Point-to-point measurements were made by sending messages around a ring of 4 nodes using MPI_Send and MPI_Recv. All latencies shown are the time per hop (the time around the ring divided by 4).
The per hop latency is shown for thin nodes in Figure 8
and for wide nodes in Figure 10. On the thin nodes MPI
over AM achieves a lower small-message latency than MPI-F while on
wide nodes MPI-F is faster for messages of less than 100 bytes but
slower for larger messages. The communication bandwidths using thin
and wide nodes are shown in Figures 9 and 11,
respectively. Evidently MPI-F was optimized for the wide nodes while
MPI-AM was developed on thin ones.![]() The unoptimized version of MPI-AM shows no performance hit
when switching from a buffered protocol to a rendez-vous protocol
because the switch occurs at 16K byte messages where the copy overhead
of the buffered protocol is already significant. The optimized
version switches over at 8K, but shows no performance hit because of
the hybrid buffered/rendez-vous protocol.
The unoptimized version of MPI-AM shows no performance hit
when switching from a buffered protocol to a rendez-vous protocol
because the switch occurs at 16K byte messages where the copy overhead
of the buffered protocol is already significant. The optimized
version switches over at 8K, but shows no performance hit because of
the hybrid buffered/rendez-vous protocol.
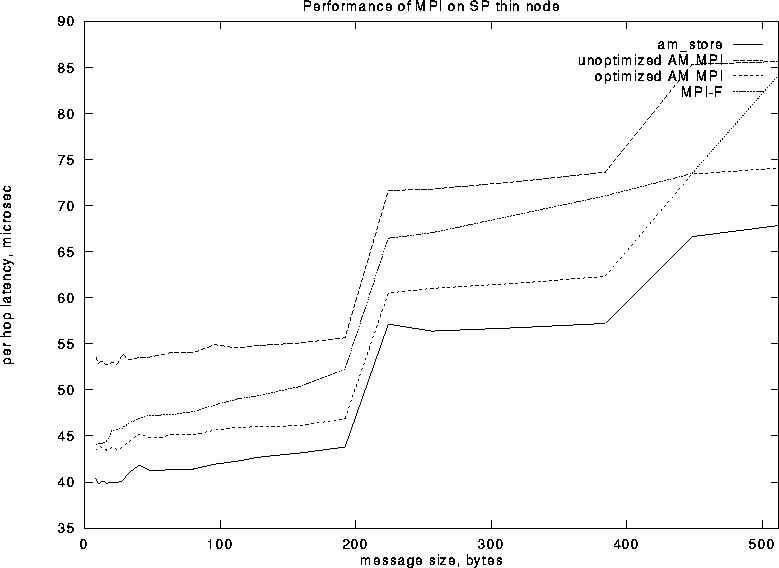
Figure 8: MPI Point to Point Latencies on Thin SP Nodes
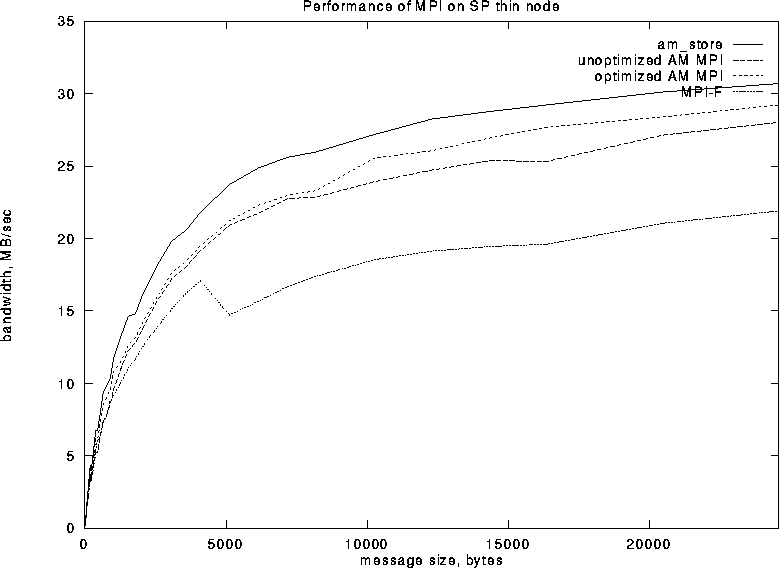
Figure 9: MPI Point to Point Bandwidths on Thin SP Nodes
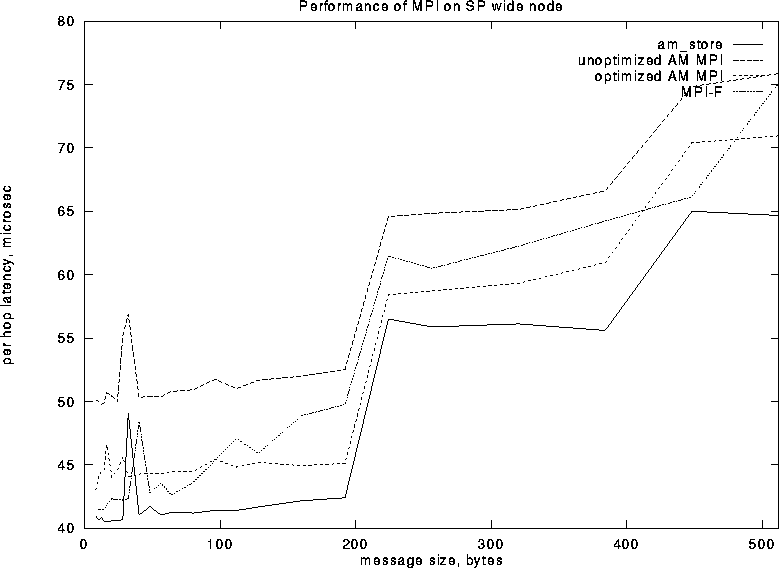
Figure 10: MPI Point to Point Latencies on Wide SP Nodes
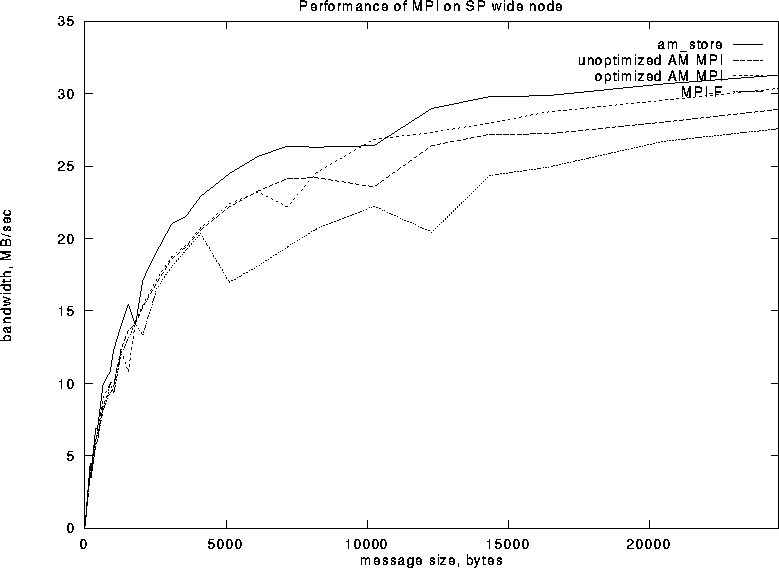
Figure 11: MPI Point to Point Bandwidths on Wide SP Nodes