The Cornell Web Lab Project
The purpose of the Cornell Web Lab Project
(weblab.infosci.cornell.edu)
is to provide researchers in various disciplines with tools to analyze
the structure and content of the web as it existed at different points in
time. In collaboration with the Internet Archive
(www.archive.org), we have built a
steadily growing archive containing billions of crawled web pages.
Example analyses on this web archive include:
-
Verifying properties of the hyperlink graph, such as power-law
distributions or small-world phenomena;
-
Monitoring the dynamics of social networks at community sites,
such as portals, file-sharing or review sites and folksonomies;
-
Tracing back the spreading of news, rumors and neologisms or the
adaptation of new products or technology;
-
Comparing how international collaborations have developed at
different universities over time.
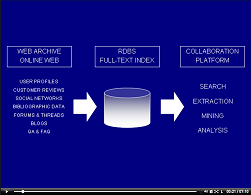 The Cornell Web Lab Project addresses a number of challenges. First,
as the examples above illustrate, web data analysis is done by
researchers from various disciplines. Therefore, one challenge it to
develop interfaces for non-technical users. Moreover, most web analyses
are actually not interested in web pages and hyperlinks, but
relations between objects like user profiles or product descriptions.
These substructures must first be extracted from the web pages. Of course,
web data is often incomplete, inconsistent, outdated or otherwise
incorrect. Users should be able to clean up the data before the analysis.
Finally, the sheer size of the data calls for novel methods not only
for data management, but also search, exploration and summarization.
The Cornell Web Lab Project addresses a number of challenges. First,
as the examples above illustrate, web data analysis is done by
researchers from various disciplines. Therefore, one challenge it to
develop interfaces for non-technical users. Moreover, most web analyses
are actually not interested in web pages and hyperlinks, but
relations between objects like user profiles or product descriptions.
These substructures must first be extracted from the web pages. Of course,
web data is often incomplete, inconsistent, outdated or otherwise
incorrect. Users should be able to clean up the data before the analysis.
Finally, the sheer size of the data calls for novel methods not only
for data management, but also search, exploration and summarization.
We believe that difficult user tasks such as finding suitable subsets
of pages for an analysis, extracting structured data sets and correcting
errors can be much easier when tackled in a collaborative setting. As a
first step, we have developed a prototype of a collaborative web data
extraction tool that allows users to share their search results,
structured data sets and even the extraction rules that they created.
See the
screencast
of an early version of the prototype. Currently, we are investigating
more advanced methos of user collaboration.
This is joint work with
William Y. Arms,
Mirek Riedwald,
Biswanath Panda,
Johannes Gehrke and
Christoph Koch.
Funded in part by National Science Foundation grants
CNS-0403340, DUE-0127308, SES-0537606 and IIS-0634677.
XML Retrieval
XML is widely used not only for data exchange, but also for modeling and
storing persistent semistructured data. An important class of XML applications
deal with content embedded in a rich hierarchical or graph-shaped structure.
Examples include scientific publications, digital encyclopedia, annotated
web data, tagged linguistic corpora and taxonomies and gene expression data.
Querying such data efficiently requires index structures that cover both
the structure and the content. Moreover, while powerful query languages such as
XQuery have found widespread adoption, non-technical users need more
intuitive interfaces such as graphical exploration and search tools.
I worked on these problems during my graduate studies and
Ph.D. at the
Institute for Computer Science and the
Center for Information and Language Processing (CIS),
as a member of the
CIS Research Group on Documents and Semistructured Data.
The work includes the Content-Aware DataGuide index (CADG),
the BIRD numbering scheme for XML trees and a cache system for XML queries
and results. I have implemented these techniques in two prototypical XML retrieval
systems that both make use of a relational backend for storing the XML data.
While the first system processes queries in main-memory, the second one
minimizes the expensive loading of intermediate query results by pushing
the bulk of the query processing to the relational database, including
access to the CADG structure and content index. This helped speed up the
query processing by up to two orders of magnitude. The project also
included work on ranking for vague content and structure queries in the
context of the INEX XML retrieval initiative.
From September to November 2008, I took a leave of absence from Cornell University to
work with
FaST, A Microsoft® Subsidiary
in Trondheim, Norway on fundamentals of XQuery support in their next-generation index engine.
This is joint work with
Klaus Schulz,
Holger Meuss and
François Bry.
Funded in part by the German National Science Foundation (DFG).