Introduction
In this course, using tools from game theory and graph theory, we explore how network structures and network effects play a role in economic and information markets. In essence, our focus is on developing an understanding of how strategic, rational agents interact in a connected world. Let us start by providing an overview using a few examples.
Markets with Network Effects: iPhone vs. Android
Consider a market with two competing mobile phone brands, where the buyers are connected through a social network (see Figure 1). Each phone has some intrinsic value to a buyer, but the actual value of a phone is affected by how many of the buyer’s friends (i.e., the nodes connected to them in the social network) have the same phone—this is referred to as a network effect: For instance, even if a buyer prefers iPhones in isolation (i.e., they have a higher intrinsic value to them), they may prefer to get an Android phone (or even switch to one, if they currently have an iPhone) if enough of their friends have an Android.
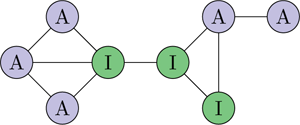
Figure 1: An example of a small social network for the iPhone/Android game. Nodes correspond to buyers. We draw a line (i.e., an “edge”) between nodes that are friends.
Some questions that naturally arise:
- Will there eventually be a stable solution, where everyone is happy with their phone, or will people keep switching phones?
- If we arrive at a stable solution, what will it look like? (For instance, will everyone eventually have the same phone, or can we sustain a market for both?)
- If we want to market iPhones, to which “influential” individuals should we offer discounts in order to most efficiently take over the market?
- How should we set the price of a phone to best market it? (Perhaps start low and increase the price as more people buy it?)
We will study models that allow us to answer these questions. Note that this type of modeling is not only useful to study the spread of products, but it can also be used to reason about the spread of new (e.g., political) or other information (or disinformation) in a social network. For instance, I may be more likely to post a news article on my Facebook wall if many of my friends post it.
The Role of Beliefs
In the example above, to market a phone, it may suffice that enough people believe that their friends will buy the phone. If people believe that their friends will buy the phone, their perceived value of the phone will increase, and they will be more likely to buy it—we get a “self-fulfilling prophecy.”
In some situations, it may even be enough that there exists people who believe that many of their friends believe that many of their friends will buy the phone for this effect to happen—that is, so-called higher-level beliefs (i.e., beliefs about beliefs about beliefs, etc.) can have a large impact. We will study models for discussing and analyzing such higher-level beliefs—perhaps surprisingly, networks will prove useful for modeling higher-level beliefs. We shall next use these models to shed light on the emergence of “bubbles” and “crashes” in economic markets.
More generally, we will discuss how crowds process information and how and why the following phenomena can occur:
- The wisdom of crowds: In some situations, the aggregate behavior of a group can give a significantly better estimate of the “truth” than any one individual member of the group.
- The foolishness of crowds: In other situations, “misinformation” can be circulated through a social network in “information cascades” (e.g., the spread of urban legends/“fake news” through a social network).
Matching Markets, Auctions, and Voting
Let us finally consider a different type of problem. Assume we have three people and three houses . The people may have some constraints on what houses are acceptable to them; we can depict the situation using a graph as shown in Figure 2. Can we find a “matching” (i.e., pairing) between people and houses that respects these acceptability constraints? In this simple example, it is easy to see that can be matched with , with , and with ; we will study algorithms for solving this problem, and more generally, understand when a matching where everyone gets matched exists.
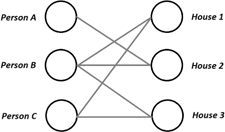
Figure 2: The “acceptability” graph in a matching problem. We draw a line (i.e., an edge) between a person and a house if the person finds the house acceptable.
Consider, next, a variant of this problem where everyone finds all houses acceptable, but everyone prefers to , and to . How should we now assign houses to people? Note that no matter how we assign houses to people, two people will be unhappy with their house (in the sense that they would have preferred a different house).
The key for overcoming this problem is to assign prices to the three houses. This gives rise to the following questions:
- Can we set prices for these three houses so that everyone can be matched with their most preferred house (taking into account the price of the house)? Indeed, we will show that such so-called “market-clearing prices” are guaranteed to exist (and the hope is that the market will converge on these prices over time).
- Can we design a mechanism that incentivizes people to truthfully report how much each house is worth to them, so that we can assign houses to people in a way that maximizes the total “happiness” of all the people? Indeed, we shall study the Vickrey–Clarke–Groves (VCG) auction mechanism that enables doing this.
- In some situations (e.g., school choice, where the “people” correspond to students and the “houses” correspond to schools), we need to restrict to mechanisms without prices/payments. Can we still design mechanisms that incentivize people to truthfully report their preferences in those situations?
We next note that the methods we use to provide answers to the above questions form the basis for the auction mechanisms used in sponsored search, where advertisers bid on “slots” for sponsored results in Internet search queries (and need to pay to get their advertisement displayed)—in this context, the goal is to find a matching between advertisers and slots.
We will also consider the “standard” (non-sponsored) web search problem: think of it as matching webpages with “slots” in the search ranking, but the difference with the sponsored search problem is that now there are no payments. We will discuss the “relevance” algorithms used by search engines (e.g., Google’s PageRank algorithm) to determine how (nonpaying) pages returned by a search should be ordered. Here, the network structure of the Internet will be the central factor for computing a relevance score. The basic idea behind these methods is to implement a voting mechanism whereby other pages “vote” for each page’s relevance by linking to it.
Finally, we will discuss voting schemes (e.g., for presidential elections) more generally, and investigate why such schemes typically are susceptible to “strategic voting,” where voters are incentivized to not truthfully report their actual preferences. (For instance, if your favorite candidate in the US presidential election is a third-party candidate, you may be inclined to vote for your second choice.)
Outline of the Course
The course is divided into four main parts.
- Part I: Games and Graphs. In part I, we first introduce basic concepts from game theory (the study of how rational agents, trying to maximize their utility, interact) and graph theory (the study of graphs, mathematical constructs used to model networks of interconnected nodes). We then use concepts from both to analyze “networked coordination games” on social networks—such games provide a framework for analyzing situations similar to the iPhone/Android example discussed above.
- Part II: Markets on Networks. In part II, we begin by introducing some more advanced algorithms for exploring graphs, and then use these algorithms to explore various different types of markets on networks (including, for example, the above-discussed market for matching houses to people).
- Part III: Mechanisms for Networks. In part III, we discuss mechanisms for taming the above-mentioned auctions, web search, voting, and matching problems.
- Part IV: The Role of Beliefs. Finally, in part IV, we discuss various ways of modeling people’s beliefs and knowledge, and explore how people’s beliefs (and the above-mentioned higher-level beliefs) play a role in auctions and markets.
Comparison with Easley–Kleinberg The many of the topics covered here, as well as the premise of using a combination of game theory and graph theory to study markets, is heavily inspired by Easley and Kleinberg’s (EK) beautiful book Networks, Crowds, and Markets [EK10]. However, whereas our selection of topics follows EK, our treatment is somewhat different. In particular, our goal is to provide a formal treatment, with full proofs, of the simplest models exhibiting the above-described phenomena, while only assuming that people are “rational agents,” acting in a way that maximizes some internal “utility” function. As such, we are also covering fewer topics than EK: in particular, we are simply assuming that the network structure (e.g., the social network in the first example) is exogenously given—we do not consider how this network is formed and do not discuss properties of it. There are a number of beautiful models and results regarding the structure of social networks (e.g., the Barabási–Albert preferential attachment model [BA99], Watts–Strogatz small worlds model [WS98], and Kleinberg’s decentralized search model [Kle00]), which are discussed in depth in EK. We also do not discuss specific diffusion models (e.g., SIR/SIS epidemic models) for modeling the spread of diseases in a social network; instead, we focus only on studying diffusion in a game-theoretic setting where agents rationally decide whether to, for instance, adopt some technology (as in the first example above).
Finally, we only rarely discuss behavioral or sociological experiments or observations (whereas EK discusses many such intriguing experiments and observations)—in a sense, we mostly focus on the mathematical and computational models. As such, we believe that a reader of this book would benefit from reading EK for the behavioral/sociological context.
Prerequisites We will assume basic familiarity with probability theory; a primer on probability theory, which covers all the concepts and results needed to understand the material in the course, is provided in Appendix A. Basic notions in computing, such as running time of algorithms, will also be useful (although the material should be understandable without it). Finally, we assume a basic level of mathematical maturity (e.g., comfort with definitions and proofs).
Intended audience Most of the material in this book is appropriate for a master’s level, or advanced undergraduate-level, course in networks and markets. We have also included some more advanced material (marked as such) that could be included in an introductory PhD-level course.
Acknowledgments I am extremely grateful to Andrew Morgan, who was the teaching assistant for CS 5854 taught at Cornell Tech in 2016 and 2017; Andrew edited and typeset the first version of these chapters, created all the figures in the book, came up with many of the examples in the figures, and found many mistakes and typos. Andrew also came up with many amazing homework problems. Thank you so very much!
I am also very grateful to Naomi Ephraim, Cody Freitag, Antonio Marcedone, Thodoris Lykouris, Drishti Walli, and Yubin Xie, who provided extensive and incredibly valuable feedback on the text, and to Gilad Asharov, Ilan Komargodksi, Abhi Shelat for useful comments. I am equally grateful to Jon Kleinberg, Joe Halpern, and Éva Tardos for many helpful discussions, and most importantly to Joe for lots of great comments on an early draft of the book and many delightful discussions over the years that deeply influenced my treatment of the material in part IV.
Finally, thanks to my beautiful wife Sasha for her constant help and support.