MathBus

MathBus |
|
[ Term
Structure | Algebra
| Geometry | Logic | Drawing ]
[ Language Bindings
| C++ | Java | Lisp | ML ]
A complete listing of all the pages in the MathBus Term structure specification can be found in the TOC file. This file is not well formatted, but it is useful when one wants to print out the pages of the specification.
The MathBus term structure provides a simple interchange format for transmitting mathematical objects between different applications and between software developed in different programming languages. This format can be used to store mathematical objects in files, databases and web pages and to provide a data structures to support mathematical transformations.
Interchange and inter-operation formats are used to exchange objects between applications that were designed with their own internal formats. Because each application contains its own good ideas, existing interchange formats are often unions of the good ideas for a range of different applications. In contrast, the MathBus term structure focuses on a small, relatively low-level core that is easy to represent and into which the representations used by a wide variety of different languages and applications can be mapped. It takes a "RISC" approach to interchange mechanisms.
The MathBus term structure provides a mechanism for communicating a wide range of mathematical concepts between programs running on the same or different computers, between computers of different architectures and between programs written in languages with different storage models. These concepts include algebraic and analytic expressions, geometric and topological structures, numerical solutions of differential equations and logical structures like theorems and proofs. This term structure makes it possible to store these mathematical objects in persistent storage, to embed these objects in compound documents and to publish these objects on the world wide web.
The simplest approach would be to use a textual representation for mathematical objects, similar to the user input languages of Matlab, Maple or Mathematica. Thus, the polynomial x2 + 1 might be written as "x^2+1". Reaching agreement on basic mathematical operations like addition and multiplication is not difficult. However, when one considers the mathematical expressions of all types, geometry, topology, logic, etc., a wide variety of different textual notations are used and re-used and it would be difficult to reach broad agreement.
The MathBus term structure takes a different approach. It uses a mechanism for interchanging the data structures (or parse trees) of the mathematical expressions, instead of the human readable ASCII text. Since the term structure is syntax independent, applications can choose whatever syntax is appropriate.
It is not our intention that these structures be used for implementing high performance mathematical algorithms or serve as high performance interchange structures as would be used in parallel mathematical computations. In the flexibility/performance tradeoff, the MathBus term structure has tended to opt for flexibility while retaining efficiency as an important, but secondary consideration.
The MathBus term structure provides a powerful, but simple language-independent term structure that is used as the data structure for all mathematical objects. At its core are is a simple term structure based on trees. The labeling of the nodes of the trees gives them mathematical meaning. A small family of tools are provided to simplify the use of the term structure. These tools are independent of the labeling placed on the nodes. Within this library are tools that serialize the term structure into byte streams, and iteration tools make implementing transformations on the term structure easy. Finally, a set of tools is provided that simplifies the implementation of OLE controls using the term structure.
To most users of the interchange standard, the mathematical objects on the MathBus are opaque. Functions are provided, however, to convert the opaque form of the objects to textual forms (e.g., OpenMath, Mathematica, Maple, etc.) that can be used a variety of applications. In addition, importing routines will be provided to allow reading and writing of foreign file formats, like DXF files from AutoCAD. Finally, for those applications for which it is appropriate, and for the implementation of the above techniques, the term structure and tool libraries themselves can be made available to the application.
To simplify access to objects in the MathBus representation, we will provide (1) embeddings of MathBus objects in OLE and ActiveX, (2) textual input and output, adhering to the OpenMath Standard, (3) byte stream I/O of MathBus objects, (4) access to MathBus term structure with libraries of iterators and reducers in C++, Java, ML and Lisp.
The MathBus term structure is defined in three layers. At its core is a simple tree based structure, which we call the Level-0 term structure. Each node in a tree contains a label and a number of sub-terms. The number of sub-terms can be as large as 232 - 1, so this mechanism can also be used to represent vectors.
The Level 1 term structure captures idiomatic uses of the tree structure to represent more complicated structure like graphs. Standardizing the labels of tree nodes for these idioms allows us to minimize repetition of code by users of the term structure and allows us to make the iteration and other tools for manipulating the term structure more powerful. Among the node labels we standardize are a node label that indicates an illegal (uninitialized) node, node labels for representing strings and floating point numbers, one for a node whose value is not yet computed, or not yet loaded into memory, and a few other special situations.
The Level-2 term structure introduces semantics for the node labels so that the term structure can represent different types of mathematical expressions. These labels and their semantics are described in Part II of this document, along with special purpose libraries for performing mathematical operations on these terms.
A set of tools that simplify using the MathBus term structure in applications is also provided. These tools include a canonical hash coding mechanism that produces the same hash code for a term independent of the language and architecture on which the hash code is computed, routines that convert the term structure into and out of a standardized byte stream, and functional iterators that apply a function at each sub-node of a term, paying proper attention to the level-1 operators.
| nSubterms |
| label |
| Subterm1 |
| . . . |
| SubtermnSubterm |
Figure 1. Basic node structure
The MathBus term structure is quite simple. Terms are represented as trees. The leaves of these trees can be of one of only two types: 32-bit unsigned integers or 32-bit string identifiers that identify certain immutable Unicode strings. Some string identifiers are globally declared and are known to all implementations of the MathBus term structure. Others are created by specific applications, and must be publicized before MathBus terms are exchanged between applications or placed in persistent storage. The MathBus Registry manages the association between string identifiers and Unicode strings.
Nodes of a MathBus tree consist of three logical components: the node label, the number of sub-terms of the node and the vector sub-terms of the node. Each sub-term of a node is either a leaf or a reference to another node.
The label field is itself a string identifier. The Unicode string associated with the node label's string identifier is called the symbolic label of the node. The 32-bit integer associated with the string identifier is called the numeric label of the node.
The nSubterms field (number of sub-terms) is restricted to 32-bits, so nodes can have no more than 232 - 1 sub-terms. The sub-terms of a node are indexed by 1 through nSubterms. The zero index refers to the label of the node. A typical implementation on a 32-bit machine could use a structure like that shown in Figure 1 to represent a MathBus node. In languages without pointers, a completely different implementation might need to be used.
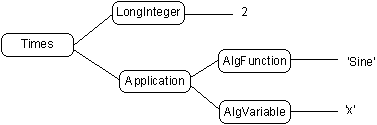
Figure 2. Sample MathBus Term
For example, an algebraic expression like 2 sin x is represented as the tree shown in Figure 2. The nodes are labeled by identifiers that indicate the operation represented. Thus, the expression is a product of two terms. The first is a LongInteger expression (a rational integer) whose value is the integer 2. The second sub-term is an Application expression, whose two sub-terms are the function to be applied (sin) and the argument to the function. Using a parenthesized syntax we have
(Times (LongInteger 2) (Application (AlgFunction 'Sine') (AlgVariable 'X')))
Although MathBus sub-terms can be integers (within the range 0 to 232 - 1), rational integers (the mathematical concept of integers of arbitrary size) are contained in a node that labels the value as an integer. Mutable strings are handled the same way, with String identifiers reserved for commonly occuring strings. Applications that use strings heavily, like a digital library project would also use the special String nodes. Thus all full fledged MathBus "objects" are labeled by their type.
Within this document, 32-bit unsigned integers are represented by their decimal notation, but in a typewriter font: "163". Nodes in the term structure are represented by a parenthesized list consisting of the symbolic label of the node followed by the sub-terms of the node. For instance,
(Basket (Apple 2 3) (Eggs 12))
represents a term labeled Basket, consisting of two sub-terms labeled Apple and Eggs respectively. The Apple sub-term contains two other sub-terms, each of which is a 32-bit integer. The Eggs sub-term has only one sub-term. Since the term structure only represents trees, this recursive parenthesized structure described can represent all MathBus terms. However, there are five types of terms that we write differently for extra clarity and conciseness.
String identifiers, which are 32-bit integers, are always shown as their corresponding string, surrounded by single quotes. Fro more information about string identifiers see the registry section.
Nodes of type String are sequences of Unicode characters packed into a number of 32-bit words. To make the strings more intelligible, they presented as a sequence of characters surrounded by double quotes, for instance "A sample string". To permit input and output of Unicode characters on devices that cannot manage the full Unicode character set, escpae sequences of the form "\uXXXX" may be used, where "XXXX" must be a four character hexidecimal number. A string of the six characters "\uXXXX" may be represented as "\u005CuXXXX" where "\u005C is the Unicode identifier for a backslash. A table of the useful Unicode characters is contained here.
LongInteger nodes are used to represent signed integers of arbitrary size. Rather than indicating their internal structure, we show their value surrounded by square brackets so that they can be distinguished from short, 32-bit integers. Thus [163] is a node labeled LongInteger with a single sub-term containing the single 32-bit integer 163.
IEEEFloat nodes are used to represent 64-bit floating point numbers. They are also printed within square brackets, for similarity with long (boxed) integers. Thus the term
(CarVelocity "xyzuvw" [163] [3.1415926])
represents a term consisting of three sub-terms, the first of which is a String, the second is a LongInteger and the third is an IEEEFloat.
MBVariable nodes are indicated by their strings surrounded by square brackets, such as [RepeatedTerm].
A modest amount of information must be maintained about the MathBus terms to facilitate their use. This information consists of (1) the mapping between strings and string identifiers and (2) which sub-terms of a node are themselves sub-terms and which are 32-bit integers or string identifiers. The MathBus term structure assumes that the pattern of sub-term types is the same for all nodes with the same node label. So, the information about the types of the sub-terms is a mapping between node labels and a "SubTypes" value.
This information is maintained in a system called the MathBus
Registry. The MathBus registry provides a mapping between
pairs of strings and 32-bit integers. The first string is called
an identifier and the second a registry type. These
strings are Unicode strings that consist only of alphabetic and
numeric characters. The initial character in these strings cannot
be a number. The equivalence test for strings in the registry is
insensitive to the case of the characters, although case may be
preserved for printing. Since the strings are Unicode strings
they may include symbols like ![]() and
and ![]() . Triples of an identifier string, a registry type
string and a 32-bit integer are called registry entries.
Registry types are represented as strings to provide for future
flexibility.
. Triples of an identifier string, a registry type
string and a 32-bit integer are called registry entries.
Registry types are represented as strings to provide for future
flexibility.
Figure: MathBus Registry Types
| Identifier | Registry type | Direction | Brief Description |
|---|---|---|---|
| String | StringId | <=> | String is a Unicode string that is associated with the given 32-bit value. |
| String | SubTypes | => | When used as a node label, this value indicates the types of the sub-terms of the node. |
There are two types of registry entries, corresponding to the two types of information mentioned above. The one-to-one association between the string identifiers and their corresponding 32-bit integer is indicated by the String registry type, while the types of the sub-terms of a node are encoded in entries of registry type SubTypes. This is summarized in above table.
Some of the information in the registry is global, for instance the numeric label corresponding to Void or Null. Other information is only used by a particular term, such as the string 'Icosahedron' which might be used by terms that represent geometric objects. We call the first type of data global registry information and the second local registry information. For simplicity, global string identifiers that do not have corresponding SubTypes fields cannot be converted to node labels by adding a SubTypes entry to the local registry. String identifiers that are global lie in the range 0x00000000 through 0x00FFFFFF Local identifiers may allocated from the range 0x01000000 through 0xFFFFFFFF.
The SubTypes Registry Entries section describes the semantics of the SubTypes entries in the registry. A representative procedural interface to the registry is described in the Procedural Interface section. Finally, the format of an ASCII file that contains the global registry information is documented in the File Format section.
For a given, it is necessary to know which sub-term is a 32-bit integer, string identifier or a reference to another node. This information is coded in the SubTypes properties in the registry. To simplify the identification, we require that any 32-bit sub-terms be either the lowest indexed sub-terms in a node or else they can alternate with references to other nodes.
Figure: SubTypes field definitions
| SubTypes | Description |
|---|---|
| n | For positive n the first n sub-terms are integers and the rest are nodes references. |
| 0 | All of the sub-terms are references to nodes. |
| -1 | All sub-terms are integers. |
| -2 | The first term is node reference and the rest are 32-bit integers. |
| -3 | The even indexed sub-terms are 32-bit integers and the odd indexed sub-terms are references to nodes. |
| -4 | The odd indexed sub-terms are 32-bit integers and the even indexed sub-terms are references to nodes. |
| -5 | The first sub-term is a string identifier and the remaining sub-terms are references to nodes. |
| -6 | The even indexed sub-terms are string identifiers and the odd indexed sub-terms are references nodes. |
| -7 | The odd indexed sub-terms are string identifiers and the even indexed sub-terms are references to nodes. |
| -255 | An illegal SubType. This value is reserved to aid detecting errors. |
The above table gives the currently allowable SubTypes properties and their meanings. The meanings of the negative values is rather ad hoc. We have included those combinations of node references, 32-bit integers and string identifiers that have been encountered while developing the level-2 specifications.
All implementations provide some interface to the registry. To illustrate this interface, and to provide standard names for the interface functions we list some basic functions for extracting information from the registry and inserting new information into the registry. The lookup functions could fail if the requested information is not contained in the registry, and the store function can fail if the registry is full or if the new information conflicts in some fundamental way with old information. Implementations in different languages can handle these exceptions in different ways-throwing exceptions, returning special values, or otherwise.
RegistryLookupValue identifier RegistryType [Function]
Returns the value stored in the registry for this identifier.
RegistryLookupIdentifier RegistryType Value [Function]
For those registry types that are declared to be bi-directional (i.e., StringId), returns the unique identifier string that has this value.
RegistryStoreLocal identifier RegistryType Value [Function]
Assigns Value to the RegistryType property of identifier in the local copy of the registry. This operation does not update any global information.
RegistryStoreGlobal identifier RegistryType Value [Function]
Assigns Value to the RegistryType property of identifier in the global registry. This operation is not likely to be implemented in the near future since a global registry service is not yet planned.
A node with RegistryStoreLocal label is used to indicate changes to the local registry. This node label is used when writing a MathBus term that contains local registry information to a stream . For instance, a new local node label is introduced and a term that uses that label is transmitted to another task, then the registry information about the local node label must also be included with the term.
![]()
RegistryStoreLocal identifier RegistryType
Value
Assigns Value to the RegistryType property of identifier in the local copy of the registry. This operation does not update any global information. The identifier and RegistryType sub-terms are strings, while the Value sub-term is a 32-bit integer. The value is that of the sending program. The receiving program is responsible for allocating new values if necessary. This is discussed in more detail in the section Preparing Terms for Transmission.
The contents of the registry is stored in an ASCII file that is shared among all implementations of the MathBus terms structure. The format of this table is quite simple. Any text beginning with a semicolon (;) through the end of the line is ignored and may be used for comments. Each line of the file can either be blank (although perhaps containing a comment) or contain the information for one registry property. White space is interpreted as a item separators. Each line contains three values:
This file is can used to generate header files for different languages and/or to initialize the state of the MathBus registry in applications.
The initial segment of the registry file is listed below. This segment defines the Void and Null operators.
Void String 0x00000000Void SubTypes 0 Null String 0x00000001 Null SubTypes 0Special Node Labels
The MathBus term structure predefines a few node labels that are needed for bookkeeping, support of directed acyclic graphs and sub-terms that are loaded or created on demand. These labels are described below. A one line summary of each label is given first. The name of the label is first given in a typewriter font, followed by the sub-terms of the node in italics. At the end of the summary line, within brackets, is an identifier that identifies the type of the node. The most common identifier is Node, which is used to indicate that a label for a MathBus node. Global node labels that are defined by different Level 2 packages are labeled by the name of their package, e.g. Algebraic Node, Geometric Node, etc. The identifier Command indicates a node label that is used when transmitting MathBus objects between processes or storing terms in persistent storage. These nodes cause side effects to the state of the MathBus environment when they are encountered.
![]()
Void junk1 junk2
… junkn
Void nodes are not intended to be used, but the
label is allocated for error checking. The numeric value of a Void
node is 0. When any iterator or storage operation encounters a Void
node an error is signaled and the sub-terms of the node are
ignored.
![]()
Null
A Null node is an empty node without any
sub-terms. Implementations may choose to implement Null
nodes as a null pointer.
![]()
String charcnt chars1 chars2
… charsn
All strings are represented as String nodes. The
first sub-term of a String node is the number of characters it
contains. The remaining sub-terms of a String
node are 32-bit integers, into each of which are packed two
Unicode characters (or two ASCII characters in the early
prototypes). The character in the most significant 16-bits
precedes the character in the least significant 16-bits. Thus, charcnt
will be either twice the number of sub-terms used to hold
characters or one less if the last the sub-term only contains a
single character.
![]()
LongInteger Digit1 Digit2
… Digitn
Long integers are represented as a sequence of base 1,000,000,000
32-bit integers where the sign of Digit1 is
sign of the entire integer. The use of this format uses most of
the information available in the digits, makes it easy to
translate between human readable numbers and MathBus terms and
finally is not too inefficient for actual arithmetic.
![]()
IEEEFloat int1 int2
Represents an IEEE floating point number. The high 32-bits of the
representation appear in int1, the low 32-bits
in int2.
Nodes of this type are used when it is necessary to create a reference to a floating point number. Most nodes that can contain large quantities of floating point numbers (for example, vectors and matrices) use pairs of 32-bit integers to store them. However, occasionally we need to insert a floating point number as a sub-term of a node that only allows nodes as sub-terms. In this case the IEEEFloat node can be used "box" the floating point number.
![]()
RemoteNode RemoteType node data1
… datan
It is sometimes necessary to maintain a reference to a term,
without necessarily having a direct pointer to the term. Examples
include references to terms that remain on disk and references to
terms that have not yet been computed. Nodes of this form can be
represented using the RemoteNode label.
If at some later time the node is actually created, then a
reference to the node is stored in the node slot.
Otherwise, the node slot contains a Null
node.
The RemoteType field indicates how the remote data can be used to create the node if necessary. The following table contains the initial set of values available for the RemoteType slot. It is expected that with more experience with the MathBus term structure additional remote types will be created.
| Remote type | IntCode | Functionality |
|---|---|---|
| RemoteURL | 0 | The data corresponding to this node is stored in a file. This file is identified using a URL style string of the form, "//host/pathname". This string is stored in the data words of the remote object packed, four characters to a sub-term, most significant byte first. |
| RemoteFuture | 1 | Something that remains to be computed, and will be computed by another machine. |
| LocalFuture | 2 | Something which remains to be computed, but that will be computed locally. |
Instead of increasing the size of every node to provide potential space of annotations, the MathBus provides "attribute" nodes that serve as transparent containers for a term and the term's associated attributes. When iterators encounter an attribute node they note the attributes and proceed to the node itself, so that the attribute node is transparent to the user. However, the attributes themselves are accessible and can be read, written and deleted. Attributes are used to tag an algebraic node with the algebraic domain of which it is a member, and can be generally used to transparently associate types with nodes.
![]()
Attributes node AttributeId1
Attribute1 … AttributeIdn
Attributen
Nodes of this type are used to transparently attach information
to a node. The iteration functions described in the different
language sections and summarized in section Iterator Structure
provide ways of accessing and modifying a node's attributes
without actually needing to expose the attribute structure. The AttributeIdi
sub-terms are 32-bit integers that refer to identifying strings
mentioned elsewhere.
![]()
OrderedCollection elt1 elt2
… eltn
Ordered collections are ordered sets of MathBus term structures.
They are often used to when more than one term needs to be passed
between processes, as a group. There can be up to 232
- 1 elements in a ordered collection.
This section documents the basic libraries provided in each programming language. These libraries include a hash code library that computes a canonical, architecture invariant hash code for term, a stream I/O library that converts a term structure to and from a byte stream, and an iterator library that allows one to apply a function to each sub-node in a term structure.
A very common mechanism used in symbolic computation is to use a hash code obtained from the expression as an index for quick comparisons, searches and generally to manage collections of symbolic expressions. To simplify use of the MathBus term structure, a hash coding algorithm is specified and an implementation provided. This algorithm is specified so that hash codes computed on one machine may be used by other machines.
There are two parameters to the hash coding algorithm, the maximum depth of the MathBus term that is examined and the maximum sub-terms examined of each node when computing the hash code. For this release of the MathBus term structure both of these constants are equal to 7. In future releases, when we have more experience with the hash coding structure the may be changed to produce better hash codes or to make the hash coding process more efficient.
The hash coding algorithm is quite simple. The hash code of each of the sub-terms of the node is computed recursively. The 32-bit hash codes of these sub-terms are then rotated (low bit positions to high bit positions) according to their position. Thus the hash code of the sub-term indexed by zero (the numeric node label) is left unchanged, that indexed by one is rotated one bit position to the left, that indexed by two, two bit positions and so on. (Note that the hash code of the thirty second sub-term is left unchanged, and that of the thirty third is only rotate by a single bit position.) These values are then pair-wise logically XOR'ed and the resulting 32-bit value is returned.
During the traversal of the term, certain special node labels are given special handling. When nodes labeled MBVariable are encountered, then the meaning of the variable is hash-coded, not the MBVariable term. Thus the hash-code of a directed acyclic graph will be the same as that of the corresponding tree, with shared nodes replicated. Nodes labeled Bind have the same hash code as their body terms.
The tools discussed in this section transform MathBus terms into an architecture independent sequence of printable ASCII bytes. These byte sequences can be stored in files, embedded in mail message or exchanged among processes written in different programming languages and/or running on machines with different architectures. The MathBus terms can then be reconstructed from the byte streams. All implementations of the MathBus term structure, in all programming languages (C++, Java, Lisp and ML will be soon available), will use the same byte stream specification.
The MathBus byte stream has three components: a fixed size header structure, the body of the stream and a fixed size trailer. The header of the byte stream identifies byte stream as a MathBus byte stream and provides some initialization information. The byte stream's trailer contains check-sum information. The body represents a modified version of the term that is being transmitted. Because the term that is being transmitted may refer to information that is maintained in the local registry, this information must be in included in addition to the term itself. The process by which this is done is described in the section Preparing Terms for Transmission.
Since all MathBus terms are represented by trees, the byte stream can be processed by a stack based process, which we call the byte stream processor. When generating a byte stream processor converts the MathBus terms into a sequence of 32-bit words. These 32-bit words are coded into a compact sequence of 8-bit bytes, where small integers are efficiently coded. Finally, this sequence of bytes is converted into a sequence of printable ASCII text (Base64), which is the final form of the byte stream. In section 32-bit Structure of Byte Stream we discuss how the MathBus term structure is converted into a sequence of 32-bit integers, and section Base64 Conversion we discuss the final conversion to Base64 format.
When transmitting a MathBus term, which we call the content term, any references to information contained in the local registry must be extracted and included with the term that is being transmitted. In addition, any references to global variables contained in the context must also be de-referenced. This is done by making the content term the last sub-term of a Sequence node, where all of the preceding sub-terms are RegistryStoreLocal or GlobalAssign terms.
The information that appears in this sequence is generated as follows.
| Node Type | Action |
|---|---|
| Local Node Label | Determine the corresponding symbolic label and include two RegistryStoreLocal commands-one each for the String and one SubTypes entries. |
| Local String Identifier | A RegistryStoreLocal command is included to indicate that a local string identifier has been encountered. |
| Global Variable | Include a MBGlobalAssign command. At some point, the value included could be a RemoteNode so that the data would only be transmitted on demand. |
When a term is received, the RegistryStoreLocal commands are handled a little carefully. However, if the registry type is String then local numeric string identifiers must be allocated and the numeric values present in the transmitted term must be converted to the local numeric values on the receiving machine. If the registry type is SubTypes then the three sub-terms are immediately passed to the function RegistryStoreLocal, since no translation is necessary.
[Still need to deal with contexts. Otherwise where will the GlobalAssign's go?]
The header structure consists of three 32-bit unsigned integers. The first is the constant 0xFADEBAC0, which identifies this as a version 1.0 MathBus term. The second of these numbers is at least as large as the number of sub-terms at any node of the MathBus terms about to be transmitted. The third is at least as large the maximum depth of any MathBus term to be transmitted. These two numbers may be used to initialize the byte stream processor's internal data structures.
The body of the byte stream is a sequence of 32-bit words that represent a single MathBus term. (Multiple terms can be handled using the OrderedCollection node and perhaps GlobalAssign terms.)
Conversion of a term proceeds in a depth first fashion. First two 32-bit words are emitted. The first contains the node's label and the second is the number of sub-terms of the node. Next the byte stream for the first sub-term is emitted, followed by that for the second sub-term and so on. The leaves of a MathBus tree are 32-bit unsigned integers and are emitted without any transformation. For instance, assume the node labels LIST1 and LIST2 are associated with the numeric values 0x10FAD100 and 0x10FAD200 respectively. Ignoring the header and trailer information, the byte stream used to represent the term
(LIST1 0xABCD (LIST2 0x1234 0x5678) 0xCAFE)
would be:
< 10FAD100 00000003
0000ABCD
00FAD200 00000002 00001234 00005678
0000CAFE >
where all of the numbers above are in hexadecimal. Which sub-terms of a node are integers and which are themselves nodes can be determined by referring to the SubTypes entry of the node label in the registry.
Throughout the processing of the incoming byte stream, a 32-bit checksum is maintained. This checksum is the last four bytes of the byte stream. Actually, we should probably use the NIST Secure Hash Standard for the checksum/digest instead. This is more robust and it is standard.
The sequence of 32-bit words generated by the above process is first converted into a sequence 8-bit bytes and then the byte sequence is converted into a sequence of ASCII printable characters which is the final form of the byte stream. The simplest approach would be to convert each 32-bit word into a sequence of 4 bytes, but this would be inefficient since so many of the 32-bit words have a large number of leading zeros. Recall that each node contains a count of the number sub-terms in a node, and this is most often quite small. Consequently, a simple coding scheme is used to minimize the space used by small 32-bit numbers. The precise conversion is given in the following table.
| 32-bit number | byte sequence |
|---|---|
| 0x0000 0000 - 0x0000 00FC | B1B2 |
| 0x0000 00FC - 0x0000 FFFF | FD B1B2 B3B4 |
| 0x0001 FFFF - 0x00FF FFFF | FE B1B2 B3B4 B5B6 |
| 0x0100 FFFF - 0xFFFF FFFF | FF B1B2 B3B4 B5B6 B7B8 |
The binary byte stream just discussed is then encoded using the MIME (RFC 1563) Base64 coding scheme. This scheme codes sequences of three 8-bit bytes into four 6-bit bytes that are represented as a printable characters. Although this approach increases the size of the byte stream by 33% it also ensures that the byte stream will not be corrupted by operating system specific conventions such as the end of line convention used. The mapping of six bit bytes into printable characters is given by the following table.
| 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | |
| +00 | A | B | C | D | E | F | G | H |
| +08 | I | J | K | L | M | N | O | P |
| +16 | Q | R | S | T | U | V | W | X |
| +24 | Y | Z | a | b | c | d | e | f |
| +32 | g | h | i | j | k | l | m | n |
| +40 | o | p | q | r | s | t | u | v |
| +48 | w | x | y | z | 0 | 1 | 2 | 3 |
| +56 | 4 | 5 | 6 | 7 | 8 | 9 | + | / |
In addition, an "=" is used to indicate situations when the sequence of eight bit bytes is not an even multiple of six bit bytes. In particular, if the number of bytes in the sequence is exactly a multiple of 3 then nothing is added. If there is one 8-bit byte left at the end of the 8-bit byte stream then a single "= " is appended. If there are two characters left, then two "=" characters are appended.
The iterator mechanisms provides tools that allow one to apply a supplied function to every sub-node in a term. At each invocation information is made available about bound variables. At the moment the we do not have a language independent specification of the different iterator structures, but there are specifications of the iterators that we have implemented in the language specific specifications elsewhere.
The simple term structure contained in the level 0 definitions of the MathBus term structure suffice for many applications, but for many situations additional mechanisms are needed within the data structure itself.
The basic term structure is only capable of representing trees. To represent more complex structures, the MathBus term structure includes a mechanism that allows one to name terms and then, by referring to these names, reuse the named terms one or more times in a larger term. The "names" used are nodes given the label MBVariable. A "binding" mechanism is also provided that restricts the scope of these variables. In addition, variables may have global values. These global values are maintained in a context.
![]()
MBVariable strId
Procedural variables are terms constructed with the MBVariable
operator. The StrId is a string identifier used to
identify the variable. To ease allocation, the string identifiers
'Temp00' through 'Temp99' are
predefined in the global registry. The MBBind and
MBGlobalAssign terms are used define binding
scopes for procedural variables. The MBBind
statement declares the variable to have local scope, while MBGlobalAssign
gives the variable global scope.
The Bind term is used to give temporary variables meaning. The Bind statement is also used to declare the scope of a temporary variable. A term that uses a temporary variable whose scope has not been declared, or which is used outside of its declared scope is ill-formed.
Procedural variables are used to allow the tree structure provided by the MathBus term structure to be used to represent directed acyclic graphs. The globally bound variables allow sub-terms to be shared among different terms.
![]()
MBBind var1 val1
… varn valn term
The Bind term is used to declare the scope of
one or more temporary variables and gives them initial meanings.
The meaning of a Bind term is the meaning of its
term. Thus, the term
(MBBind [Temp00] (Application (AlgFuncCode 'Sine') (AlgVariable 'x')) (Plus [Temp00] [Temp00])
has the meaning
(Plus (Application (AlgFuncCode 'Sine') (AlgVariable 'x'))
(Application (AlgFuncCode 'Sine') (AlgVariable 'x')))
Standard lexical scoping rules are used when binding temporary variables, so
(MBBind [Temp00] (Application (AlgFuncCode 'Sine') (AlgVariable 'x'))
(MBBind [Temp00] (Application (AlgFuncCode 'Cosine') (AlgVariable 'x'))
(Plus [Temp00] [Temp00]))))
has the meaning
(Plus (Application (AlgFuncCode 'Cosine') (AlgVariable 'x'))
(Application (AlgFuncCode 'Cosine') (AlgVariable 'x')))
where the two sub-terms are the same, not just copies of each other. When more than one variable is bound using a single MBBind term, the variables should be thought of as being bound simultaneously. Thus, none of the variables being bound can be used to define the meanings of other variables in a single MBBind term.
![]()
MBSelectContext
ContextID
This term is only used when transmitting terms and
within the Sequence term. It
indicates which context should be used when looking up variables
that are not bound by a MBBind term. If no
context with the indicated ID exists, one will be allocated.
![]()
MBGlobalAssign
variable term
The MBGlobalAssign command checks to see if
there is lexical binding of variable (using MBBind),
and if so signals an error. If there is not a global binding of variable
then one is created. Finally, the global binding of variable
is modified to be term.
![]()
Sequence Term1
Term2 … Termn
The simplest of the programming language terms is the Sequence
term. The meaning of this term is the meaning of Termn.
The earlier terms are used to cause side effects using command
nodes like SelectContext and GlobalAssign.
The Level-2 term structure introduces semantics for the node labels so that the term structure can represent different types of mathematical expressions. These labels and their semantics are described in the following three sections: the Algebra and Analysis page describes the node labels for describing mathematical objects from algebra and analysis, the Geometry page gives the node labels for geometry and topology and the Logic page describes those terms for use in logic. In addition to providing the semantics of the node labels for these areas of mathematics, libraries will also be provided to allow some standard functionality for these mathematical objects. These libraries at least include tools for reading and writing the file formats of foreign applications (e.g., AutoCAD) as well as some small set of mathematical operations.
There are many places within the level-2 term structure that involve some sort of binding mechanism. The summation and integration operators in algebra are examples of this. Whenever an iterator is defined for terms, special handling is required to deal with these bindings. In order to encourage more uniformity in the binding structures used by level-2 specifications, and to facilitate code re-use, a binding mechanism is defined that can be used by all of the different level-2 specifications. Of course, use of this term is not obligatory, and if other mechanisms are preferable for a particular domain they should be used.
The basic node label that is used to declare a binding is the "Lambda." Although no typing information is explicitly included in the term, it may be added as an attribute of the variable.
![]()
Lambda label term var1 … varn
Indicates that within term the "variables" var1
… varn are used as bound. The
structure of these variables is not specified here. The label
sub-term, which is a string identifier, is used to indicate the
particular semantics of this binding expression. Thus, the
algebra and analysis bindings use the label 'AlgFunction' to indicate this is an
algebraic function.
The Application node is used to indicate that when "bound variables" are given values. Remember that the meaning of variables and binding is not specified at this level but is specific to the different level-2 domains of discourse.
![]()
Application FuncTerm term1
… termn
Applications are used to indicate when one term is to be applied to one or more other terms. This operator can be used for mathematical special functions using AlgFuncCode nodes with one of the special function identifiers. However, the function term is not limited to special functions and may also be operators such as the definite integral, summation and product terms used in algebra and analysis. 3.4
A it is often necessary to provide values for some subset of the bound variables of a term. This is most conveniently indicated by a combination of the 'Lambda' and 'Application' nodes. For example, the Bessel J function is function of two arguments, the first of which is called the "order" of the function. The following expression is a function of one argument which is the Bessel J function of order 3.
(Lambda 'AlgFunction' (Application (AlgFuncCode 'BesselJ')
[3] (AlgVariable 'x'))
(AlgVariable 'x'))
Bindings exist for a number of different domains of mathematics. The following lists the currently specified bindings.