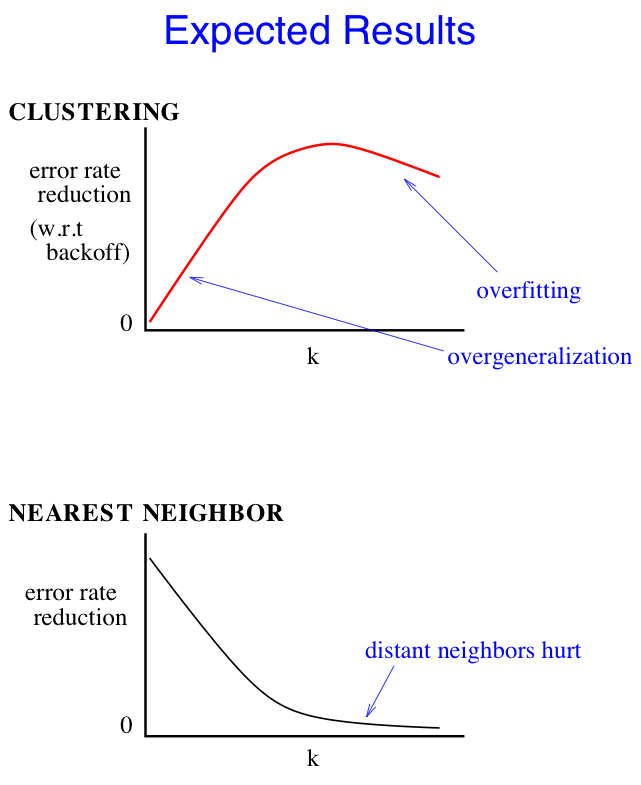
Distributional similarity is a useful notion in estimating the probabilities of rare joint events. It has been employed both to cluster events according to their distributions, and to directly compute averages of estimates for distributional neighbors of a target event. Here, we examine the tradeoffs between model size and prediction accuracy for cluster-based and nearest neighbors distributional models of unseen events.
@inproceedings{Lee+Pereira:99a, author = {Lillian Lee and Fernando Pereira}, title = {Distributional similarity models: Clustering vs. nearest neighbors}, year = {1999}, pages = {33--40}, booktitle = {Proceedings of the ACL} }