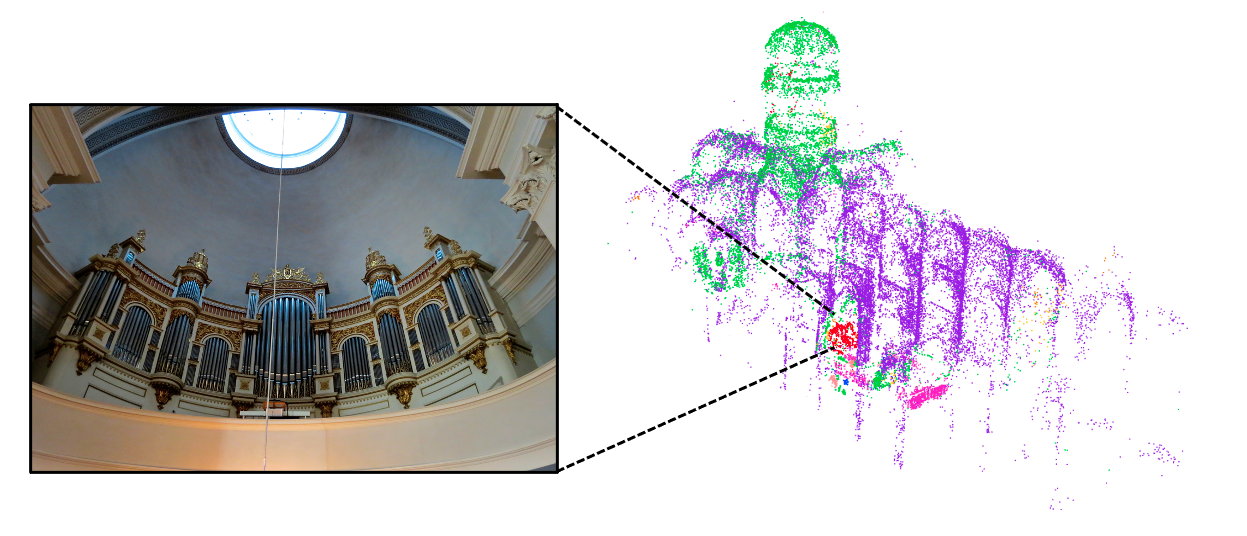
Below we show 3D segmentation results for a landmark not seen during training.
Color legend:
nave,
chapel,
organ,
altar,
choir.
Our technique allows for segmenting very small regions in space, such as the organ:
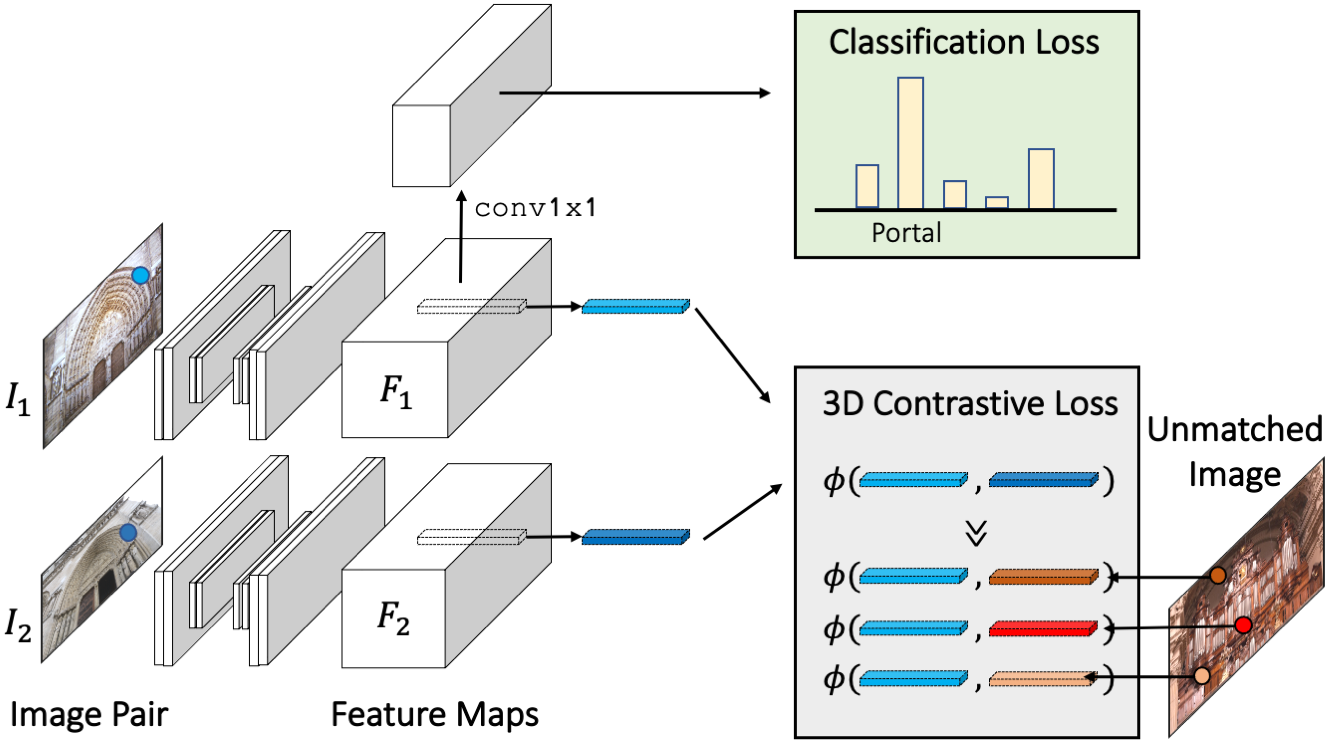
Boosting Image Classification with a 3D-consistency Loss
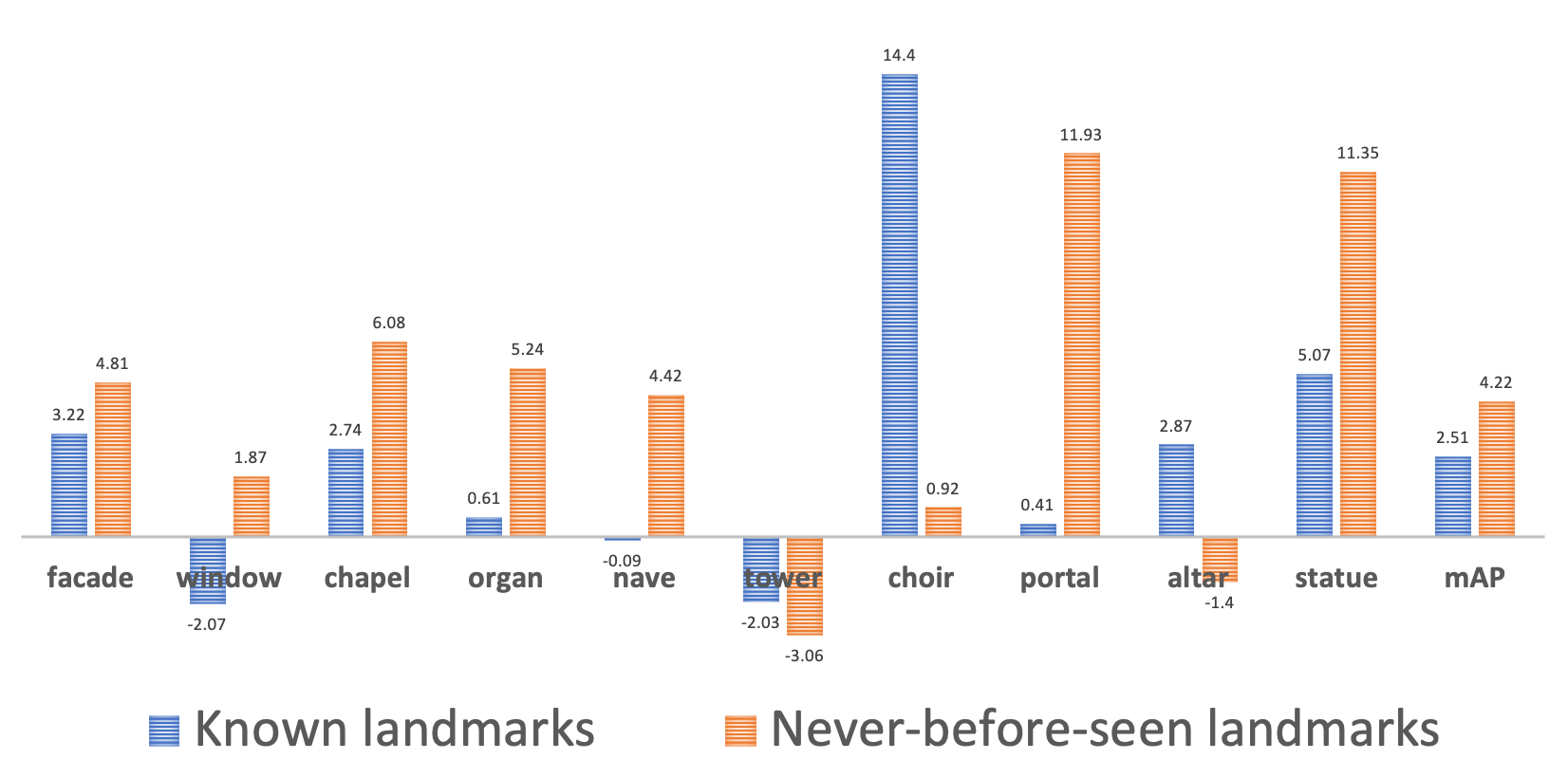
We also performed a quantitative evaluation to quantify to what extent we can classify unseen images, both over landmarks which we use for training, and also over unseen landmarks, and also to see whether or not 3D-consistency helps classification performance (it does!).
Please refer to our paper for additional qualitative and quantitative results.
BibTeX
@inproceedings{Wu2021Towers,
title={Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision},
author={Wu, Xiaoshi and Averbuch-Elor, Hadar and Sun, Jin and Snavely, Noah},
booktitle={ICCV},
year={2021}
}