that are not region-based. The hypothesis that the only design point of a custom allocator that could give it an edge over a general one is making use of regions, while very possibly true, is not particularly evident from the data: many of the region allocators also fail to outperform dlmalloc, and some non-region allocators have a slight edge.
Emulation
In order to compare allocators which have different semantics and expose different interfaces to the programmers, Berger et al. write an emulator so that these programs can be run using malloc and free. This allows them to be linked to the analysis tools, and for various properties of the programs to be computed, such as the drag. This hampers the custom allocators and could also be a source of performance disparity.
Results Part I: Custom vs General-Purpose Allocators
The primary finding of this paper is that that, while programs outperform the win32 memory allocator, they often roughly break even with the Lea allocator. The only custom allocators that seem to be able to get a reliable edge on dlmalloc are region allocators, as seen below:
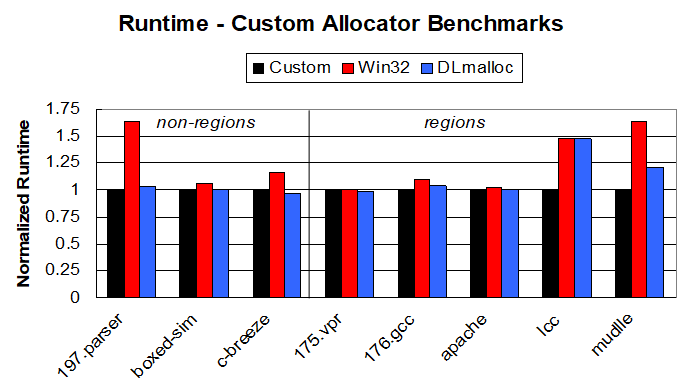
At a glance, we can see that dlmalloc roughly matches the performance of the custom allocators for all except for lcc and muddle, both region allocators. Given that the Lea allocator was already over a decade old when this paper was being written, it is surprising that people had not recognized this. Perhaps an alternate, less grand but equally appropriate framing of the discovery would be "the win32 memory allocator is not very good, and you have other options". The failure of regions to help in the first three applications remains an unexplored question. One also wonders about the possibility of a ninth data point in which a non-region allocator vastly out-performs dlmalloc.
Here are the results in terms of memory usage, for comparison:
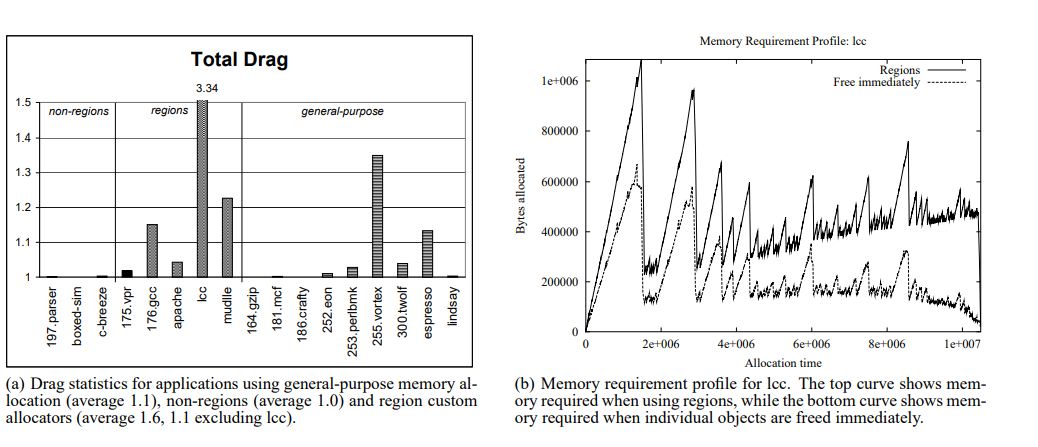
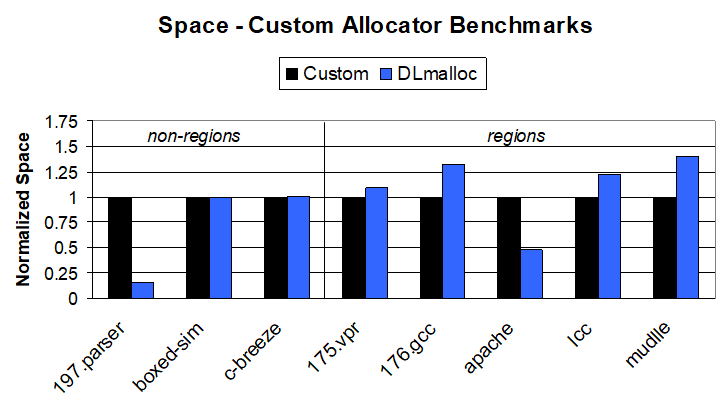 The observation the authors make is that regions can provide performance benefits in both realms, though regions' benefits are misleading, because their peak memory consumption is higher, and they often leave a lot of memory lying around, as seen in the drag graphs below:
The observation the authors make is that regions can provide performance benefits in both realms, though regions' benefits are misleading, because their peak memory consumption is higher, and they often leave a lot of memory lying around, as seen in the drag graphs below:
Regions and Reaps
In order to provide the performance benefits of regions to general purpose allocators, Berger et al. introduce "reaps", a merging of regions and heaps, sold as a generalization of both.
Recall that a heap exposes malloc and free; a region gives you a malloc and freeAll. The example in the paper is the following:
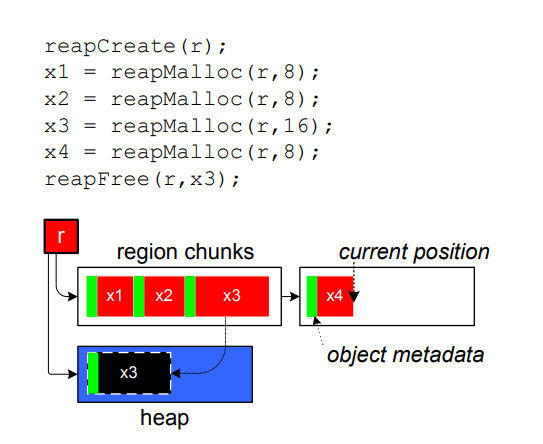
Unfortunately, this ends here, leaving readers to wonder why we allocated new memory and copied meta-data when really when we intended to free memory by deleting things. This is the entirety of the relevant description from the paper:
"Reaps adapt to their use, behaving either like regions or like heaps. Initially, reaps behave like regions. They allocate memory by bumping a pointer through geometrically-increasing large chunks of memory... Reaps act in this region mode until a call to
reapFreedeletes an individual object. Reaps place freed objects onto an associated heap. Subsequent allocations from that reap use memory from the heap until it is exhausted, at which point it reverts to region mode."
Owing in part to their elusiveness, I have not been able to determine with certainty how edge cases work, but I will give an expanded intuition for what reaps seem to be doing and why one might expect this to give some performance benefits:
A Pair of Heuristics
We start a new heap because the assumption is that after freeing some memory, we will probably be both freeing and allocating memory frequently in the future. Thus, the very end of our memory acts like a heap for a little while, so a bout of object creation and deletion has only the impact of a single loop iteration on the consumed memory. Effectively, we are using the heuristic that freeing an individual object means we don't want to be using regions "right now", and in particular, for the upcoming allocations.
On the other hand, how do we know we should go back to allocating things in region mode? This should happen when we've allocated a lot of memory without freeing any. Thus, we go back to region mode when the heap is full. This is our second heuristic. In some ways, tying these two together to the size of an artificial heap seems like a very neat trick.
Impact on Programmers
The authors argue that this is purely positive, as it gives programmers the option of programming in a style that is region-like, and thereby gaining all of its benefits, but also leaving them the freedom to do other things. This seems compelling, but one might also worry that by not forcing programmers to interact with the region semantics, one will lose their attention and mistakes will not be caught. For instance, mostly using region mode, while freeing an occasional object would result in a modest overhead and in reality frees exactly zero memory; such a mistake might not be easy to see.
Results Part II:
Reaps do indeed reap the performance benefits that were expected on them (at least as far as these 8 program traces are concerned). Below, we can see the same graph, with the addition of reaps:
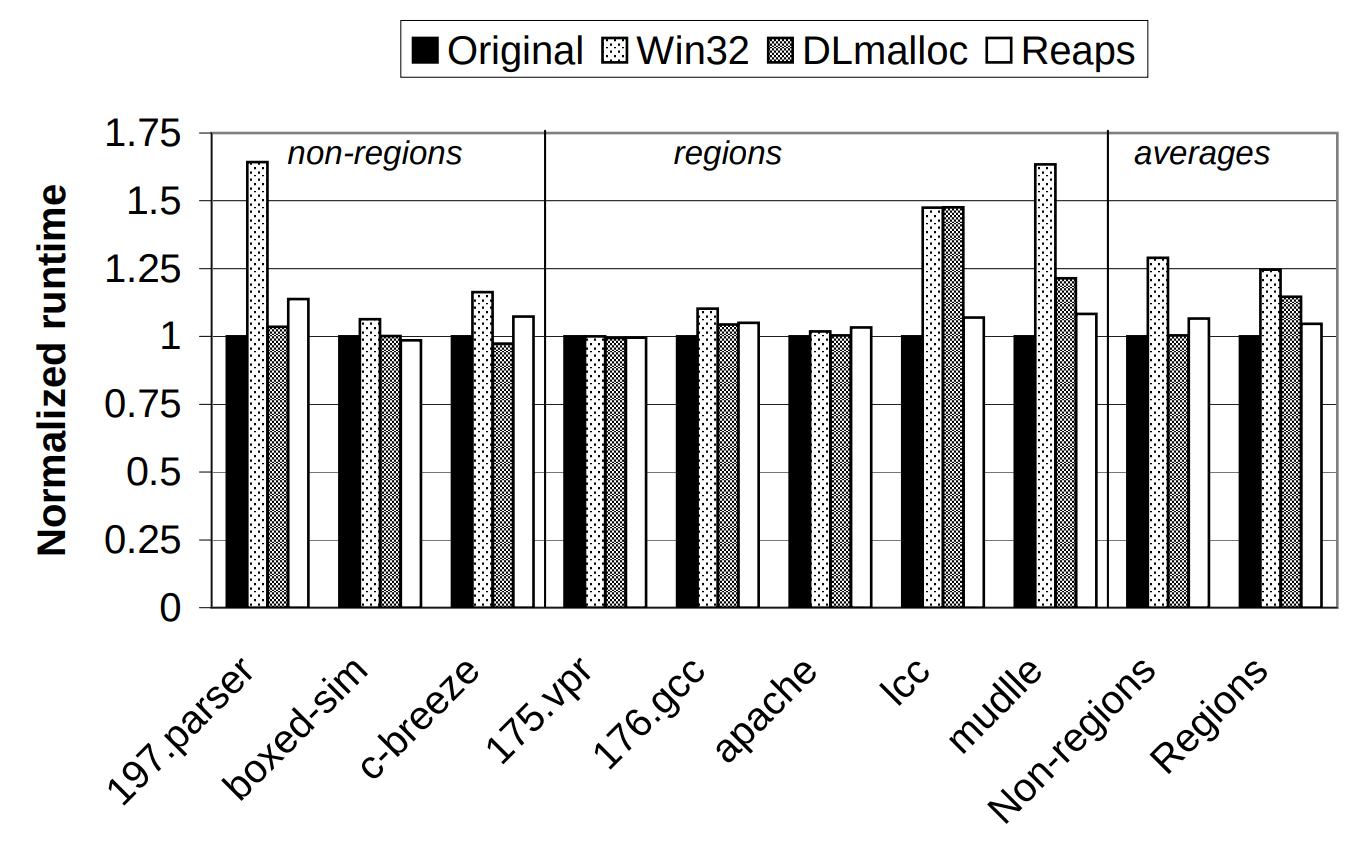
The most important feature of this graph, of course, is the fact that reaps perform reasonably well compared to dlmalloc and the custom allocators for programs that don't use regions, and don't pay as much as dlmalloc on lcc and muddle, where regions have given a large performance bump beyond the other general-purpose allocators.
The authors draw this conclusion unreservedly, but there are some very worrying things about this graph.
- Almost all of the performance benefit comes from a single data point,
lcc, which dlmalloc handles no better than win32. Even formuddle, dlmalloc does not perform terribly. - In addition, reaps have a small overhead on nearly everything; it is particularly pronounced for the parser and c-breeze.
- Combining the first two points, it seems as though dlmalloc would out-perform reap on average if we take out
lcc. - Almost none of the trends that one can read off of this graph are supported uniformly by all of the points. And Once agin there are only 8 of them.
From 2002 to 2019
The Lea allocator (Doug Lea's malloc, now referred to as dlmalloc) is now the default implementation of Linux. The standard general purpose allocator to beat in evaluations is now jemalloc, which seems to be considerably more efficient 3. The existence of even better general purpose allocators in some ways strengthens the point made by the paper: there's even less to be gained by writing your own allocator.
On the other hand, custom memory allocation is not quite dead. Here's a tutorial on how and why custom allocators are helpful, custom allocation still is seen as a potential reason to disregard projects such as Mesh, and Emery Berger's Heap Layers project (used to construct reaps in the present paper), which has been much more widely employed, ironically is a framework for building custom allocators, by its own admission:
"Heap Layers makes it easy to write high-quality custom and general-purpose memory allocators."
What happened to reaps? Though modern memory allocators more effectively put off frees to make them more region-like, "reap" is not a common term for memory allocators---in fact, only a small handful of the papers that cite this one mention reaps (and all share authors).
It is interesting that the reap, which one might consider the more substantive, creative contribution to this paper, does not seem to have caught on. In his 2012 blog post in which he acknowledges a most influential paper award for this paper, Emery tells people (with extreme brevity and no explanation) to use his more modern allocator, Hoard, instead of reaps. Even more strangely the technical paper that Hoard is based on does not include the word "reap", leaving us wondering what happened to them. Still, an implementation lives on in the legacy portion of the Heap Layers project.
Conclusions
While this paper seems to have been largely correct in several important ways, many of its elements leave something to be desired, as discussed in the Empirical Setup section. The evaluation seems thorough but has a limited scope and draws conclusions stronger than the data alone seem to support; the new algorithm and data structure (reaps) seem very useful and are sold well, but explained poorly, with only a partial example which doesn't illustrate interesting cases, no theoretical backing, and no explanation of the heuristics that enable its performance.
These reaps do not seem to have been used more than once or twice since 2002, and not for lack of publicity (several claim, nebulously, to use "ideas from reaps"). It is unclear whether the reason they were not adopted was because of the presentation, because they never were quite as good as they seem (after all, there are only 8 data points, and it might be easy to overfit to them with parameter or design tuning), or because something better came along shortly thereafter. With no follow-up studies or testing on benchmarks for which they were not designed, it's hard to know.
Even so, the general message is well-articulated, appears to have rung true in retrospect, and perhaps necessarily so. As general-purpose allocators get even better, and perhaps even begin to be tunable to custom programs, out-performing them becomes increasingly difficult. This is a general trend: while knowing something about the matrices you want to multiply may have been an invaluable place to mine in order to edge out general purpose matrix multiplication algorithms, today it is almost impossible to out-perform standard libraries for doing them---so much so, that it is often beneficial to rewrite other computations in terms of matrix multiplications to accelerate them; moreover, representing computations in this generic way often provides some more standard insights into the structure of your problem and allows you to immediately make use of relevant algorithms. For similar reasons, it is hard to imagine that custom memory allocators will do any more than dwindle.