Next: Miss Penalty Up: Performance Evaluation Previous: Comparison with GOM
This section evaluates the overhead that HAC adds to hit time. Our design includes choices (such as indirection) that penalize hit time to reduce miss rate and miss penalty; this section shows that the price we pay for these choices is modest.
We compare HAC with C++ running hot T6 and T1 traversals of the medium database. HAC runs with a 30 MB client cache to ensure that there are no misses and no format conversions during these traversals. The C++ program runs the traversals without paging activity on a database created on the heap. The C++ version does not provide the same facilities as our system; for example, it does not support transactions. However, the C++ and HAC codes are very similar because both follow the OO7 specification closely, and both are compiled using GNU's gcc with optimization level 2.
| T1 (sec) | T6 (msec) | |
| Exception code | 0.86 | 0.81 |
| Concurrency control checks | 0.64 | 0.62 |
| Usage statistics | 0.53 | 0.85 |
| Residency checks | 0.54 | 0.37 |
| Swizzling checks | 0.33 | 0.23 |
| Indirection | 0.75 | 0.00 |
| C++ traversal | 4.12 | 6.05 |
| Total (HAC traversal) | 7.77 | 8.93 |
Table 3: Breakdown, Hot Traversals, Medium Database
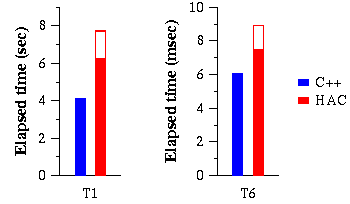
Table 3 shows where the time is spent in HAC. This breakdown was obtained by removing the code corresponding to each line and comparing the elapsed times obtained with and without that code. Therefore, each line accounts not only for the overhead of executing extra instructions but also for the performance degradation caused by code blowup. To reduce the noise caused by conflict misses, we used cord and ftoc, two OSF/1 utilities that reorder procedures in an executable to reduce conflict misses. We used cord on all HAC executables and on the C++ executable; as a result the total traversal times for HAC are better than the ones presented in Section 4.5.
The first two lines in the table are not germane to cache management. The exception code line shows the cost introduced by code to generate or check for various types of exceptions (e.g., array bounds and integer overflow). This overhead is due to our implementation of the type-safe language Theta [LAC+96]. The concurrency control checks line shows what we pay for providing transactions.
The next four lines are related to our cache management scheme: usage statistics accounts for the overhead of maintaining per-object usage statistics, residency checks refers to the cost of checking indirection table entries to see if the object is in the cache; swizzling checks refers to the code that checks if pointers are swizzled when they are loaded from an object; and indirection is the cost of accessing objects through the indirection table. The indirection costs were computed by subtracting the elapsed times for the C++ traversals from the elapsed times obtained with a HAC executable from which the code corresponding to all the other lines in the table had been removed. Since HAC uses 32-bit pointers and the C++ implementation uses 64-bit pointers, we also ran a version of the same HAC code configured to use 64-bit pointers. The resulting elapsed times were within 3% of the ones obtained with the 32-bit version of HAC for both traversals, showing that the different pointer size does not affect our comparison. Note that we have implemented techniques that can substantially reduce the residency and concurrency control check overheads but we do not present the results here.
Figure 8 presents elapsed time results; we subtract the costs that are not germane to cache management (shown in white). The results show that the overheads introduced by HAC on hit time are quite reasonable; HAC adds an overhead relative to C++ of 52% on T1 and 24% on T6. Furthermore, the OO7 traversals exacerbate our overheads, because usage statistics, residency checks and indirection are costs that are incurred once per method call, and methods do very little in these traversals: assuming no stalls due to the memory hierarchy, the average number of cycles per method call in the C++ implementation is only 24 for T1 and 33 for T6. HAC has lower overheads in T6 mainly because the indirection overhead is negligible for this traversal. This happens because all the indirection table entries fit in the processor's second level cache and because our optimizations to avoid indirection overheads are very effective for this traversal.
The overheads introduced by HAC on hit time are even lower on modern processors; we ran the two traversals in a 200 MHz Intel Pentium Pro with a 256 KB L2 cache and the total overheads relative to the C++ traversals (on the same processor) decreased by 11% for T1 and 60% for T6.
It is interesting to note that our compaction scheme can actually speed up some traversals; running T6 with the minimum cache size for which there are no cache misses reduces the elapsed time by 24%. This happens because all objects accessed by the traversal are compacted by HAC into 19 pages, eliminating data TLB misses and improving spatial locality within cache lines. This effect does not occur with T1 because it accesses a much larger amount of data.
Another interesting observation, which puts our indirection table space overhead in perspective, is that the use of 64-bit pointers in the C++ program (and a small amount of space wasted by the memory allocator) result in a database that is 54% larger than ours; this overhead happens to be two times larger than the space overhead introduced by our indirection table during traversal T1.
Next:
Miss Penalty Up:
Performance Evaluation Previous:
Comparison with GOM
Miguel Castro, Atul Adya, Barbara Liskov, and Andrew Myers