|
Yiwei Bai
Ph.D. Student
CS Department@Cornell University
Office: 344, Gates Hall, Cornell, Ithaca, NY 14853
Email: yb263 [at] cornell (dot) edu
GitHub /
LinkedIn
|

|
|
Biography
Hi! I am a CS Ph.D. student at Cornell University, where I am supervised by professor Carla P. Gomes. My research interests lie in the intersection of reinforcement learning, decision making and computational sustainability. I resecived a B.Eng from ACM Honors Class, Zhiyuan College, Shanghai Jiao Tong University.
|
Education
Cornell University, USA
Ph.D. in Computer Science, Aug. 2018 to Present
|
 |
Shanghai Jiao Tong University, China
Bachelor of Engineering, Sep. 2014 to Jun. 2018
|
 |
Cornell University, USA
Research Intern, June. 2017 to Dec. 2017
|
|
|
|
Preprints
|
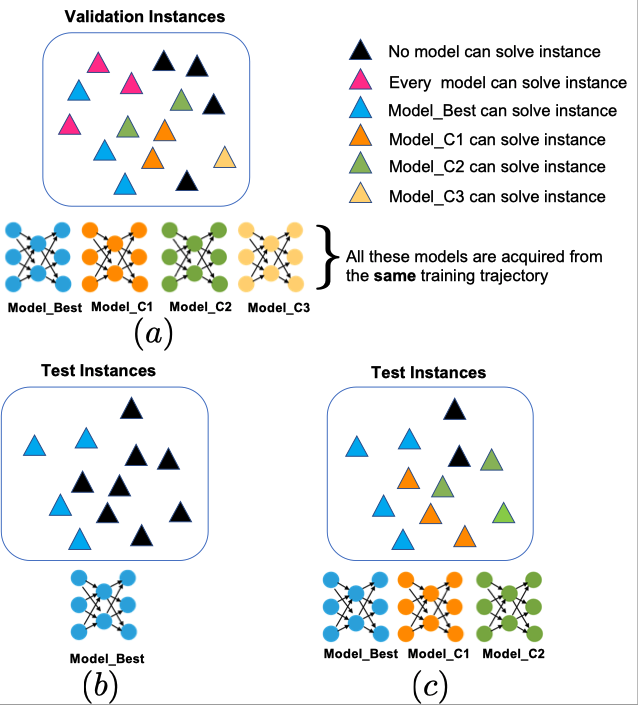 |
Zero Training Overhead Portfolios for Learning to Solve Combinatorial Problems
Yiwei Bai, Wenting Zhao, Carla P. Gomes
Under review.
We have observed that
well-trained models for combinatorial problems acquired in the same training trajectory, with similar top validation performance, perform well on very different validation
instances
ZTop leverages these diverse models to increase the test performance with (almost) zero training overhead.
|
|
Publication
|
|
Automating Crystal-Structure Phase Mapping by Combining Deep Learning with Constraint Reasoning
Di Chen, Yiwei Bai, Sebastian Ament, Wenting Zhao, Dan Guevarra, Lan Zhou, Bart Selman, R.Bruce van Dover, John M. Gregoire, Carla P. Gomes
Nature Machine Intelligence 2021, Cover story.
|
 |
Yi, an AI platform playing the GO(game)
Yiwei Bai, Lequn Chen, and colleagues in Tianrang, (advised by Professor Guirong Xue), Jan. 2017
Yi won the Four-th prize in the first International Computer Go Competition
Yi won the Ninth place in the 10th UEC Cup
I and colleagues trained and tuned the policy network and value network
I and colleagues designed and implemented the reinforcement learning framework of the value network incorporated with policy network
|
|