Date: Thursday, October 16, 2025
Time: 11:45 a.m. to 12:45 p.m.
Location: G01 Gates Hall
Speaker: Peter McMahon, Associate Professor, Cornell Engineering
Title: Physical Foundation Models
Abstract: The rise of foundation models (such as GPT-5, Gemini 2.5, and Llama 4) provides an exciting opportunity for accelerator hardware: in contrast to when different models were used for different tasks, it now makes sense to build special-purpose, fixed hardware implementations of neural networks, where the neural-network parameters (weights) are hard-wired. These hardware accelerators could be manufactured and released at roughly the 1-or-2-year cadence at which new versions of foundation models like GPT have been released.
I will describe how exotic hardware implementations where the neural network is realized directly at the level of the physical design of the hardware, which we call Physical Foundation Models (PFMs) [1], could enable orders of magnitude advantages in energy efficiency and parameter density, and potentially lead to inference hardware capable of running models with >10^18 parameters, which is roughly a million times larger than current models. 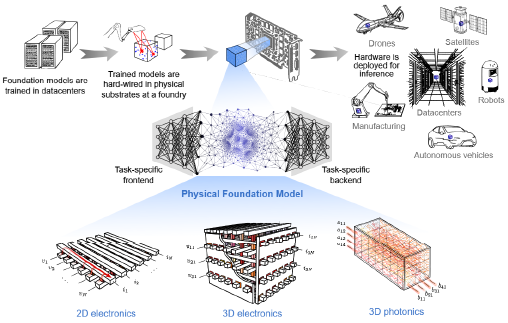
Before ultra-large-scale PFMs can be realized, the concept can be applied to small-scale foundation models for edge applications, such as foundation models for processing wearable sensor data. I will present our recent experimental results in this direction, based on analog processing with fixed resistive crossbar arrays [2]. I will also highlight some of our investigations of how even more unconventional hardware can be used to perform neural-network inference [3,4].
The notion of making fixed neural-network hardware raises a host of computer-science questions. I will end by posing some: How can you design foundation models that are resilient to fabrication errors? What is an appropriate split between fixed parameters and tunable parameters to compensate for errors and perform task-specific processing? Can one make a compiler to map a model like GPT-OSS to physical hardware that doesn't directly support abstract matrix-vector multiplications? What training methods can scale to 10^15 or 10^18 parameters without requiring impractically large conventional computing resources? What aspects of conventional neural-network architecture (such as attention in Transformers) should be incorporated in novel hardware, and how? How can we evaluate and optimize the expressivity of different physical platforms?
[1] L.G. Wright, T. Wang, T. Onodera, P.L. McMahon. In preparation. (2025)
[2] G.M. Marega et al. In preparation. (2025)
[3] L.G. Wright*, T. Onodera* et al. Nature 601, 549-555 (2022)
[4] T. Onodera*, M.M. Stein* et al. arXiv:2402.17750 (2024)
Bio: Peter McMahon is an associate professor in Applied and Engineering Physics at Cornell University, where he has been since 2019. Prior to joining Cornell he completed his Ph.D. in Electrical Engineering and postdoctoral training in Applied Physics at Stanford University. He is the recipient of Packard and Sloan Fellowships, an Office of Naval Research Young Investigator Program Award and a Google Quantum Research Award, and the Lomb Medal from Optica.
