Architecture:

3D object detection is an essential task in autonomous driving. Recent techniques excel with highly accurate detection rates, provided the 3D input data is obtained from precise but expensive LiDAR technology. Approaches based on cheaper monocular or stereo imagery data have, until now, resulted in drastically lower accuracies — a gap that is commonly attributed to poor image-based depth estimation. However, in this paper we argue that data representation (rather than its quality) accounts for the majority of the difference. Taking the inner workings of convolutional neural networks into consideration, we propose to convert image-based depth maps to pseudo-LiDAR representations — essentially mimicking LiDAR signal. With this representation we can apply different existing LiDAR-based detection algorithms. On the popular KITTI benchmark, our approach achieves impressive improvements over the existing state-of-the-art in image-based performance — raising the detection accuracy of objects within 30m range from the previous state-of-the-art of 22% to an unprecedented 74%. At the time of submission our algorithm holds the highest entry on the KITTI 3D object detection leaderboard for stereo image based approaches.
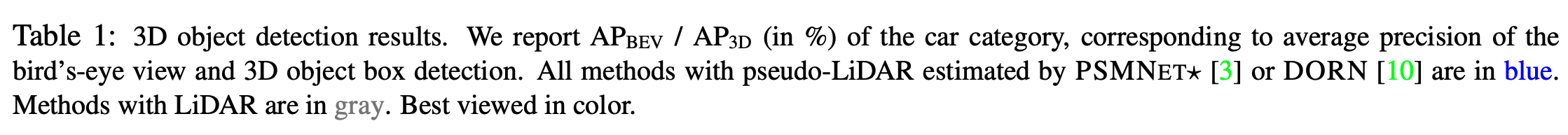

@article{wang2018pseudo,
title={Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving},
author={Wang, Yan and Chao, Wei-Lun and Garg, Divyansh and Hariharan, Bharath and Campbell, Mark and Weinberger, Kilian Q.},
journal={arXiv preprint arXiv:1812.07179},
year={2018}
}