Brilooped
Abstract
In this project we introduce Briloop, an extension into the Bril programming language that supports structured control flow, this allows Bril programs to use if-then-else, while, and block statements instead of relying on jumps and branches. We also implemented Ramsey’s Beyond Relooper to translate Bril programs into Briloop automatically, having a an average performance penalty of 9% when using the core Bril benchmarks. Brilooped not only enables programmers to write Bril programs with structured control flow, but also enables a translation from Bril into WebAssembly.
Representing Briloop Programs
Brilooped programs extends the Bril instruction set with the following op codes: while, block, if, break, and continue.
Brilooped extends the Bril instruction set with new control flow operations that provide structured alternatives to jumps and labels. These new op codes allow programmers to write more readable and maintainable code with familiar control flow constructs like loops and conditionals. This structured control flow can also be useful for specific applications such as WASM.
From lists to trees
Briloop follows Bril’s design philosophy and represent a program as a JSON Object with single key functions that maps to a list of BriloopFunction.
// BriloopProgram
{ "functions": [<BriloopFunction>] }
A Briloop function contains a name, an optional array of function arguments, an optional return type, and a list of instructions. There are no labels in Briloop.
// BriloopFunction
{
"name": "<string>",
"args": [{"name": "<string>, "type":<Type>}, ...]?,
"type": <Type>?,
"instrs": [<BriloopInstruction>, ...],
}
In Bril, the instructions array is a flat list of instructions, but in Briloop structured control flow statements may reference other Briloop instructions. So control flow statements in briloop may contain a children field a list of list of Briloop instructions. Since BriloopInstructions may contain other BriloopInstructions, they give the appearance of being nested:
// BriloopInstruction
{
"op": "<string>",
"dest": "<string>"?,
"type": "<Type>"?,
"args": ["<string>", ...]?,
"funcs": ["<string>", ...]?,
"value": <Value>?,
"children": [[ <BriloopInstruction>, ...], ...]?,
}
Let’s see some of the control flow statements to see how they use the children field
while
The while operation starts a loop that is executed until its argument evaluates to false, or execution is interrupted by a break or continue statement:
{
"op": "while",
"args": ["cond"],
"children": [
[
{ "op": "print", "args": ["b"], },
{ "op": "add", "args": ["a","b"], "dest": "b", "type": "int" },
{ "op": "le", "args": ["b", "ten"], "dest": "cond", "type": "bool" }
]
],
}
op: must be “while”args: a list with exactly one element, the name of a boolean variable that serves as the loop condition. It is evaluated before each execution of the loop.children: a list with exactly one element, the list of instructions (body) to execute in each iteration of the loop. A while statement will iterate indefinitely until the variable name evaluates to false or abreak/retinstruction is executed in the body.- may also be represented in text form:
# will print 0, 1, ..., 9
ten: int = const 10;
a: int = const 1;
b: int = const 0;
cond: bool = id true;
while cond {
print b;
b: int = add a b;
cond: bool = le b ten;
}
block
The block operation starts a block statement that executes the instructions in its body exactly one time, unless interrupted by a block, continue, or ret instruction.
{
"op": "block",
"children": [
[
{ "op": "print", "args": ["a"] }
{ "op": "print", "args": ["b"] }
]
],
}
op: must be “block”children: a list with exactly one element, the list of instructions (body).- may also be represented in text form:
# will print 1, 0
a: int = const 1;
b: int = const 0;
block {
print a;
print b;
}
if
The if operation represents a conditional execution of at least one, but possibly two branches:
{
"op": "if",
"args": ["cond"],
"children": [
[{ "args": ["a", "b"], "dest": "temp", "op": "add", "type": "int" }],
[{ "args": ["a", "b"], "dest": "temp", "op": "sub", "type": "int" }]
],
}
op: must be “if”args: a list with exactly one element, the name of a boolean variable that serves as the if condition.children: a list with at least one element and maximum two elements. The first element represents the true branch and the second (if any) the false branch.- may also be represented in text form:
cond: bool = id true;
if cond
then {
temp: int = add a b;
}
else {
temp: int = sub a b;
}
Transferring control: break and continue
break
The break n operation terminates execution the current control flow statement and exits n additional enclosing control flow statements, transferring control to the instruction immediately after the n-th control flow statement.
{ "op": "break", "value": 0 }
op: must be “break”value: an integer literal representing how many levels of control flow to break out of. Zero-indexed.
Let’s consider a few break examples to see how it behaves in action. In this first example break makes the block statement exit early and execution moves to the first instruction after its closing curly brace:
# will print 1, 3.
block {
print one;
break 0;
print two;
}
print three;
More deeply nested blocks, will require different levels to break out of:
# will print 1, 2, 3, 6, 7
block {
print one;
block {
print two;
block {
print three;
break 1;
print four;
}
print five;
}
print six;
}
print seven;
Only block and while statements count for the number of levels to break out of:
# will print 1, 2, 3, 7
while cond {
print one;
block {
print two;
while cond {
print three;
break 2;
print four;
}
print five;
}
print six;
}
print seven;
continue
The continue n operation skips the remaining code in the current control flow instruction and transfers execution to the n-th control flow instruction. If the n-th control flow operation is a while loop, the next iteration of the loop starts, if it is a block statement it exits the block entirely.
{ "op": "continue", "value": 0 }
op: must be “continue”value: an integer literal representing how many levels of control flow to continue out of. Zero-indexed.
Let’s consider a few break examples to see how it behaves in action. Inside of a block, continue works just like break.
# will print 1, 3.
block {
print one;
continue 0;
print two;
}
print three;
In while statements, continue transfers control to the start of the loop
# will print 0, 1, ..., 9
cond: bool = const true;
a: int = const 0;
one: int = const 1;
ten: int = const 10;
while cond {
print a;
a: int = add a one;
keep_going: bool = le a ten;
if keep_going
then {
continue 0;
}
else {
break 0;
}
}
In nested while loops, continue may transfer control to outer loops:
# will print 1, 2, 1, 2, ...
cond: bool = const true;
while cond {
print one;
while cond {
print two;
continue 1;
}
}
Interpreter Changes
We expanded Bril’s interpreter to handle the five new op codes described above, its implementation was relatively straightforward for break and continue statements and more invovled for the rest of the operations. In particular, correctly implementing multi-level breaks and continues required careful tracking of a level counter to track how many loop boundaries a statement needs to cross.
During development improper handling of multi-level breaks and exits caused programs to become trapped in infinite loops and were tricky to debug - we ultimately resorted to execution profiling to trace the interpreter’s control flow and identify where it was getting stuck. The resulting implementation not only handles complex control flow patterns correctly but does so with minimal additional overhead on the interpreter.
Beyond Relooper
The Beyond Relooper algorithm was described by Ramsey as a way to translate Cmm sources into WebAssembly; for this project we adapted the algorithm to translate Bril into Briloop. We’ll start by providing a high level overview of the algorithm and some of the adaptations we did, as the source and target languages are different from what are presented in Ramsey’s paper.
The Beyond Relooper algorithm takes as input the Dominator Tree of a Control Flow Graph, with the important characteristic that the children in the tree are sorted in descending reverse post order, and produces the Briloop Program as an output. It is implemented as a recursive function over the structure of the dominator tree, where the current node is translated into either a while statement, a list of Briloop instructions, or a block statement:
- A basic block is translated into a while statement if it is a loop header. We use Ramsey’s definition of a block header being a loop header if it has a predecessor with a larger reverse post order than itself rather than the more standard definition of a loop header being a node that has a predecessor that it dominates.
- If a basic block is a merge node it is translated into a Briloop block statement, to support breaking.
- Otherwise, the basic block is translated into a flat list of Briloop instructions.
Detecting the different kinds of translations allows us to only introduce the minimal number of blocks needed for the translation.
Merge nodes
Identifying merge nodes is a key part of the Briloop algorithm. They are defined as nodes that have at least 2 in edges from nodes with a smaller reverse post order. This means that in the original control flow, there are two basic blocks that jump into it and that thse nodes do not form a loop. Detecting them is important since we need to rely on block statements and break instructions in order to reach them (see Theorem three in Peterson, Kasami, and Tokura).
To see why this is needed, consider the following example (based on Ramsey):
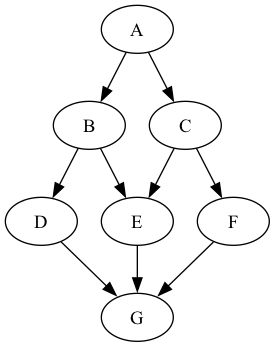
This translation proves difficult to translate without block and break statements as two basic blocks navigate to the same basic block, in this example both B and C are connected to E. If this were expressed in a language with no go to statements, programmers might rely on duplicating the E block in both branches:
// Block A
public void foo(boolean l, boolean r) {
System.out.println("Block A");
if (l) {
if (r) {
System.out.println("Block B");
} else {
System.out.println("Block E");
}
} else {
if (r) {
System.out.println("Block E");
} else {
System.out.println("Block F");
}
}
System.out.println("Block G");
But we want our translation to be minimal, and not rely on duplicate blocks. The beyond relooper algorithm allows this to happen by using break n; statements (Peterson et. al refer to them as multi-level exit instructions):
@foo(l: bool, r: bool) {
print a;
block {
block {
if (l)
then {
if (r)
then {
print b;
break 1;
} else {
break 0;
}
}
else {
if (r)
then {
break 0;
}
else {
print f;
break 1;
}
}
}
print e;
break 0;
}
print g;
ret;
}
This translation may not be what programmers in languages like Java may write, but since the source contains an arbitrary control flow graph and those allow these kind of statements, we need a correct way to translate them.
Loop Nodes
Loop nodes are easier to translate, and only two conditions need to be met:
- Loop headers must be translated into while statements.
- When jumping to a loop header we use a
continue n;instruction, where n is how many control flow statements we need to skip.
The use of while loops introduces a couple of quirks, one to the language and one to the translation from Bril to Briloop programs. The language quirk is that not only are you able to execute continue inside of block statements (in which case it behaves just like a break), but you the level passed to the continue statement must take into account block statements. In the following example we can see the behavior at play, foo will print a, b, c repeatedly whereas bar will print a, b repeatedly.
@foo(cond: bool) {
while cond {
print a;
block {
print b;
continue 0;
}
print c;
}
}
@bar(cond: bool) {
while cond {
print a;
block {
print b;
continue 1;
}
print c;
}
}
The quirk from the translation to Bril to Briloop is that we rely on all while loops to execute forever and rely on break statements to terminate the loop execution. This has the unfortunate consequence of worsening performance for loops (especially nested ones) as we introduce a true variable before every while translation.
Results
Impact of Brilooped Transformation on Dynamic Instruction Count
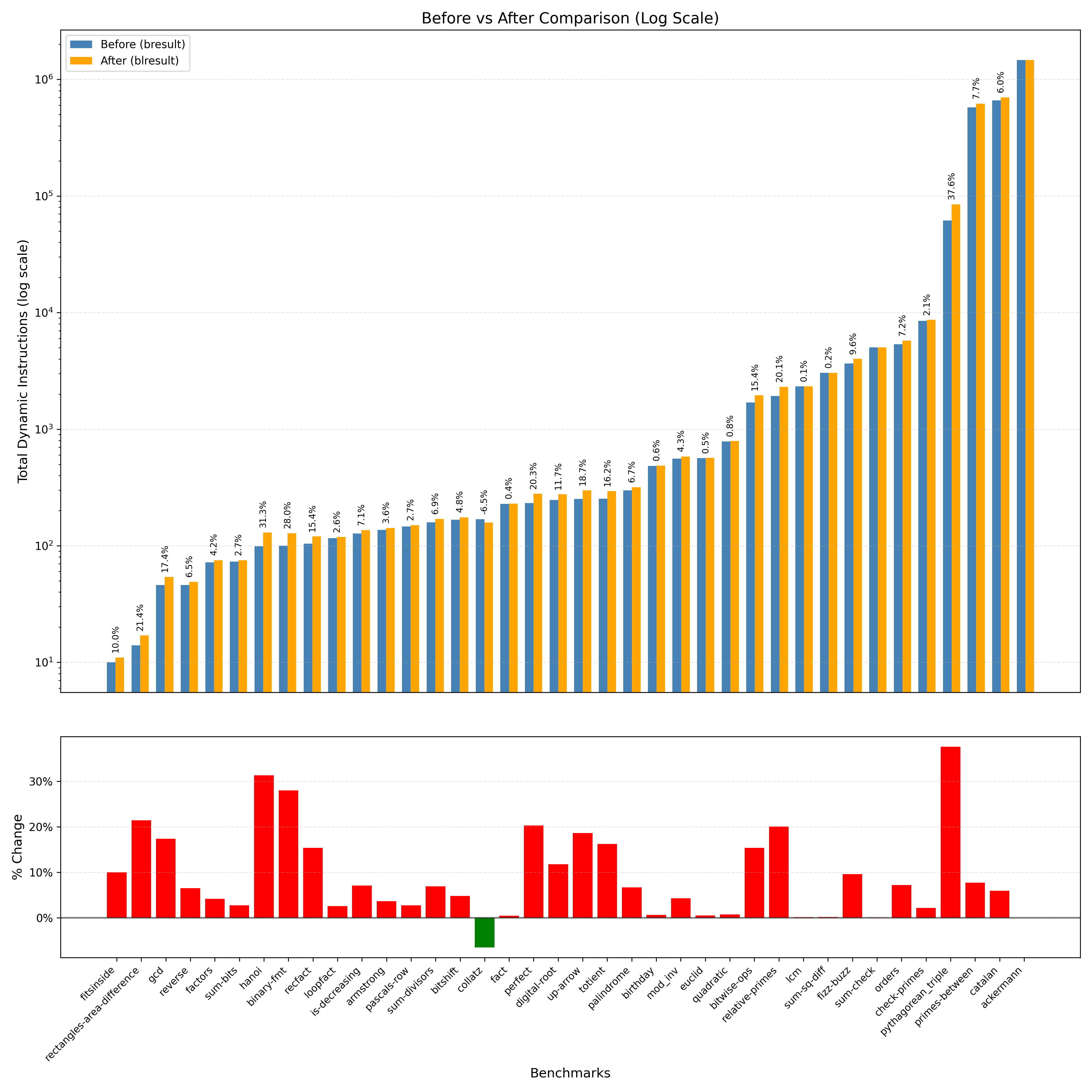
Our analysis of the Bril to Brilooped transformation using the relooper algorithm shows significant variations in dynamic instruction count across different benchmarks. As shown in Figure 1, the majority of benchmarks (37 out of 38) experienced an increase in dynamic instruction count after transformation, with only the collatz benchmark showing a reduction (-6.51%) due to br and jmp instructions making up a majority of the functionality. The changes in dynamic instruction count ranged from minimal increases (below 1%) for benchmarks like sum-check and lcm to substantial increases exceeding 30% for benchmarks such as binary-fmt (28.00%), hanoi (31.31%), and pythagorean_triple (37.60%).
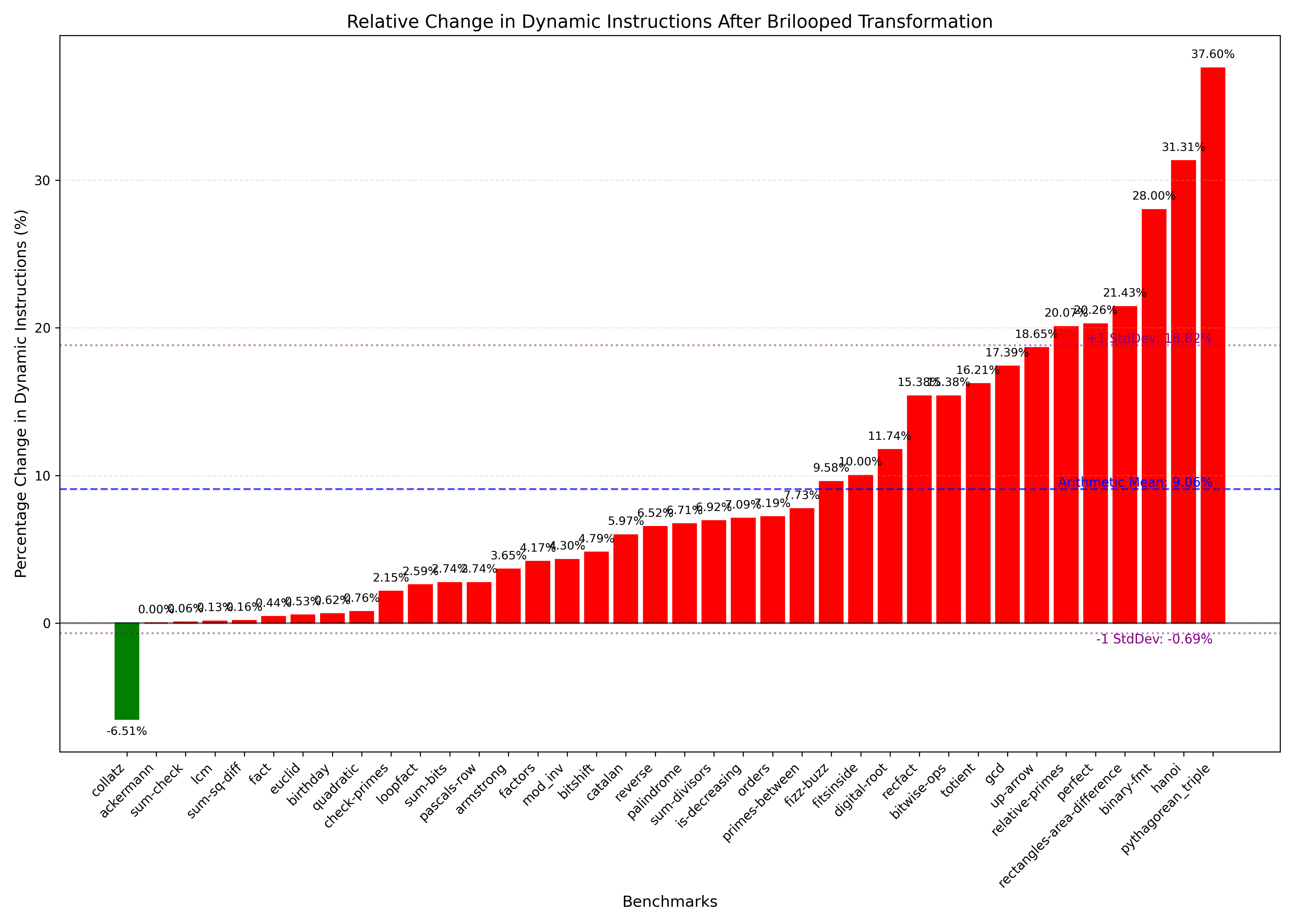
The blue dashed line in Figure 1 is the average (9.06%) change in dynamic instructions after the transformation. 11 of the benchmarks were significantly above (>15%) this average while 9 were significantly below (<1%), leading to a large standard deviation (9.75%).
Execution Time Analysis Across Benchmarks
Figure 2 presents the speedup ratios (Before/After) across all benchmarks. The majority of speedup ratios fall below 1.0 (collatz is the only outlier), indicating an increase in execution time after transformation to Brilooped. The average performance across all benchmarks shows:
- Arithmetic Mean: 0.9235 (7.65% slowdown)
- Geometric Mean: 0.9203 (7.97% slowdown)
- Harmonic Mean: 0.9169 (8.31% slowdown)
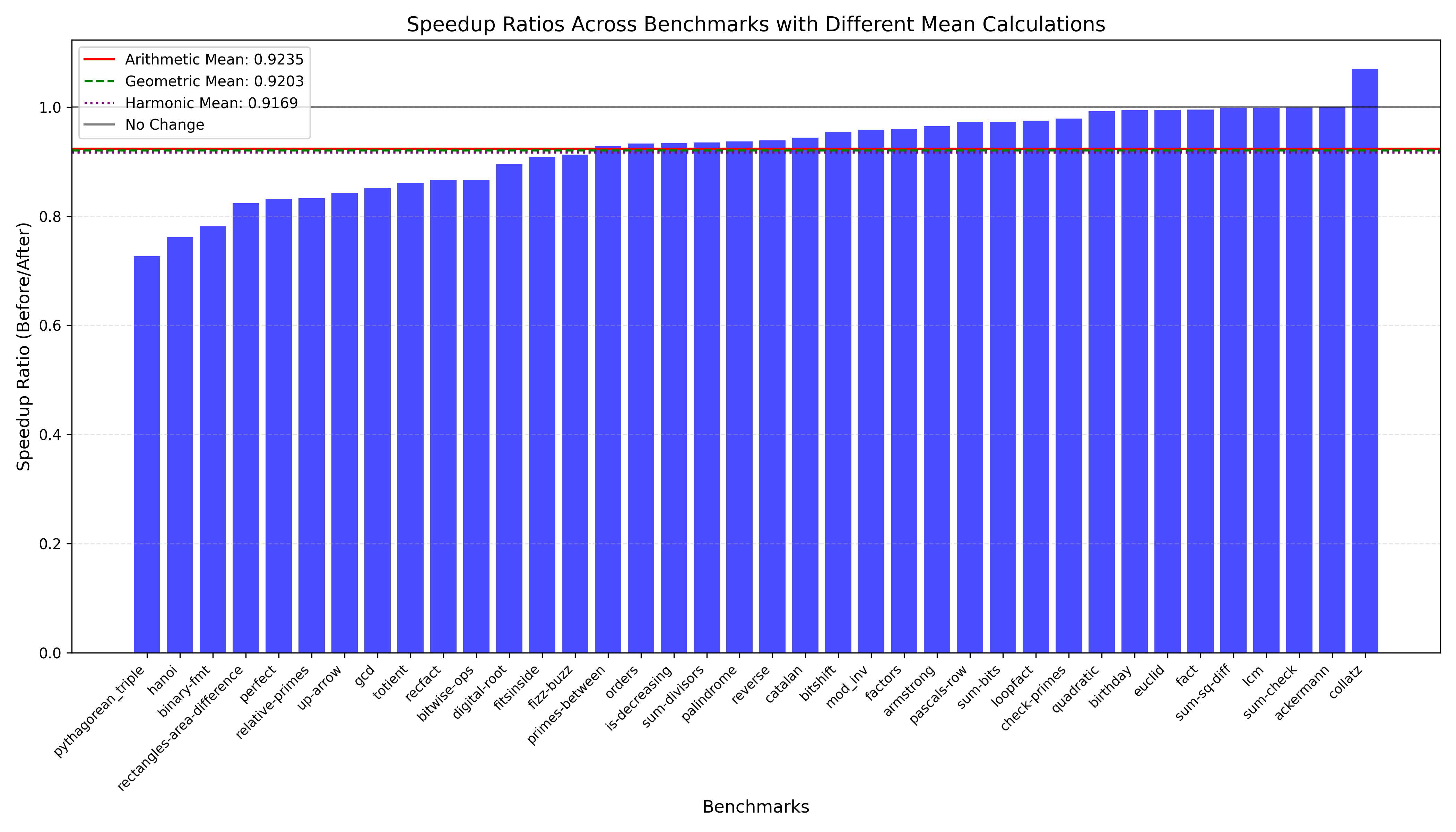
The speedup ratios vary considerably across benchmarks, with pythagorean_triple showing the most significant slowdown (speedup ratio of approximately 0.73 or 27% slowdown), while benchmarks like collatz exhibited speedup ratios near or slightly above 1.0, indicating slight improvement to performance. Benchmarks like pythagorean_triple struggle in this category due to nested loops.
Relationship Between Benchmark Size and Transformation Impact
Figure 3 illustrates the relationship between benchmark size (measured in dynamic instructions before the transformation) and the percentage change in dynamic instructions. This shows some interesting patterns:
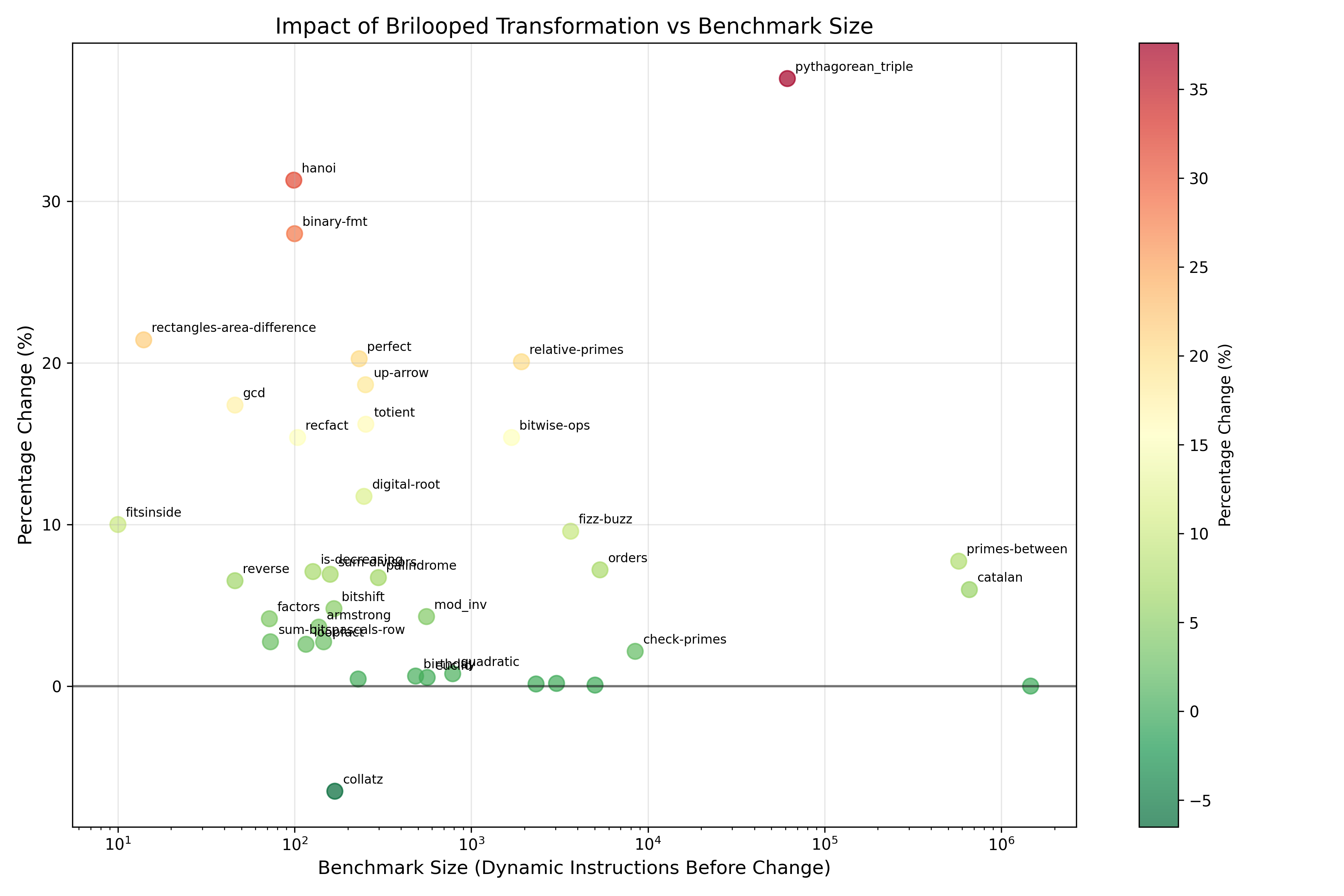
-
The most substantial percentage increases occurred in benchmarks of varying sizes, with
pythagorean_triple(largest at ~10,000 instructions) showing a ~37% increase,hanoi(~100 instructions) showing a ~31% increase, andbinary-fmt(~100 instructions) showing a ~28% increase.- Briloop syntax seems to be causing lots of overhead in the smaller examples
- Nested loops are very expensive
- Recursion can be very expensive
-
There doesn’t seem to be any strong correlation between benchmark size and the magnitude of impact from the Brilooped transformation. Both small and large benchmarks showed varying degrees of change. Benchmarks clustered around the 10^2 instruction count range had the greatest variance, ranging from approximately -6% to +31%.
Before vs. After Comparison with Percentage Changes
Figure 4 provides a comparison of the total dynamic instructions before and after the Brilooped transformation on a logarithmic scale, along with the percentage changes for each benchmark. The top graph demonstrates that while the absolute instruction count increases for almost all benchmarks, the relative differences vary significantly.
Summary of Findings
-
The Brilooped transformation using the relooper algorithm resulted in increased dynamic instruction counts for 37 out of 38 benchmarks, with increases ranging from negligible to substantial (up to 37.60%).
-
The overall performance impact was a modest slowdown, with average execution time increases between 7.65% and 8.31% depending on the mean calculation method.
-
The benchmarks most affected by the transformation were
pythagorean_triple,hanoi, andbinary-fmt, whilecollatzwas the only benchmark that saw reduced instruction count after transformation. -
Most importantly, all benchmarks in the test suite produced correct results after transformation to Brilooped, confirming the semantic correctness of our implementation of the relooper algorithm.
These results suggest that while transforming Bril code to Brilooped using the relooper algorithm introduces some overhead in most cases, the structured control flow benefits of Brilooped come with a reasonable performance cost. The high variance in impact across different benchmarks indicates that the transformation’s efficiency depends significantly on the specific control flow patterns in the original code. This tradeoff seems acceptable, especially considering that all benchmarks maintained their functional correctness.