1. Installation
1.1 Prerequisites
Troika requires certain dependencies to be installed either on your cluster or on your local machine. Most of these tools may have already been packed with your Linux distribution. Please make sure that the corresponding prerequisites are installed on the target cluster and on your local machine.
1.2 Installing from Git
Your local machine:
- Use git to clone Troika repo on your local machine.
git clone https://github.com/efeg/Troika.git- Before running the following commands, make sure that your directory is writable by the current user.
cd Troika
make -C Debug/The target cluster:
- Copy
clusterConfigReader.pyandyarnConfig.pyto your$HADOOP_HOMEpath on the target cluster.
cd Tools/ConfigDiscovery/
scp *.py user@your.server.example.com:/your/HADOOP_HOME/path1.3 Verify Installation
Upon succesfull installation, you should be able to see the built-in help messages. Confirm that the following commands produce meaningful messages:
Your local machine:
cd Troika
Debug/Troika --help
python Tools/IntensityOptimizer/intensityOptimizer.py -h
python Tools/RecomEngine/recommendationEngine.py -hThe target cluster:
python $HADOOP_HOME/clusterConfigReader.py -h
python $HADOOP_HOME/yarnConfig.py -h2. Getting Started
This section is designed to introduce a use-case scenario that involves setting up the initial profile, intensity optimization, configuration recommendation and simulation. We will use TeraSort as our target application with a 10GB input file generated via TeraGen. Before proceeding further, make sure that you verified your Troika installation.
2.1 Initial Profile Wizard
- The aim of this tool is to generate the initial profile required as an input to Troika. A profile for Troika consists of all parameters that are necessary to do an accurate simulation of a MapReduce application (or set of applications) on a cluster. It contains: application properties that identify characteristics of one or more target applications, hardware properties that identify the cluster components, cluster topology that describe how the components are networked, and the MapReduce 2.0 configuration that includes properties that affect the framework behavior. Profile generation process includes a series of configuration parsing and measurement operations. Before running IPW, make sure that you have access to the target cluster, and the required files are executable:
cd $HADOOP_HOME/
chmod 777 yarnConfig.py clusterConfigReader.py2.1.1 Generating the Initial Profile
- Run the following command with the required arguments:
- HDFS path of application input folder (e.g.
/in) - Disk device path (e.g.
/dev/sda4) - The other hostnames that are in the same rack with the current node (e.g.
node1node2).
- HDFS path of application input folder (e.g.
python yarnConfig.py /application/input/path/in/HDFS /disk/device/path node1 node2- Upon completion of the execution, confirm that your initial profile is located at
$HADOOP_HOME/TroikaConf/input.txt.
- The current version of the IPW…
- Partially generates the initial profile. Users need to provide the remaining parameters such as the topology information and task intensities.
- Cannot collect information about the execution time behavior of the application. It performs measuring and configuration parsing, but not profiling.
- Unspecified optional arguments should be removed from the generated file to use the default configuration parameters set by the framework.
2.1.2 Completing the Initial Profile
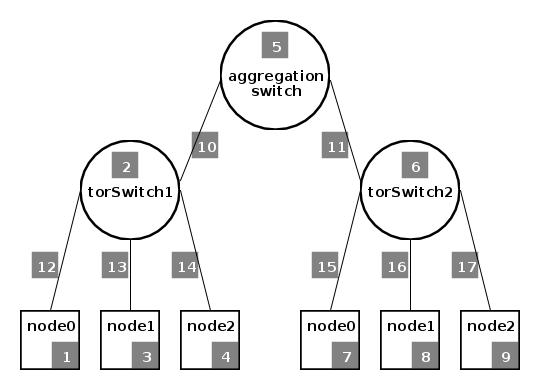
In this step, we will add the remaining required information and remove unspecified optional parameters from the automatically generated initial profile to use the default configuration parameters for them.
-
The cluster that we used in this tutorial is structured as illustrated on the right. Note that each component (i.e. node, link and switch) has a user-assigned unique ID associated with it. These IDs correspond to
IDs in the input file. For links,upEndpointIDandlowEndpointIDrepresent the event IDs expected by the components on the upper and lower tip of the link in the network hierarchy, respectively.rackIDrepresents the ID of thetor switchthat a node is connected to. The current version of Troika supports only the top-of-rack (ToR) network connectivity architecture. -
Processing capacity of cores are determined in terms of bytes that they can process per second. It is assumed that the cores are homogeneous regarding their processing capabilities.
-
A
task intensityspecifies the average computational weight of a single byte for a specific operation. It depends on the type of application as well as the content and size of its input. Troika allows customization for map, reduce, map-sort, reduce-sort and combiner (if any). To aid in determination of these intensities, Troika provides Intensity Optimizer tool to optimize user-provided task intensities. -
mapOutputPercentrepresents the percent ratio of the map phase output to the application input.reduceOutputPercentrepresents the percent ratio of the reduce phase output to the shuffled input.finalOutputPercentrepresents the percent ratio of the application output to the application input. -
nodeTyperepresents whether a node is aCLIENT(1),RESOURCEMANAGER(2) or aNODEMANAGER(3).RESOURCEMANAGERcontains the global Resource Manager daemon,NODEMANAGERnode is a worker node where the tasks run andCLIENTis a specialNODEMANAGERnode which is used to simulate job submission process as well as task processing. In a cluster, there is a singleCLIENTandRESOURCEMANAGERbut manyNODEMANAGERs. -
Here is the completed input file
2.2 Intensity Optimizer
This optional tool aims to provide optimizations for the user-defined intensities in the base configuration profile. To succeed this, intensity optimizer requires data from real experiment results.
- Create your experiments file containing the results from real experiments to optimize the intensities in the Troika input. Line(s) of this file should be formatted as follows:
exp <exp-name> res <conf-name_1> <conf_value_1> ... res <conf-name_m> <conf_value_m> <timing-name_1> <time_1 (s)> ... <timing-name_n> <time_n (s)> repeat <repetition-number>exp-nameis a unique identifier for each experiment. Remaining parameters are presented below.
--------------------------------------------------------------
Note: .* means any one or more consecutive characters
ACCURACY-RELATED DATA
---------------------
repeat: number of times to repeat the simulation of this experiment
TIMING-RELATED DATA <timing-name>
---------------------------------
elapsed: elapsed time (s)
avgMap: average map time time (s)
avgRed: average reduce time time (s)
shuffle: average shuffle time time (s)
CONFIGURATION-RELATED DATA <conf-name>
--------------------------------------
cores: number of cores
coresp.*: core speed in bytes/s
nets.*: network speed in bytes/s
maxr.*: maximum HD read speed in bytes/s
maxw.*: maximum HD write speed in bytes/s
minr.*: minimum HD read speed in bytes/s
minw.*: minimum HD write speed in bytes/s
me.*: memory size (bytes)
app.*: application size (bytes)
mapo.*: map output percent
reduceOutputPercent.*: reduce output percent
fin.*: final output percent
mapreduce.input.fileinputformat.split.min.*: mapreduce.input.fileinputformat.split.min
mapreduce.input.fileinputformat.split.max.*: mapreduce.input.fileinputformat.split.max
dfs.*: dfs.blocksize
mapreduce.map.sort.spill.percent.*: mapreduce.map.sort.spill.percent
yarn.nodemanager.resource.memory-mb.*: yarn.nodemanager.resource.memory-mb
mapreduce.task.io.sort.mb.*: mapreduce.task.io.sort.mb
mapreduce.task.io.sort.factor.*: mapreduce.task.io.sort.factor
mapreduce.reduce.shuffle.merge.percent.*: mapreduce.reduce.shuffle.merge.percent
mapreduce.reduce.shuffle.input.buffer.percent.*:mapreduce.reduce.shuffle.input.buffer.percent
mapreduce.job.reduce.slowstart.completedmaps.*: mapreduce.job.reduce.slowstart.completedmaps
record.*: record size (bytes)
mapreduceMapMemory.*: mapreduceMapMemory
mapreduceReduceMemory.*: mapreduceReduceMemory
amResourceMB.*: mapreduce.am.resource.mb
mapCpuVcores.*: mapreduce.map.cpu.vcores
reduceCpuVcores.*: mapreduce.reduce.cpu.vcores
mapIntensity.*: mapIntensity
mapSortIntensity.*: mapSortIntensity
reduceIntensity.*: reduceIntensity
reduceSortIntensity.*: reduceSortIntensity
combinerIntensity.*: combinerIntensity
reducer.*: number of reduce tasks-
TIMING-RELATED DATAandnumber of reduce tasksconstitute the minimum information that the tool requires. Further information could be provided through the parameters listed inCONFIGURATION-RELATED DATA.ACCURACY-RELATED DATAcan be used to set the number of times an experiment is repeated by Troika’s simulator. This option is useful in increasing the accuracy of the optimized intensities. -
For this experiment, we used the base configuration profile that we generated for TeraSort. The experiments file that we used has the following content:
exp E6 res reducers 1 elapsed 1216 repeat 3 avgMap 41 avgRed 950 shuffle 249- Run the tool with
-aoption to set the desired level of accuracy. For instance, a0.01percent accuracy means that the difference between the actual and the simulated elapsed time of application execution cannot be larger than1%.-loption represents the log level. To see further options run the optimizer with-hflag.
cd Tools/IntensityOptimizer/
python intensityOptimizer.py optimizerList.txt -l 2 -a 0.01- Check the generated output with the optimized intensities for map, reduce, map sort, reduce sort and combiner (if any):
RECOMMENDED INTENSITIES:
E6 map intensity: 0.1 map sort intensity: 0.1 reduce intensity: 6.3926595278 reduce sort intensity: 6.3926595278 combiner intensity: 0- Note that the original base configuration profile is not updated with the optimized values automatically. You should update this file with the recommended intensities.
2.3 Configuration Recommendations
In this tutorial, we will use Troika for gathering recommendations to minimize the execution time of TeraSort application.
- Troika requires two input files to be able to generate its recommendations. First, it needs the initial profile that we generated in Initial Profile Wizard. Second, it needs a configuration space among which it makes a selection based on the expected performance with the proposed configuration parameters. Each line of the configuration space is a bundle that is formatted as follows:
bundle <bundle-name> rangeres reducers <bottom limit> <upper limit> <step size> res <conf-name_1> <conf_value_1> ... res <conf-name_m> <conf_value_m> nodecost <cost_value> linkcost <cost_value> repeat <repetition-number>bundle-nameis a unique identifier for each configuration.rangeres reducersrepresents the number of reduce tasks the proposed bundle considers (i.e. it considers [bottom limit,bottom limit+step size,bottom limit+ 2*step size, …,upper limit] number of reduce task). Users can provide further configurations (listed below) using<conf-name>s and corresponding values.ACCURACY-RELATED DATAsets the number of times a specific bundle is simulated. Finally, users can specify a per node and per link cost, so that the cluster cost can be considered in case there is a budget limit.
--------------------------------------------------------------
Note: .* means any one or more consecutive characters
ACCURACY-RELATED DATA
---------------------
repeat: number of times to repeat the simulation of this bundle configuration
CONFIGURATION-RELATED DATA <conf-name>
--------------------------------------
cores: number of cores
coresp.*: core speed
nets.*: network speed in bytes/s
maxr.*: maximum HD read speed
maxw.*: maximum HD write speed
minr.*: minimum HD read speed
minw.*: minimum HD write spedd
me.*: memory size
app.*: application size
mapo.*: map output percent
reduceOutputPercent.*: reduce output percent
fin.*: final output percent
mapreduce.input.fileinputformat.split.min.*: mapreduce.input.fileinputformat.split.min
mapreduce.input.fileinputformat.split.max.*: mapreduce.input.fileinputformat.split.max
dfs.*: dfs.blocksize
mapreduce.map.sort.spill.percent.*: mapreduce.map.sort.spill.percent
yarn.nodemanager.resource.memory-mb.*: yarn.nodemanager.resource.memory-mb
mapreduce.task.io.sort.mb.*: mapreduce.task.io.sort.mb
mapreduce.task.io.sort.factor.*: mapreduce.task.io.sort.factor
mapreduce.reduce.shuffle.merge.percent.*: mapreduce.reduce.shuffle.merge.percent
mapreduce.reduce.shuffle.input.buffer.percent.*:mapreduce.reduce.shuffle.input.buffer.percent
mapreduce.job.reduce.slowstart.completedmaps.*: mapreduce.job.reduce.slowstart.completedmaps
record.*: record size
mapreduceMapMemory.*: mapreduceMapMemory
mapreduceReduceMemory.*: mapreduceReduceMemory
amResourceMB.*: mapreduce.am.resource.mb
mapCpuVcores.*: mapreduce.map.cpu.vcores
reduceCpuVcores.*: mapreduce.reduce.cpu.vcores
mapIntensity.*: mapIntensity
mapSortIntensity.*: mapSortIntensity
reduceIntensity.*: reduceIntensity
reduceSortIntensity.*: reduceSortIntensity
combinerIntensity.*: combinerIntensity- Here is an excerpt from the configuration space we created in this format:
...
(More bundles...)
...
bundle C3081 rangeres reducers 1 3 1 res yarn.nodemanager.resource.memory-mb 11264 res dfs 268435456 res mapreduce.input.fileinputformat.split.min 67108864 res mapreduce.job.reduce.slowstart.completedmaps 0.15 res mapreduce.map.sort.spill.percent 0.85 res mapreduce.task.io.sort.factor 10 res mapreduce.task.io.sort.mb 110 res mapreduce.reduce.shuffle.merge.percent 0.68 res mapreduce.reduce.shuffle.input.buffer.percent 0.71 nodecost 0 linkcost 0 repeat 1
bundle C112 rangeres reducers 1 3 1 res yarn.nodemanager.resource.memory-mb 8192 res dfs 67108864 res mapreduce.input.fileinputformat.split.min 67108864 res mapreduce.job.reduce.slowstart.completedmaps 0.2 res mapreduce.map.sort.spill.percent 0.85 res mapreduce.task.io.sort.factor 9 res mapreduce.task.io.sort.mb 104 res mapreduce.reduce.shuffle.merge.percent 0.7 res mapreduce.reduce.shuffle.input.buffer.percent 0.72 nodecost 0 linkcost 0 repeat 1
bundle C2015 rangeres reducers 1 3 1 res yarn.nodemanager.resource.memory-mb 10240 res dfs 67108864 res mapreduce.input.fileinputformat.split.min 268435456 res mapreduce.job.reduce.slowstart.completedmaps 0.15 res mapreduce.map.sort.spill.percent 0.85 res mapreduce.task.io.sort.factor 11 res mapreduce.task.io.sort.mb 110 res mapreduce.reduce.shuffle.merge.percent 0.7 res mapreduce.reduce.shuffle.input.buffer.percent 0.71 nodecost 0 linkcost 0 repeat 1
...
(More bundles...)
...- Run the following command to execute Troika. Optional arguments allow further customizations such as enforcement of a budget limit, enabling log messages with different verbosity levels and changing the sample size needed for generation of RSM model:
python recommendationEngine.py path/to/configuration/space -i path/to/base/profile- Upon execution, Troika will provide a report with the recommended configurations, estimated expense of building a cluster with this configuration, estimated application runtime, average map/reduce task completion times, shuffle time, and total map time that presents the elapsed time from the initiation of the first map task to the completion of the last one. Here are the recommended configurations of Troika for TeraSort, which yields almost 5x performance improvement over the default configuration:
...
---------CONFIGURATION SUMMARY---------
Reducer Count: 3
mapreduce.input.fileinputformat.split.minsize: 67108864
dfsBlocksize: 67108864
mapreduce.map.sort.spill.percent: 0.75
yarn.nodemanager.resource.memory-mb: 11264
mapreduce.task.io.sort.mb: 108
mapreduce.task.io.sort.factor: 11
mapreduce.reduce.shuffle.merge.percent: 0.68
mapreduce.reduce.shuffle.input.buffer.percent: 0.72
mapreduce.job.reduce.slowstart.completedmaps: 0.2
...2.3 Simulation
Troika’s simulator can work as a standalone component to report simulation results with certain configurations. It uses the same base configuration profile as the input file. Use -h flag to see further options.
Debug/Troika -i test/input.txtOVERALL SIMULATION TIME FOR APPLICATION 0 IS 1296.9 !
AVERAGE MAP SIMULATION TIME FOR APPLICATION 0 IS 49.6081
AVG REDUCE SIMULATION TIME FOR APPLICATION 0 IS 959.586
SHUFFLE SIMULATION TIME FOR APPLICATION 0 IS 307.316
MAP SIMULATION TIME FOR APPLICATION 0 IS 162.012