A4: Search

In this assignment you will develop a search engine for text documents. Your engine will crawl through a directory on a local disk looking for documents and answer queries posed by users.
In the past, students have typically found this assignment more difficult than A3. For Spring 2020, we have removed some of the more difficult components and are allowing more time to complete it. Nevertheless, it’s a good idea started early and make steady progress rather than leaving it all until the last minute. Please track the time that you spend on the assignment. We will ask you to report the number of hours in your submission.
What you’ll do: Implement some functors involving a dictionary type.
Objectives:
- Learn more about the OCaml module system.
- Implement data structures for sets and dictionaries several ways, including red-black trees.
- Practice documenting and implementing abstraction functions and representation invariants.
- Optionally, learn about glass-box testing and measure performance.
Table of contents:
- Warning about Academic Integrity
- Step 1: Form a Partnership on CMS
- Step 2: Get Started
- Step 3: Dictionaries
- Step 4: Sets
- Step 5: Query
- Step 6: Red-Black Trees
- (Optional) Bisect
- (Optional) Performance Testing
- (Optional) Removal from Red-Black Trees
- Rubric
- Submission
Warning about Academic Integrity
Part of this assignment involves implementing some well-known data structures. In the vast expanses of the Internet, there might be an implementation of every known data structure in every known programming language. So it’s conceivable you could just Google for the solutions to certain parts of this assignment. Well, we’ve already done that ourselves and put the results in MOSS, the plagiarism detection software we use. Don’t search for solutions. Just don’t. Once you see someone else’s solution, even just some types or signatures of helper functions, it’s impossible to unsee it; you will almost certainly write code that is too similar to theirs even if you do not directly copy it. A low grade on this assignment is still better than failing the course, which is what could happen if you cheat.
Step 1: Form a Partnership on CMS
We recommend that you complete this assignment with a partner, but it is not required. Having a partner is not needed to complete the assignment: it is definitely do-able by one person. Nonetheless, working with another person is useful because it gives you a chance to bounce ideas off another person, and to get their help with fixing faults in your code. See the discussion of “pair programming”, below, for more details.
→ If you do have a partner, you must read the Partner Policy. ←
The deadline to form a CMS partnership is Monday, April 13, at 11:59 pm. There will be a short grace period. Then the assignment will close for a few hours. On Tuesday, April 14th, we will re-open the assignment, but you will no longer be able to form new partnerships. Instead, you will have to email one of your section TAs, Cc’ing your intended partner. The TA can then manually put the two of you into a CMS partnership. However, there will be a penalty for late partner formation: -5 points on Tuesday and -10 points on Wednesday. The penalty applies to both partners (no exceptions). Starting on Thursday, April 16th at 12:01 am, no new partnerships may be formed.
Why do we have this early partner formation deadline, and the penalties? It’s to make sure you are working with your partner on the entire assignment, as required by the Partner Policy, rather than joining forces part way through.
If you want to split up with your partner before the final assignment
deadline, you must acknowledge their influence on your work in the
Authors interface. You may form a new partership, subject to the
deadlines and penalties stated above.
Pair Programming. If you have a partner, we encourage you to try out pair programming with them. Pair programming is a specific way for two people to write code together, and for both of them to own the result. Please watch this video, which explains the driver and navigator model of pair programming:
If you’d optionally like to read more about the benefits of pair programming, Strengthening the Case for Pair Programming by Williams et al. (2000) is a good place to start. It includes this quote:
For years, programmers in industry have claimed that by working collaboratively, they have produced higher-quality software products in shorter amounts of time. But their evidence was anecdotal and subjective: “It works” or “It feels right.” To validate these claims, we have gathered quantitative evidence showing that pair programming—two programmers working side by side at one computer on the same design, algorithm, code, or test—does indeed improve software quality and reduce time to market. Additionally, student and professional programmers consistently find pair programming more enjoyable than working alone. Yet most who have not tried and tested pair programming reject the idea as a redundant, wasteful use of programming resources: “Why would I put two people on a job that just one can do? I can’t afford to do that!” But we have found, as Larry Constantine wrote, that “Two programmers in tandem is not redundancy; it’s a direct route to greater efficiency and better quality.”
Note that even though we are distributed around the world this spring, pair programming over Zoom works remarkably well.
Step 2: Get Started
Download the release code. There are many files, and you will need to read many of them before the assignment is over, but you don’t have to do so yet.
Create a new git repository for this assignment. Make sure the repo is private. Add the release code to your repo, referring back to the instructions in A1 if you need help with that. Make sure you unzip and copy the files correctly, including hidden dotfiles, as described in the A1 handout.
If you are using a partner, grant them access to the repo:
- Go to the repo’s webpage on the COECIS Github.
- Click “Settings”; on the settings page click “Collaborators”, and type your
partner’s NetID into the search box. Click “Add collaborator”. - Your partner should now click on the GitHub icon on the top left in their own browser. They should see the repo you just created listed on the left as a repo to which they have access.
In the release code, there is a makefile provided with the usual targets: build, test, check, finalcheck, zip, docs, and clean.
This assignment will be autograded, so your submission must pass make
check. Now that you’re used to working with .mli files, we have
omitted the comments about what you are allowed to change. Any names
and types that we provide in an interface may not be changed, but you
may of course add new declarations and definitions. If you’re ever in
doubt about whether a change is permitted or not, just run make
check: it will tell you whether you have changed the interface in a
prohibited way.
Step 3: Dictionaries
The most important data structure that your search engine will need is a dictionary—that is, a mapping from keys to values. In this assignment, we’ll keep it simple and implement a dictionary using an association list (which you can read about in the textbook). If you attempt excellent scope, we’ll upgrade it to a more efficient implementation.
First, read the interfaces in dictionary.mli. There are a few
advanced OCaml features used in them that you might not recognize, so
we briefly describe them here:
-
The
Formattable.formatfunction is a custom printer intended for use by the toplevel. Custom printers are discussed in the textbook in the section on abstract types under the heading “Custom Printers”. -
Some signatures have code like
include Sig with type t := t. This is a destructive substitution. You don’t need to know how to use this yourself. Essentially, it means that the typetinsideSigshould be replaced with the typetfrom the surrounding signature. For more information, see the OCaml manual. -
DictionaryMakeruses module sharing constaints; we previously saw type sharing constraints in the textbook and in recitation. There’s nothing fundamentally different between those two kinds of sharing constraints: both refine a signature by specifying equations that must hold.
Second, read the interface in listDictionary.mli. All it does is
include the Dictionary interface and declare a functor.
Next, complete the code in listDictionary.ml, following the
specifications and comments provided in the starter code. Using
test-driven development, also implement unit tests for
ListDictionary in test.ml. We will not be assessing how many test
cases you have until the excellent scope, below, so see there for
details.
Be extra careful to use the comparison operator provided by the
KeySig, not Stdlib.compare (nor the built-in comparisons <,
<=, =, etc.), when comparing keys. Otherwise your dictionary will
not process keys in the right order, and you will lose points.
The file exampleDictionary.ml contains an example of how to create a
dictionary. That file is intended to be loaded in utop with #use,
not to be compiled with ocamlbuild.
Note that you need to document and implement an abstraction function and any
representation invariants. The documentation goes above the representation
type. The implementations go in format and rep_ok, respectively:
-
There is a helper function
format_assoc_listprovided for you in the starter code; it should be helpful in implementingformat. You may improve its output in any way you wish. -
How to implement
rep_okis discussed in the textbook in the section on implementing representation invariants. You are not required to insert calls torep_okthroughout yourListDictionaryimplementation, but you might find it useful for debugging purposes.
You do not need to have OUnit tests for format or rep_ok. Indeed,
it would be hard or perhaps even impossible to write such tests.
Step 4: Sets
Your search engine will also need a data structure for sets. In this
assignment, we’ll use a dictionary to represent a set. The core idea
of this representation is that the elements of the set are the keys in
the dictionary. The values in the dictionary are thus irrelevant, so
they might as well simply be (), the unit value. Although there is a
bit of extra space overhead using this idea, because of storing the
unit value, it nonetheless provides a way to turn any dictionary
data structure into a set data structure. If you attempt excellent
scope we will profit from this design: when we will automatically get
an improvement in the performance of our set data structures by
upgrading our dictionary data structures.
Use that idea to implement dictionarySet.ml, specifically the Make
functor, following the specifications and comments provided in the
starter code. Also implement unit tests for it in test.ml. You will
want to carefully read the specifications in dictionarySet.mli.
This is the stopping point for a satisfactory solution.
Step 5: Query
Now that we have the data structures we’ll need, it’s time to implement the search engine itself. At a high level, the search engine finds the names of files that satisfy a given query, as discussed below.
Begin by carefully reading the specifications in engine.mli. We have
provided you with the index_of_dir function which indexes the words
found in files in the starter code. However, if you want to check the
implementation on the file alice.txt we have supplied, it should
have 3278 distinct words after conversion to lowercase.
Open engine.ml and implement the functions words, to_list, and
format in the Engine.Make functor, which produces a search engine
out of given implementations of dictionaries and sets. The
ListEngine module, which you don’t need to modify, uses that functor
to create a search engine based on the association list dictionaries
you created earlier. We suggest that you implement tests for
ListEngine in test.ml before proceeding to implement queries.
Now add support for queries. The queries that users pose will have one of two forms. Abstractly those two forms are as follows, in which the NOT clause is always optional:
-
“and-not” queries: AND (w1, w2, …, wn), NOT (u1, u2, … um)
-
“or-not” queries: OR (w1, w2, …, wn), NOT (u1, u2, … um)
For example, “AND (far, away)” would return all files that contain both the words “far” and “away”, whereas “AND (far, away), NOT (day, night)” would return all files that do contain both “far” and “away” but do not contain “day” nor “night”. Likewise, “OR (all, nothing)” would return any file that contains “all” or “nothing” (or both), and “OR (all, nothing), NOT (between)” would return any file that contains “all” or “nothing” (or both) but does not contain “between”.
Queries must be case insensitive, which is the behavior you expect from Google. That means queries for the words “far”, “Far”, and “FAR” should all return the same results. Likewise, a file containing “far”, “Far”, or “FAR” would be returned by any of those queries.
Implement and_not and or_not in engine.ml, and implement unit
tests in test.ml.
This is the stopping point for a good solution.
Step 6: Red-Black Trees
The primary performance bottleneck in your search engine so far is the association list used to implement dictionaries. In particular,
- the
findoperation on association lists runs in linear time; - the
insertoperation can be as fast as constant time (if you kept the list in unsorted order), but might be slower if you enforced stronger representation invariants (such as sorted order); and - the
removeoperation runs in least linear time—though that operation is not actually needed to implement the engine.
Let’s improve on that by implementing dictionaries with red-black
trees. They offer logarithmic time find, insert, and remove
operations. It’s the faster find operation that will dramatically
improve your search engine. Each node in your red-black tree will
store a single binding from a key to a value, and the tree will be
ordered according to the keys. That is, the binary search tree (BST)
invariant, which red-black trees must satisfy, will apply to the keys:
all nodes in a left subtree must have a key less than the key at the
parent, and all nodes in a right subtree must have a key greater than
the key at the parent.
Implement TreeDictionary by finishing the code in
treeDictionary.ml. But, you should omit remove for now. It is
considerably more challenging, hence will be left as an optional
exercise. If your engine.ml happened to use remove, you should
replace that code now with another algorithm that doesn’t require
remove. Otherwise you could end up not having a working tree-based
search engine, thus not even getting the points for the Satisfactory
scope.
You can update the example in exampleDictionary.ml to use
TreeDictionary instead of ListDictionary in case you would again
like guidance on how to create a dictionary in utop.
When you’ve finished implementing the tree dictionary, the
TreeEngine provided in the starter code will make use of the
Engine and DictionarySet modules you already completed to produce
a fast search engine. So, the only new piece of implementation for
this step is treeDictionary.ml, and the unit tests that you
implement for it in test.ml.
Tip 1. Consider building out your red-black tree in two phases:
-
First, build the representation type for red-black trees, but implement operations that are just the binary search tree (BST) operations, and only enforce the BST invariant. You could arbitrarily color all nodes as black or as red; it wouldn’t matter, because the BST algorithms don’t care about color.
-
Second, enhance your
rep_okandinsertoperations to enforce the red-black invariants.
Tip 2. As you test your tree dictionary and engine, you should be able to re-use your list-based tests. Consider not copy-pasting the tests, but instead using a functor to create a test suite. The input to that functor would be the structure that you want to test, and the output would be a structure that contains a list of OUnit tests. You can then pass that list to the OUnit test runner.
Tip 3. To use test-driven development, begin by commenting out all your tests you already created for lists. Then uncomment the tests for whatever operation you want to implement next. Implement it for trees. Make sure your trees and lists pass those tests. Repeat until all tests are uncommented.
Tip 4. Use rep_ok to help you. Implement it first. Make sure all
your tree operations check that rep_ok holds of inputs and outputs.
This strategy will make you a more productive programmer: you will
quickly discover your faults and fix them, rather than having to live
with mysterious or unknown faults. After all your tests are passing,
feel free to comment out your (probably expensive) implementation of
rep_ok and replace it with something like let rep_ok x = x, or
even
let debug = false
let rep_ok x =
if debug then (* your actual implementation *)
else x
Then later you could quickly re-enable rep_ok by changing debug
to true, if you suspected there was new fault you needed to
diagnose.
Note: Unlike tail recursion, which requires only constant stack space, the red-black tree algorithms require logarithmic stack space. That’s okay. You shouldn’t attempt to rewrite the tree algorithms to use constant stack space.
This is the stopping point for a excellent solution.
(Optional) Bisect
If you are interested in learning more about glass-box testing, here is an optional task you could complete. This task is provided purely for your enjoyment. It will not factor into your A4 grade in any way.
The textbook contains a tutorial on a tool called Bisect, which is a code coverage testing tool. Do that tutorial.
Now run make bisect on your solution. Open report/index.html and
examine the code coverage you have achieved in listDictionary.ml,
dictionarySet.ml, and engine.ml. It’s unlikely you are at 100%,
and probably it’s impossible to achieve that. For example, unit tests
are unlikely to ever exercise (all or any of) your format and
rep_ok functions. But outside of those, look for any lines colored
red by the Bisect report. Do your best to invent new unit tests that
will cause those lines to be executed. Add those tests to test.ml.
How high do you need to get your coverage? In an ideal world you would
cover every line that you know it’s possible to cover, or at least
that is feasible to write unit tests to cover. With modest effort, the
staff solution to this assignment was able to achieve 90-100% code
coverage in those three files, excluding format and rep_ok
implementations.
To exclude those, follow the instructions at the end of the textbook
tutorial in the section titled “Ignoring uncoverable code” regarding
BISECT-IGNORE comments. Depending on when you first read the
tutorial, you might not have seen that section; it was added just
before this assignment released.
Do not use BISECT-IGNORE to unfairly increase your code coverage
percentage. In limited cases beyond format and rep_ok it might
be fair to use BISECT-IGNORE. For example, if there is some
defensive code that checks a precondition and raises an exception if
it is violated, and it turns out to be impossible or infeasible to
write a unit test to trigger that exception, then you should add
additional source code comments to explain why it is reasonable to
ignore that code in the Bisect report.
(Optional) Performance Testing
If you are interested in seeing the difference in performance between your different implementations, the following describes an optional task you could complete. Again, this task is provided purely for your enjoyment and will not factor into your grade for A4 in any way.
First, run opam install csv. That will install a CSV library. You
aren’t required to use that library (in fact the staff solution
doesn’t), but some people in previous semesters wanted to use it, so
the release code this semester depends upon it.
Second, it is highly recommended for the Good scope of this assignment
to install an application named gnuplot. On Linux or Windows/WSL,
you can do that with sudo apt-get install gnuplot. On Mac OS with
MacPorts, you can do it with sudo port install gnuplot.
The reason you just implemented red-black trees was to get better performance. Probably you’ve already noticed that your tree-based tests run faster, especially on large directories. But how do you know that you actually achieved a logarithmic time implementation? Looking at individual running times doesn’t answer that question. Instead, you need to look at how the data structure’s operations scale as the number of items it contains grows larger.
Here are two graphs that show the scaling of list sets vs. tree sets
(i.e., a DictionarySet made from ListDictionary vs. a DictionarySet
made from TreeDictionary):
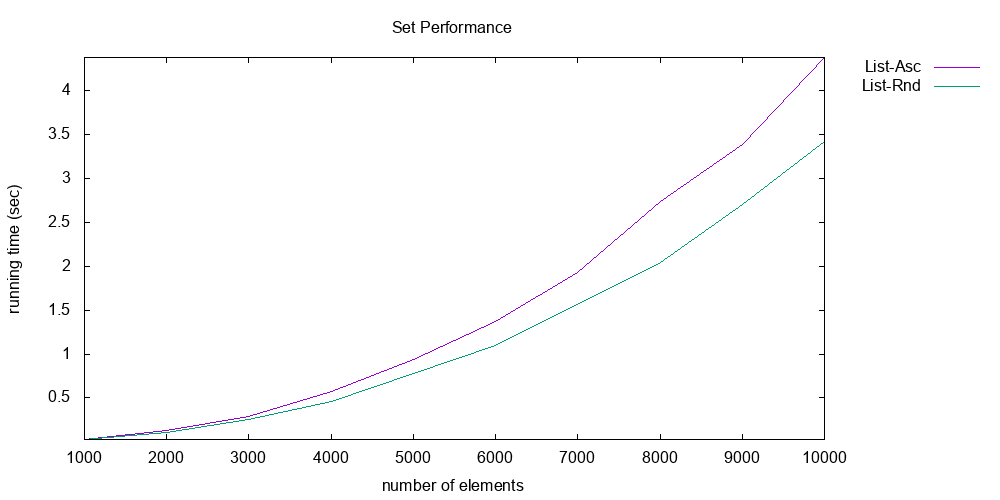
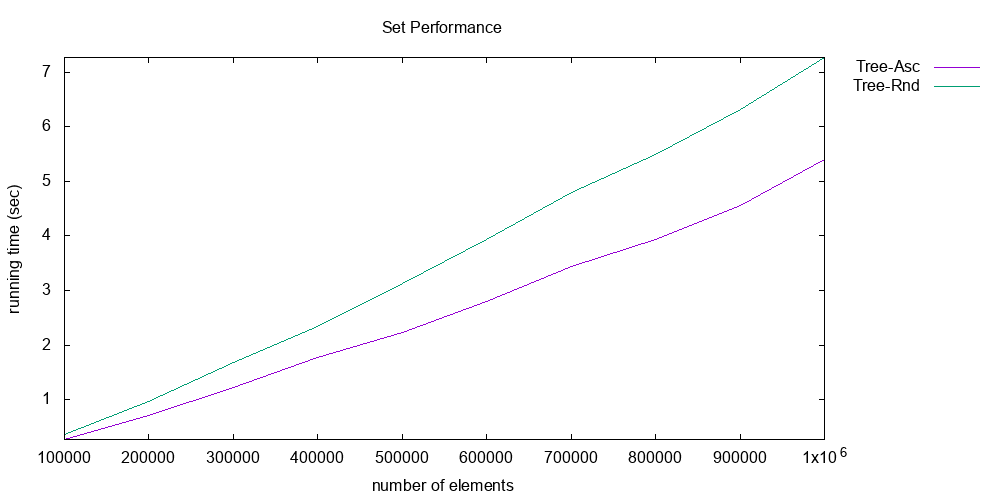
The first graph shows the performance of list sets; the second, tree sets. Note the axes of both graphs carefully: the y-axis is execution time in seconds, and is around 0-7 seconds for both graphs; whereas the x-axis is the number of elements in the set, and is quite different between the two graphs. For lists, the number of elements reaches only 10,000. For trees, it reaches 1,000,000.
The execution time being measured is the time it takes to do the following operations, where is the number of elements:
- Insert randomly chosen integers into the set.
- Do membership tests, where all those tests succeed.
Note also that there are two lines shown in each graph. These represent two different workloads: ascending vs. random. In the ascending workload, the elements are first sorted before being inserted. In the random workload, they remain in a random order. As we saw in lecture, the difference between a random workload and an ascending workload matters, because an unbalanced tree data structure would do poorly on the latter.
And every data point reported in the graph is actually the median of three repetitions of the experiment, in an effort to reduce noise.
The list graph clearly shows that the implementation is scaling quadratically: there are operations being performed, each of which is , for a total of work. But the tree graph is much better: each operation is only , so the total work is . That’s why the graph looks nearly linear, but has a slight upward curve. The list implementation does slightly worse for the ascending workload; that’s probably because the particular list implementation used in producing that graph keeps the list in sorted order, which causes every insert to take a full operations to walk down the whole list. The tree implementation does worse for the random workload; that’s probably because it triggers more rebalancing operations. But in both cases, the two workloads are fairly similar in execution time.
We produced those graphs by writing OCaml code that performs the
workloads and does the timing (see performanceTest.ml, which
contains a few useful definitions to help you get started). That OCaml
code wrote out CSV files with the results (see list_perf.csv and
tree_perf.csv, which are provided with the A4 starter code). We then
used a graphing utility, gnuplot, to create graphs from the CSVs
(see the plotting script perf.p).
Your task: Do that same analysis for your own implementation. That
is, produce two graphs, each of which shows those two workloads, for
the same maximum values on the x axis. The x-axis of list graph must
go to 10,000; and the tree graph; to 1,000,000. Then explain the
results that you see. Submit as part of your zipfile a file named
analysis.pdf that contains your graphs and your explanation.
What doesn’t matter: The absolute numbers on your y-axis don’t
matter. If your implementation happens to take more like 5 seconds or
10 seconds or 30 seconds, that’s fine. What we’re interested in here
is the asymptotic behavior, not the constants. After all your machine
might just be faster or slower than ours. Also, you don’t have to
completely automate your experiments like we did, or use CSVs, or use
gnuplot. But you would be wise to automate as much as you can,
because undoubtedly you will want to run the experiments more than
once.
What does matter: We want to see quadratic performance on lists and linearithmic—i.e., — on trees, for both workloads. If you aren’t getting those running times, then you have a performance bug, and you need to fix it.
What matters even more: Fabrication and falsification of data is unethical. Science rests upon the honesty of experimenters. If you were to make up or modify the data that you present in your graphs, then you would be in violation of the Code of Academic Integrity. (And if you were a professional researcher, you could get fired.) So just don’t do it. Even if you can’t resolve your performance bugs, it’s better to acknowledge that in your analysis than to lie about your experiments.
Starter code: In performanceTest.ml we provide some starter code
to help you, including generation of random and sorted lists, as well
as a function to time the execution time of other functions. We also
provide the two CSV files for our graphs above and the gnuplot
script that produces the graphs from them, in case you want to attempt
the same automation. The make perf target runs those. It also runs
the OCaml native compiler instead of the bytecode compiler. Native
mode produces faster code, which means your experiments will run more
quickly. Using native mode is not required but is likely to be
helpful.
(Optional) Removal from Red-Black Trees
If you would like an additional challenge, try implementing the
remove operation for red-black trees. Again, this is a purely
optional task that will not affect your grade in any way.
The algorithm you should use is that defined in Section 2 of this short paper by Germane and Might. Although the code in that paper is written in Racket and Haskell, two other functional languages, the algorithm is fully described in English and pictures. So the challenge will be understanding and implementing the algorithm: a challenge that you will likely face in the future in other programming tasks! So, this should be good practice.
There are just two places we found any ambiguity in their description of the algorithm:
-
For their Figures 6, 7, and 9: the double black nodes shown in those could in fact be double black leaves.
-
When they say the
reddenoperation changes the root node to be red “if possible,” they mean: if the root is black with two black children, which themselves are black nodes or (black) leaves. And when they say theblackenoperation changes the root node to be black “if necessary,” they mean: if the root is red with at least one red child.
Also, note carefully when the paper mentions the “reflections” of trees at the bottom of p. 426: your code will need to account for those reflections.
After you have implemented remove (which took us around 100 lines of
code, including modifying the representation type to account for
double black nodes and leaves, and therefore modifying some of pattern
matches in the other operations), make sure that you have tested it.
Especially, make sure that you check for the representation invariant
always holding.
If you are keen, update your performance analysis to include remove
in the workload:
- Insert randomly chosen integers into the set.
- Do membership tests, where all those tests succeed.
- [new] Delete all elements in a random order.
You should still see linearithmic performance.
Rubric
- 25 points: submitted and compiles
- 30 points: satisfactory scope
- 30 points: good scope
- 10 points: code quality
- 5 points: excellent scope
Note that there is no testing component to the rubric, although we
still encourage you to follow test-driven development. The graders
will not attempt to run make test on your submission.
Code Quality Rubric.
This will be assessed the same as in A2, including documentation.
Graders will read your extracted public and private HTML documentation,
not the original source code comments. The make docs command must
succeed, or you will lose all points on the documentation. We’re going
to grade the top-level components of a module, not the nested parts.
For example, when we grade listDictionary.ml’s documentation we won’t
click on Make. The same holds for dictionarySet.ml and Make. So
you don’t have to worry about the fact that ocamldoc doesn’t include
the specification comments for Dictionary as part of
ListDictionary.Make’s HTML: we won’t penalize you for those being
missing.
Submission
Make sure your NetIDs are in authors.mli, and set the hours_worked
variable at the end of authors.ml. Note that variable is now must be
a list. Order does not matter in it.
Run make zip to construct the ZIP file you need to submit on CMS.
Our autograder needs to be able to find the files you submit inside
that ZIP without any human assistance, so:
→ DO NOT use your operating system’s graphical file browser to construct the ZIP file. ←
Use only the make zip command we provide. Mal-constructed ZIP files
will receive a penalty of 15 points because of the extra human
processing they will require. If CMS says your ZIP file is too large,
it’s probably because you did not use make zip to construct it; the
file size limit in CMS is plenty large for properly constructed ZIP
files.
The course staff is not going to try and run make test or make
bisect on your submission, but we include your tests for
completeness. As for the Bisect report, make zip automatically
produces it and includes it in your submission. So again, it will be
fine that your tests are omitted.
Ensure that your solution passes make finalcheck. Submit your
zipfile on CMS. Double-check before the deadline that you have
submitted the intended version of your file.
Congratulations! Your search has come to an end.
Acknowledgement: Adapted from Prof. Greg Morrisett, Dean and Vice Provost of Cornell Tech.