Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes
CVPR 2021
Overview Video
CVPR Presentation Video
Abstract
We present a method to perform novel view and time synthesis of dynamic scenes, requiring only a monocular video with known camera poses as input. To do this, we introduce Neural Scene Flow Fields, a new representation that models the dynamic scene as a time-variant continuous function of appearance, geometry, and 3D scene motion. Our representation is optimized through a neural network to fit the observed input views. We show that our representation can be used for complex dynamic scenes, including thin structures, view-dependent effects, and natural degrees of motion. We conduct a number of experiments that demonstrate our approach significantly outperforms recent monocular view synthesis methods, and show qualitative results of space-time view synthesis on a variety of real-world videos.
Results on the Dynamic Scene Dataset
Below you will find videos of our results on the Nvidia Dynamic Scene Dataset [Yoon et al. 2020], along with baselines comparisons.
Click "play all" button in each part for better visualization.

Balloon1
Space-time view synthesis on scene Balloon1

Balloon2
Space-time view synthesis on scene Balloon2

Dynamic Face
Space-time view synthesis on scene Dynamic Face

Jumping
Space-time view synthesis on scene Jumping
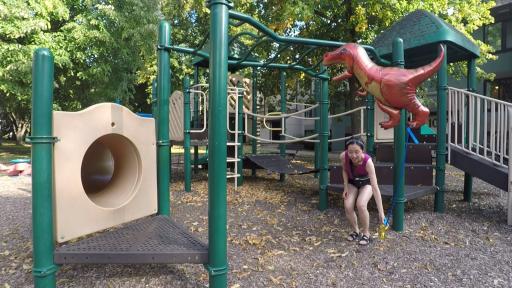
Playground
Space-time view synthesis on scene Playground

Skating
Space-time view synthesis on scene Skating

Truck
Space-time view synthesis on scene Truck

Umbrella
Space-time view synthesis on scene Umbrella

Comparison with 3D Photo
A gallery of results comparing with 3D Photography using Context-aware Layered Depth Inpainting (3D Photo) [Shih et al 2020]
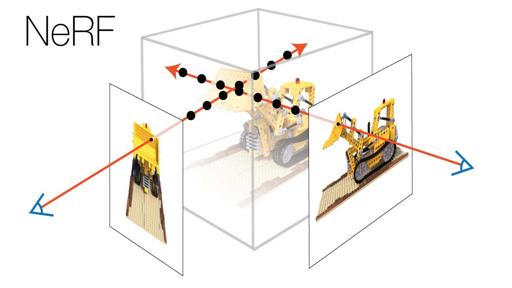
Comparison with NeRF
A gallery of results comparing with Neural Radiance Fields (NeRF) [Mildenhall et al 2020]

Comparison with CVD
A gallery of results comparing with Consistent Video Depth Estimation (CVD) [Luo et al 2020]

Click to view the paper.

Click to view the supp document.

Github Implementation.