Are trace-based compilers the endangered species of JITs?
Introduction
This blog post is inspired by Trace-based just-in-time type specialization for dynamic languages.
Dynamic languages are hard to statically compile because of the many possibilities of type combinations.
function add(a, b) {
return a + b;
}
In this JavaScript function, a and b could be of any type, and thus there is no single operation backing the use of +, which could be referring to string concatenation, numeric addition, or a user-defined operation.
let a = [“hello”, “ “];
let b = “world”;
add(a, b); // “hello, world”
Here the + operator turns the string array into a string and then does string concat.
JIT compilation is one strategy to use runtime information to inform the partial compilation of a program. This approach avoids high initial cost of static compilation and potential “waste” of compiling code paths that see little action.
Tracing JIT’s operate by inspecting hot paths through the control flow of a program as it is executed by the interpreter/VM and then compiling/optimizing these paths into faster, typically native, code. The assumption is that a loop, in steady-state, will be type-stable; that is, the types of variables will not change across iterations.
Paper Summary
Trace Trees
TraceMonkey only traces loops, and begins a (branch) trace when it notices a hot exit in a loop. Type maps, which store information about the type of each variable, are stored with the loop trace. When the VM attempts to call the compiled loop trace, the type map must match to run the compiled code.
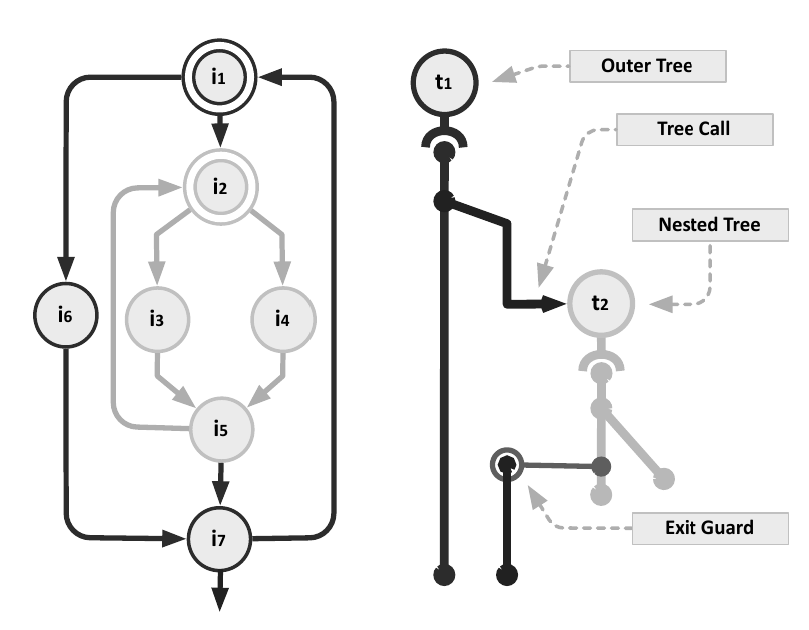
Nested trace trees are used to handle nested loops, in which the inner loop becomes hot before the outer loop. This can lead to unnecessary tail duplication for every side-exit and type combination. Nested trace trees allow separate compilation of the inner and outer loops; the outer loop’s traces then call the inner loop’s trace tree.
Type Specialization
All primitives in the lowered IR apply to operands of specific types, so they can be compiled to efficient machine code with the same techniques used for typed languages. In order to produce these typed traces, TraceMonkey performs type specialization. This omits all operations performed in order to dynamically dispatch on the type, underlying representation, and inheritance structure of the value or object being referenced; only the instructions necessary for accessing a value of that runtime type and structure are recorded in the trace.
One interesting aspect of the implementation is that while most of the work in type specialization involves omitting operations the interpreter performs to determine the type or representation of a value, TraceMonkey also builds in some type specialization on the level of the interpreter itself. In JavaScript, there is no distinction between integers and doubles; there is only a Number type. However, many operations such as array indexing are defined only on integers. In TraceMonkey’s interpreter, Numbers are always assumed to be integers when possible.
In order for type specialization to be sound, guards are inserted so that programs may exit a trace if operations yield values of a different type from those seen in recording.
Optimizations
Since traces are on the level of instructions, function inlining occurs mostly “for free”. However, some additional operations need to be added at call sites, such as checking that the function being called has not changed, or recording that a new call frame was entered.
TraceMonkey performs optimizations such as constant subexpression elimination, expression simplification, and dead code elimination on recorded traces as they are being recorded.
Benchmarks
The SunSpider benchmark used in this paper was created as one of the earlier JavaScript benchmarks. It came at a time where JavaScript as a language was still not entirely established in its use cases and runtimes. As a result, it consists of quite short and simple benchmarks.
The shortness of benchmarks in SunSpider places tracing at a disadvantage, since tracing pays an upfront cost of recording and compiling traces and relies on these compiled traces being taken advantage of many times in order to achieve an overall performance increase. Simply using longer iterations of the same benchmark code would amplify the benefits of tracing.
We also considered that the test suite might not be representative of most modern day, client-side JavaScript programs. TraceMonkey was written for use in Firefox, and it may not be the case that most frontend code spends a lot of time in loops. However, it’s not easy to say what exactly would make a benchmark suite representative of typical web browsing.
It seems that as JavaScript compilers improve, users will run JavaScript on increasingly difficult workloads. As these applications extend beyond what language implementers originally imagined, more benchmarks will be required to evaluate a compiler’s success on modern tasks.
Selective Pressures
In the paper, the authors cite multiple program patterns that may lead to poor performance. For instance, TraceMonkey may encounter issues if there exists at least one root trace for a loop, but there also exists a hot side exit after which an exception is thrown, so the VM cannot complete a trace and the loop body is short. This would result in repeatedly searching for a trace, executing it, and falling back to the interpreter. This frequent transition between native code and the interpreter would produce unnecessary overhead.
Another issue cited in the paper involves nested loops with short bodies, requiring many small traces to be stitched together. While running the traces, numerous extraneous trace activation records may be written and read from.
We considered a few other issues which may lead to poor performance of this implementation.
First, we called into question the assumption that loops are type-stable. For instance, there may exist a function which iterates through a list of objects, where each object is of arbitrary type, and prints each one. Due to these operations being inside a loop, these operations would be hot; however, a new trace needs to be recorded for each distinct type of object in the list. This would result in both code blowup and numerous hand-offs between the interpreter and the compiled code.
Another program likely to pose issues is one with a conditional branch early in a single loop, where both branches are hot. Since TraceMonkey only begins traces at loop headers, assuming the loop is type stable, only one trace is recorded for the loop. As a result, it is possible that the VM would enter and fail to execute a trace repeatedly due to failing the conditional branch, despite the types of all values being stable.
Evolution Beyond TraceMonkey
TraceMonkey’s successors and Other JITs
Starting with Firefox 11, TraceMonkey had been replaced by JägerMonkey, a fast-running MethodJIT with type inference. Why do we not see a continuation of tracing JIT’s for JavaScript?
One reason for TraceMonkey’s obsolescence is highlighted in a 2010 Mozilla Hacks article: “The downside of the tracing JIT is that we have to switch back and forth between the interpreter and the machine code whenever we reach certain conditions… And it turns out that happens a lot – more than anyone expected.”
TraceMonkey displayed pretty good results in many SunSpider benchmarks, showing that it had the potential for high performance in specific scenarios. However as discussed above, SunSpider may not have been the most representative benchmark suite for browser JavaScript execution. As the web evolved into and throughout the 2010s, the profile of workloads that SpiderMonkey and other JavaScript runtimes needed to handle also evolved.
The successors of TraceMonkey and JägerMonkey tended to follow a more “traditional” compiler design, using control flow graphs, SSA, and several layers of intermediate representation; however, tracing did not seem to make a return to these JITs.
Other Tracing JITs
LuaJIT
We want to extend this discussion to not only the successors of TraceMonkey, but also to other (tracing) JITs in general, beginning with Lua. An immediate question arises: why has LuaJIT seen more success with tracing than JavaScript?
We reason that JavaScript programs are incredibly diverse: from low-latency web servers to mobile games, this language has seen a broad range of uses. From the benchmarks, we have seen that TraceMonkey’s performance has rather high variance. There are countless edge cases to consider when designing a JIT for JavaScript, so perhaps it is better to optimize for the general case, rather than a few specific scenarios.
Though Lua is certainly not an unpopular language, especially in the domain of video games, there are not as many use-cases as compared to JavaScript.
Pypy (Meta-tracing)
Another active field in which we see tracing is meta-tracing, a prime example of which is Pypy. Meta-tracing is a technique in which tracing is applied to an interpreter itself. The advantage of this approach is that the meta-tracing logic is language-agnostic in relation to the interpreter being meta-traced. This allows for a theoretically reusable toolchain (known as RPython) that can convert any interpreter (written in RPython) into a JIT.
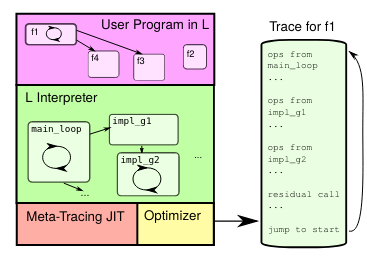
figure from King’s College London
For a large language like Python, the high amount of edge cases means that writing a correct and efficient tracing compiler is especially hard. Meta-tracing is preferable in such cases because of the separation between tracing logic and interpreter logic.
RPython is theoretically reusable to implement other languages, but in practice it doesn’t seem like a popular approach. For example, active development for Pixie, a language implemented by a RPython interpreter, hasn’t existed since 2016, which is almost 8 years ago from the writing of this post.
The RPython docs maintains a list of projects that use it, but the list was reportedly last curated in November 2016.
Conclusion
Tracing JITs have a lot of cool theoretical advantages but in reality they have been overtaken by other approaches to JIT compilation, such as method-based JITs. It was enlightening to learn about the first published JIT implementation of JavaScript, and contextualize it against the state-of-the-art. We explored the properties and use cases of JavaScript and how it may have informed the preference of method-based JITs over tracing.