Memory Optimization and Profiling for MLIR-Based HeteroCL
Introduction
HeteroCL1 is a programming infrastructure composed of a Python-based domain-specific language (DSL) and a compilation flow that targets heterogeneous hardware platforms. It aims to provide a clean abstraction that decouples algorithm specification from hardware customizations, and a portable compilation flow (shown in Fig. 1) that compiles programs to CPU, GPU, FPGA, and beyond.
 Fig. 1: HeteroCL supports compilation for various backends
Fig. 1: HeteroCL supports compilation for various backends
The original HeteroCL uses Halide IR as an intermediate representation. However, Halide IR is difficult to extend and scales poorly to programs with hundreds of modules. Therefore, we are moving to the MLIR ecosystem for better scalability and extensibility. MLIR2 stands for Multi-Level Intermediate Representation, which is a modular compiler infrastructure that enables different optimizations performed at different levels of abstraction.
We build a HeteroCL (HCL) dialect in MLIR to capture hardware customizations and define program abstractions. Hardware customizations are optimization techniques to build faster and more efficient programs or architectures. There are three types of hardware customizations:
- Compute customizations: such as loop unrolling, splitting, reordering, and pipelining.
- Data type customizations: quantization, packing, and unpacking.
- Memory customizations: build custom memory hierarchies and scratchpad memories.
In HeteroCL, we use schedule and stage to specify hardware customizations. A stage is either a function or a loop nest that produces or updates tensors. A schedule is a graph of stages created from the algorithm description, and all hardware customizations are specified on the schedule, thus decoupled from the algorithm specification. For this project, we aim to strengthen HeteroCL’s memory customization ability and add performance profiling infrastructure. Specifically, we make the following contributions:
- We extend the
.reuse_at()primitive to generate reuse buffers for a broader range of applications with higher dimension tensors and complex memory access patterns. - We propose a
.buffer_at()primitive to generate write buffers so that the memory access overheads can be further reduced. - We add a profiling tool to evaluate the operational intensity and automatically generate a roofline model to guide the optimization process.

Fig. 2 is an overview of reuse buffer and write buffer generation with reuse_at and buffer_at primitives. We will go into details in the following sections.
Reuse Buffer
The original HeteroCL paper only discusses how to generate reuse buffers for a simple 2D convolutional kernel, while real-life applications generally have high-dimensional arrays with complex access patterns. In this project, we try to extend the idea of reuse buffer in the MLIR framework to support more applications. In this section, we will first discuss the high-level design of reuse buffer and detail the implementation.
Design
The basic idea of reuse buffer is to reuse data between adjacent loop iterations so that the number of off-chip memory accesses can be reduced. Unless otherwise noted, we suppose the traversal order is the same as the memory access order in this report, i.e., always access the last dimension first and then access the second-to-last, etc.
The applications that have data reuse are mostly stencil kernels, so we follow SODA3 to give a similar definition. Consider a point $\mathbf{x}=(x_0,x_1,\ldots,x_m)\in\mathbb{N}^m$, a $n$-point stencil window defines a set of offsets $\{\mathbf{a}^{(i)}\in\mathbb{N}^m\}_{i=1}^{n}$ that describe the distance from $\mathbf{x}$. By adding the offset to a specific point, we can get the actual points $\{\mathbf{y}=\mathbf{x}+\mathbf{a}^{(i)}\}_{i=1}^n$ of a stencil in a specific iteration. The value of these points will be reduced (e.g., mean, summation) to one value in the output tensor.
We further define the span $s_d$ of a dimension $d$ as the largest distance between two stencil points along that dimension.
$$s_d=\max_{i}(\mathbf{a}^{(i)}_d)-\min_i(\mathbf{a}^{(i)}_d)+1$$
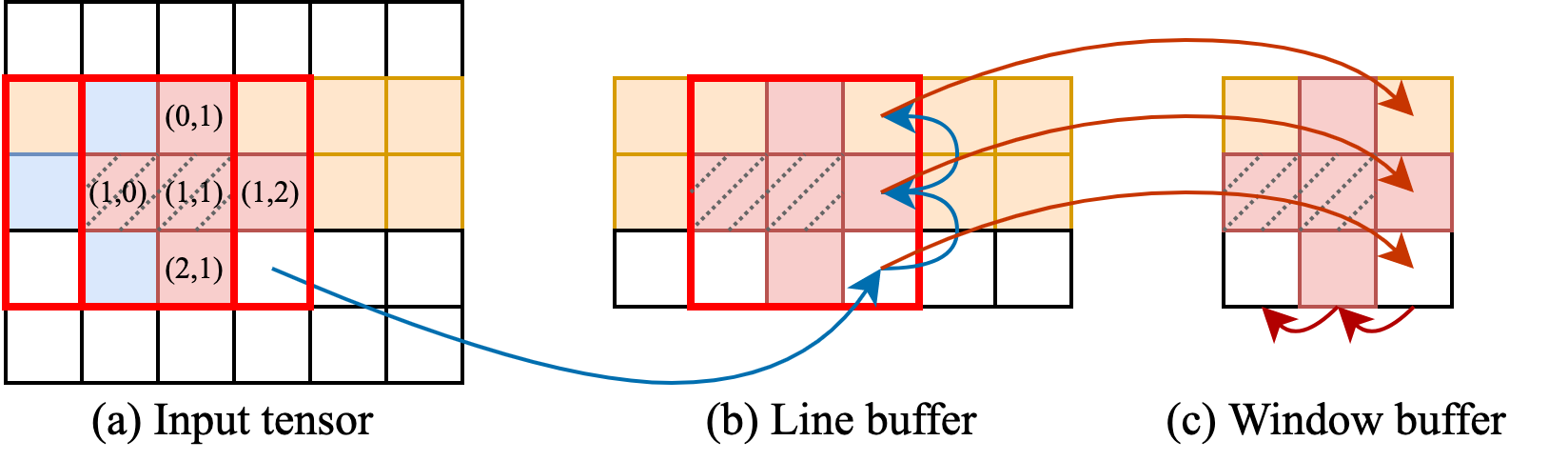
In the Fig. 3(a) example, we consider a five-point stencil
$$\{\mathbf{a}^{(i)}\}^{5}_{i=1}={(0,1),(1,0),(1,1),(1,2),(2,1)}$$
colored with red, and the span of each dimension is $s_0=s_1=2$.
Declaring this kernel in HeteroCL is easy. Users can leverage the declarative API hcl.compute() to explicitly write out the computation rule as follows.
def test_stencil():
hcl.init(dtype)
A = hcl.placeholder((width, height))
def stencil(A):
B = hcl.compute(
(width - 2, height - 2),
lambda i, j: A[i, j + 1]
+ A[i + 1, j]
+ A[i + 1, j + 1]
+ A[i + 1, j + 2]
+ A[i + 2, j + 1],
name="B",
dtype=dtype,
)
return B
s = hcl.create_schedule([A], stencil)
B = stencil.B
From the memory access pattern above, we can see that when the stencil window is moved from the previous iteration (blue grids in Fig. 3(a)) to the next iteration in the same row (red grids in Fig. 3(a)), there exist two replicated data in these two iterations (highlighted with dash line). If all the data are loaded from off-chip memory, it may cause contention and introduce large memory access overheads. To exploit this data reuse opportunity, HeteroCL provides a push-button primitive .reuse_at() for users to declare reuse buffers. By specifying the dimension, users can exactly control the location of reuse buffers.
The minimal size of the reuse buffer consists of small rectangular strips whose total length is equal to the reuse distance of the stencil.3 In the five-point stencil example, this requires generating buffer covering elements from $(0,1)$ to $(2,1)$. The total size of the buffer is $4+6+3=13$. However, this may introduce complicated control logic when implemented on FPGA. Thus, for simplicity, we use the rectangular hull of the stencil as the reuse buffer, which is labeled as red frame in Fig. 3(a). We call it window buffer. The shape of this buffer is $[s_0,s_1,\ldots,s_m]$. We can always reuse data when the buffer moves along the same row.
While this works well for one dimension, when the stencil window moves from the end of previous row to the front of the next row, there will be no elements that can be reused, which may incur extra latency to load data from off-chip memory. A traditional way to tackle this problem is leveraging another load process to prefetch the data, so the reuse buffer can always be prepared with data. This method again complicates the control logic and requires an extra prefetching function to work concurrently. To be consistent with the API that HeteroCL proposed, we can further create hierarchical reuse buffers to hide memory access overheads. As shown in Fig. 3(b), we can create a line buffer to reuse data along the column dimension. Basically, only one element needs to be fetched from off-chip memory to line buffer in each iteration. The original elements in the line buffer need to be shifted up for one grid as depicted in blue arrows. After the elements are loaded to the line buffer, they are further copied to window buffer as shown in red arrows in Fig. 3(c). In this way, the data loading pipeline can work perfectly without stall. Finally the kernel can simply use the indices in $\{\mathbf{a}^{(i)}\}^{5}_{i=1}$ to access the elements in the window buffer.
The programming interface is also easy-to-use. Users only need to attach the following two lines of code to their schedule. Our compiler will automatically generate the buffer and implement the reuse logic.
# schedule.reuse_at(tensor, stage, axis)
LB = s.reuse_at(A, s[B], B.axis[0])
WB = s.reuse_at(LB, s[B], B.axis[1])
For higher-dimensional cases, we can generalize the above idea and generate hyper-cubic buffers. Currently we only support stride-one reuse patterns. Suppose the input tensor has shape $[w_0,w_1,\ldots,w_m]$, the hierarchical buffers may have the following shape (if the corresponding axis has reuse pattern).
$$ \begin{aligned} \text{reuse at axis 0}: &[s_0,w_1,\ldots,w_m]\\ \text{reuse at axis 1}: &[s_0,s_1,\ldots,w_m]\\ \cdots &\\ \text{reuse at axis m}: &[s_0,s_1,\ldots,s_m]\\ \end{aligned} $$
Implementation
The above description seems straightforward, but the actual implementation in MLIR is difficult. There are two main challenges here:
- The affine dialect decouples the expression from actual variables making analysis indirect. For example, the
affine.loadoperation accepts block arguments as operands, theAffineMapAttrthat describes the memory access is attached to the attribute. The actual indices are calculated by applying theAffineMapAttrto the operands. Foraffine.load %1[0, %arg2 + 1], there is only two operands%1and%arg2. The attachedAffineMapAttris(d0)->(0, d0+1). - MLIR uses a strict SSA form, meaning the computation rule is not written in one line and requires us to traverse the use-def chain to obtain the actual memory access operations. We also need to distinguish between off-chip memory access and on-chip memory access.
To tackle the above challenge, we need to prepare required information before actual analysis. Since there are so many ways to declare memory access, users can directly write out each input element, or they can leverage hcl.sum to reduce value in a given dimension as shown below, which calls for a systematic way to analyze the memory access.
def conv2d(A, F):
rc = hcl.reduce_axis(0, ic)
rh = hcl.reduce_axis(0, kh)
rw = hcl.reduce_axis(0, kw)
B = hcl.compute(
(bs, oc, oh, ow),
lambda n, c, h, w: hcl.sum(
A[n, rc, h + rh, w + rw] * F[c, rc, rh, rw],
axis=[rc, rh, rw],
dtype=dtype,
),
name="B",
dtype=dtype,
)
return B
We record the span of each dimension. If the access pattern is written in reduction format, we can easily figure out the span of dimension equal to the size of reduction axis. Otherwise, we need to manually get the offset from the affine expression and calculate the difference between the largest and smallest offset. The affine expressions are stored in a set with the offset as the sorting key.
Based on the span and original tensor shape, we can allocate a reuse buffer with correct size. We ignore the leading 1 in the shape, while original HeteroCL does not eliminate these dimensions. Our approach makes the code more compact and easier to calculate the memory indices.
After the reuse buffer is created, the original memory read should be changed to read from reuse buffer that directly uses stencil offsets as the indices. Since we are now conducting computation regarding the input tensor, the loop bound also needs to be changed to the size of the output tensor. The original memory store should be updated to reflect the new loop bound.
Since the reuse buffer is actually reusing the data in the input tensor, we need to create if statement to check if the points are on the boundary. If so, only data loading will be performed. Otherwise, the computation will also be conducted.
Before the actual computation starts, the first thing to do is to shift buffer elements and load one element from off-chip memory to on-chip buffer as shown in Fig. 3. Following shows the MLIR code for five-point stencil with line buffer.
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func @top(%arg0: memref<10x10xi32>) -> memref<8x8xi32> {
%0 = memref.alloc() {name = "B"} : memref<8x8xi32>
%1 = memref.alloc() : memref<3x10xi32>
affine.for %arg1 = 0 to 10 {
affine.for %arg2 = 0 to 10 { // shift buffer elements
%2 = affine.load %1[1, %arg2] : memref<3x10xi32>
affine.store %2, %1[0, %arg2] : memref<3x10xi32>
%3 = affine.load %1[2, %arg2] : memref<3x10xi32>
affine.store %3, %1[1, %arg2] : memref<3x10xi32>
%4 = affine.load %arg0[%arg1, %arg2] : memref<10x10xi32>
affine.store %4, %1[2, %arg2] : memref<3x10xi32>
} {spatial}
affine.if #set(%arg1) {
affine.for %arg2 = 0 to 8 { // actual computation
%2 = affine.load %1[0, %arg2 + 1] : memref<3x10xi32>
%3 = affine.load %1[1, %arg2] : memref<3x10xi32>
%4 = arith.addi %2, %3 : i32
%5 = affine.load %1[1, %arg2 + 1] : memref<3x10xi32>
%6 = arith.addi %4, %5 : i32
%7 = affine.load %1[1, %arg2 + 2] : memref<3x10xi32>
%8 = arith.addi %6, %7 : i32
%9 = affine.load %1[2, %arg2 + 1] : memref<3x10xi32>
%10 = arith.addi %8, %9 : i32
affine.store %10, %0[%arg1 - 2, %arg2] : memref<8x8xi32>
} {loop_name = "j"}
}
} {loop_name = "i", stage_name = "B"}
return %0 : memref<8x8xi32>
}
}
We also add additional optimizations to make generated code more efficient. One of them is to merge loops with the same bound. The following example shows the five-point stencil code with line buffer and window buffer, and we can see that the shifting part of the line buffer is merged with the inner computation part (only generate one j loop in this example), so that the loop overhead is reduced.
#set = affine_set<(d0) : (d0 - 2 >= 0)>
module {
func @top(%arg0: memref<10x10xi32>) -> memref<8x8xi32> {
%0 = memref.alloc() {name = "B"} : memref<8x8xi32>
%1 = memref.alloc() : memref<3x10xi32>
%2 = memref.alloc() : memref<3x3xi32>
affine.for %arg1 = 0 to 10 {
affine.for %arg2 = 0 to 10 {
%3 = affine.load %1[1, %arg2] : memref<3x10xi32>
affine.store %3, %1[0, %arg2] : memref<3x10xi32>
%4 = affine.load %1[2, %arg2] : memref<3x10xi32>
affine.store %4, %1[1, %arg2] : memref<3x10xi32>
%5 = affine.load %arg0[%arg1, %arg2] : memref<10x10xi32>
affine.store %5, %1[2, %arg2] : memref<3x10xi32>
affine.if #set(%arg1) {
affine.for %arg3 = 0 to 3 {
%6 = affine.load %2[%arg3, 1] : memref<3x3xi32>
affine.store %6, %2[%arg3, 0] : memref<3x3xi32>
%7 = affine.load %2[%arg3, 2] : memref<3x3xi32>
affine.store %7, %2[%arg3, 1] : memref<3x3xi32>
%8 = affine.load %1[%arg3, %arg2] : memref<3x10xi32>
affine.store %8, %2[%arg3, 2] : memref<3x3xi32>
} {spatial}
affine.if #set(%arg2) {
%6 = affine.load %2[1, 0] : memref<3x3xi32>
%7 = affine.load %2[0, 1] : memref<3x3xi32>
%8 = arith.addi %6, %7 : i32
%9 = affine.load %2[1, 1] : memref<3x3xi32>
%10 = arith.addi %8, %9 : i32
%11 = affine.load %2[2, 1] : memref<3x3xi32>
%12 = arith.addi %10, %11 : i32
%13 = affine.load %2[1, 2] : memref<3x3xi32>
%14 = arith.addi %12, %13 : i32
affine.store %14, %0[%arg1 - 2, %arg2 - 2] : memref<8x8xi32>
}
}
} {loop_name = "j"}
} {loop_name = "i", stage_name = "B"}
return %0 : memref<8x8xi32>
}
}
The above steps can be extended to high-dimensional stencils, and we will give more experimental results in the following sections.
Write Buffer
In this section, we focus on generating the write buffer. We propose a new primitive called .buffer_at(), which generates on-chip write buffers for a certain tensor at a specified loop level. An example use case is writing partial results to memory, which will be loaded again for computation until the reduction loop finishes. Instead of writing the partial results to the off-chip memory every time, we can instantiate an on-chip buffer to hold the partial results, and write only once to off-chip memory when reduction finishes.
The .buffer_at() syntax is shown below. Tensor is the target tensor that holds write-back values. Stage is the loop nest that writes to the target tensor. Axis the loop level at which a write buffer of the target tensor is instantiated.
schedule.buffer_at(Tensor, Stage, Axis)
GEMM Example
We use general matrix-to-matrix multiplication as an example to illustrate the effect of buffer_at. We also empirically evaluate the result on the FPGA backend with Vivado HLS, which is discussed in the experiment section.
module {
func @kernel(%A: memref<1024x512xf32>, %B: memref<512x1024xf32>, %C: memref<1024x1024xf32>)
{
%li = hcl.create_loop_handle "i" : !hcl.LoopHandle
%lj = hcl.create_loop_handle "j" : !hcl.LoopHandle
%lk = hcl.create_loop_handle "k" : !hcl.LoopHandle
%s = hcl.create_stage_handle "s" : !hcl.StageHandle
affine.for %i = 0 to 1024 {
affine.for %j = 0 to 1024 {
affine.for %k = 0 to 512 {
%a = affine.load %A[%i, %k] : memref<1024x512xf32>
%b = affine.load %B[%k, %j] : memref<512x1024xf32>
%c = affine.load %C[%i, %j] : memref<1024x1024xf32>
%prod = arith.mulf %a, %b : f32
%sum = arith.addf %prod, %c: f32
affine.store %sum, %C[%i, %j] : memref<1024x1024xf32>
} { loop_name = "k", reduction = 1 : i32}
} { loop_name = "j" }
} { loop_name = "i", stage_name = "s" }
%buf = hcl.buffer_at(%s, %C: memref<1024x1024xf32>, %li) -> memref<1024xf32>
return
}
}
The above example is matrix multiplication with a write buffer at the first level in MLIR assembly code. The program multiplies matrices A and B and updates the matrix C. Operations such as hcl.create_loop_handle and hcl.create_stage_handle define loop and stage handles which are used to describe customizations. In this example, we have three loops i, j, k, and one stage s. We apply hcl.buffer_at for target tensor C in stage s at loop level i. This will create a buffer that stores 1024 values of C tensor’s one row.
module {
func @kernel(%arg0: memref<1024x512xf32>, %arg1: memref<512x1024xf32>, %arg2: memref<1024x1024xf32>) {
affine.for %arg3 = 0 to 1024 {
%0 = memref.alloc() : memref<1024xf32>
%cst = arith.constant 0.000000e+00 : f32
affine.for %arg4 = 0 to 1024 {
affine.store %cst, %0[%arg4] : memref<1024xf32>
} {loop_name = "j_init", pipeline_ii = 1 : i32}
affine.for %arg4 = 0 to 1024 {
affine.for %arg5 = 0 to 512 {
%1 = affine.load %arg0[%arg3, %arg5] : memref<1024x512xf32>
%2 = affine.load %arg1[%arg5, %arg4] : memref<512x1024xf32>
%3 = affine.load %0[%arg4] : memref<1024xf32>
%4 = arith.mulf %1, %2 : f32
%5 = arith.addf %4, %3 : f32
affine.store %5, %0[%arg4] : memref<1024xf32>
} {loop_name = "k", reduction = 1 : i32}
} {loop_name = "j"}
affine.for %arg4 = 0 to 1024 {
%1 = affine.load %0[%arg4] : memref<1024xf32>
affine.store %1, %arg2[%arg3, %arg4] : memref<1024x1024xf32>
} {loop_name = "j_back", pipeline_ii = 1 : i32}
} {loop_name = "i", stage_name = "s"}
return
}
}
.buffer_at() only specifies the buffer we want to generate. To generate the buffer, we transform the IR through a pass and generate operations that allocate the buffer, initialize it, and write it back to tensor C. The above code snippet shows the MLIR assembly code with the row buffer generated.
Interleaving Accumulation
We can combine .buffer_at() with loop reordering to achieve a technique called interleaving accumulation4. Interleaving accumulation resolves loop-carried dependency by reordering the loops to transpose iteration space. Fig. 4 shows the GEMM example after interleaving accumulation is applied.
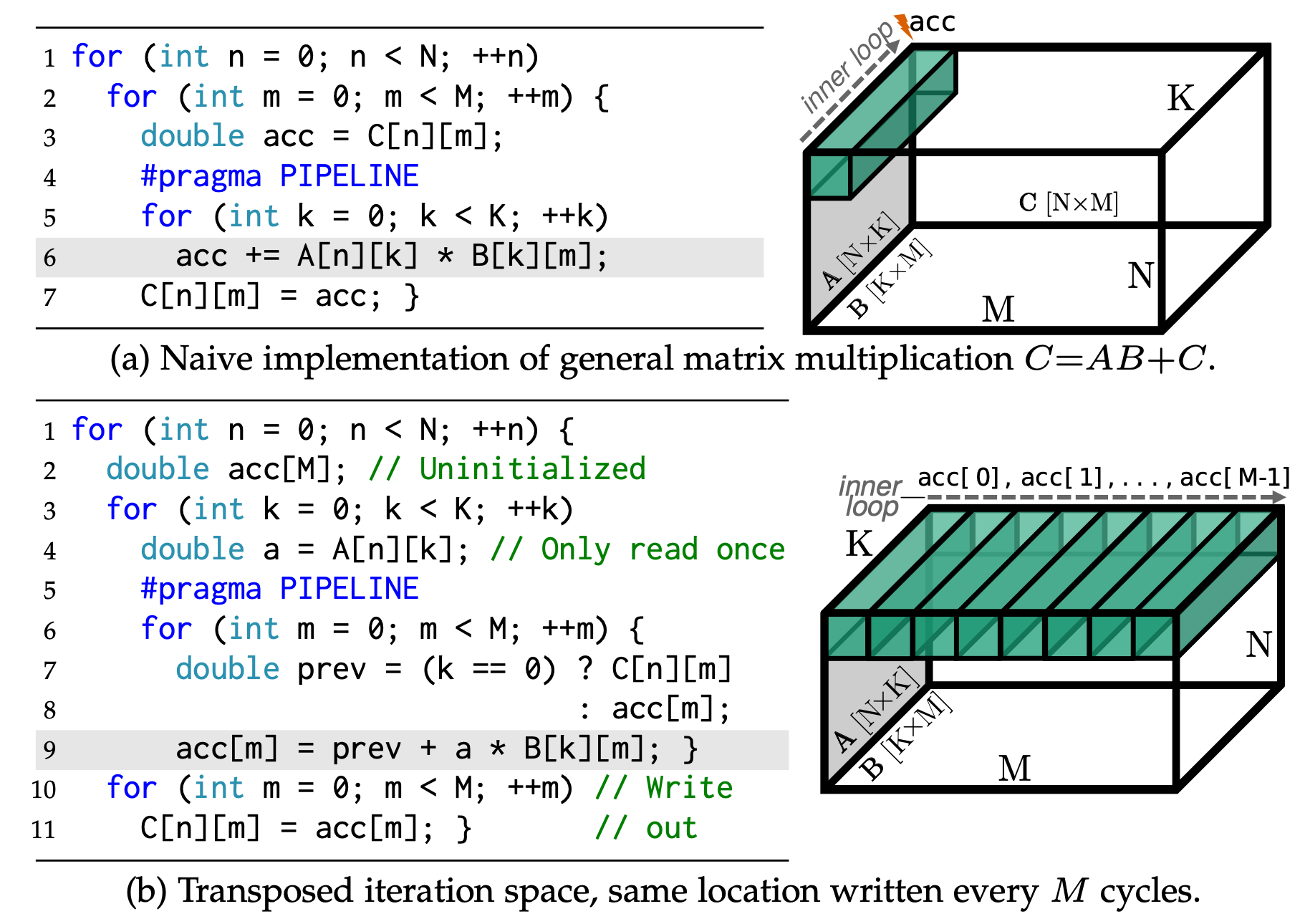
To implement the interleaving accumulation technique, we reorder the reduction loop with the outer loop in the GEMM example and add a write buffer for partial results:
module{
func @kernel(%A: memref<1024x512xf32>, %B: memref<512x1024xf32>, %C: memref<1024x1024xf32>)
{
%li = hcl.create_loop_handle "i" : !hcl.LoopHandle
%lj = hcl.create_loop_handle "j" : !hcl.LoopHandle
%lk = hcl.create_loop_handle "k" : !hcl.LoopHandle
%s = hcl.create_stage_handle "s" : !hcl.StageHandle
affine.for %i = 0 to 1024 {
affine.for %j = 0 to 1024 {
affine.for %k = 0 to 512 {
%a = affine.load %A[%i, %k] : memref<1024x512xf32>
%b = affine.load %B[%k, %j] : memref<512x1024xf32>
%c = affine.load %C[%i, %j] : memref<1024x1024xf32>
%prod = arith.mulf %a, %b : f32
%sum = arith.addf %prod, %c: f32
affine.store %sum, %C[%i, %j] : memref<1024x1024xf32>
} { loop_name = "k", reduction = 1 : i32}
} { loop_name = "j" }
} { loop_name = "i", stage_name = "s" }
hcl.reorder(%s, %lk, %lj)
%buf = hcl.buffer_at(%s, %C: memref<1024x1024xf32>, %li) -> memref<1024xf32>
hcl.pipeline(%s, %lj, 1)
return
}
}
With the same pass to implement loop reordering and buffer generation, the transformed MLIR assembly code has the reduction loop at axis 1, inner loop pipelined, and partial results written to the row buffer %0, as shown in the following code snippet.
module {
func @kernel(%arg0: memref<1024x512xf32>, %arg1: memref<512x1024xf32>, %arg2: memref<1024x1024xf32>) {
affine.for %arg3 = 0 to 1024 {
%0 = memref.alloc() : memref<1024xf32>
%cst = arith.constant 0.000000e+00 : f32
affine.for %arg4 = 0 to 1024 {
affine.store %cst, %0[%arg4] : memref<1024xf32>
} {loop_name = "j_init", pipeline_ii = 1 : i32}
affine.for %arg4 = 0 to 512 {
affine.for %arg5 = 0 to 1024 {
%1 = affine.load %arg0[%arg3, %arg4] : memref<1024x512xf32>
%2 = affine.load %arg1[%arg4, %arg5] : memref<512x1024xf32>
%3 = affine.load %0[%arg5] : memref<1024xf32>
%4 = arith.mulf %1, %2 : f32
%5 = arith.addf %4, %3 : f32
affine.store %5, %0[%arg5] : memref<1024xf32>
} {loop_name = "j", pipeline_ii = 1 : i32}
} {loop_name = "k", reduction = 1 : i32}
affine.for %arg4 = 0 to 1024 {
%1 = affine.load %0[%arg4] : memref<1024xf32>
affine.store %1, %arg2[%arg3, %arg4] : memref<1024x1024xf32>
} {loop_name = "j_back", pipeline_ii = 1 : i32}
} {loop_name = "i", stage_name = "s"}
return
}
}
Roofline Model
The Roofline Model5 is an intuitive visual performance model used to provide performance estimates of a given compute kernel running on a computing platform. The hardware limitation is illustrated as the “ceiling” in the roofline model, as shown in Fig. 5. The diagonal roof describes the peak bandwidth, and the horizontal line describes the peak performance of the specific architecture. Performance saturates at the ridge point where the diagonal and horizontal roof meet.

We add a profiling tool to calculate the operational intensity by statically analyzing the MLIR code to count the number of memory access (Bytes) and arithmetic operations (FLOPs). Specifically, we visit each operation and record the current loop nest. When an arithmetic operation or load/store operation is visited, the number of trip counts in the current loop is added. The limitation is that we only support constant loop bounds now. If complex control flow is involved, we need to do some instrumentation to dynamically count the numbers.
A roofline model is generated to guide the optimization process. The performance in the y-axis is computed by $\text{FLOPs}/\text{Latency}$, where latency is obtained from the HLS report and cannot be statically determined. The operational intensity in the x-axis is computed by $\text{FLOPs}/\text{Bytes}$.
Note that we only care about off-chip memory access, so here we need to match the operands of load/store operations with the input arguments and the return argument. The detailed experiment results are shown in the next section.
Experiments
In this section, we will first talk about the MLIR-based HeteroCL compilation flow and the experimental setup. We will later discuss the results of our memory optimizations.
MLIR-Based HeteroCL Compilation Flow
MLIR-based HeteroCL supports two backends for now: a CPU backend through LLVM dialect, and an FPGA backend through Vivado HLS. A HeteroCL program first generates HCL dialect IR, with HCL operations to represent hardware customizations. Then, a transformation pass implements hardware customizations and erases HCL operations, and the IR is converted to affine dialect, as shown in Fig. 6.

From the affine dialect level, the IR either generates HLS code through a translation pass or keeps lowering to LLVM dialect level for CPU execution.
We evaluate our memory optimizations on the open-source benchmarks6 written in HeteroCL. The HCL dialect is compiled with LLVM 14.0.0 with Python binding enabled. The evaluation machine equips with two Intel(R) Xeon(R) Silver 4214 CPU (48 logical cores in total), and we run the experiments using Vivado HLS v2019.17 targeting Avnet Ultra96-V2, which includes a Xilinx ZU3EG FPGA and 2GB LPDDR4 memory. In the following, we will describe the experimental results. All the code for experiments can be found here.
Reuse Buffer
We evaluate .reuse_at() using the following benchmarks, and read the results from HLS reports.
blur: a simple three-point 2D blur filter with $\{\mathbf{a}^{(i)}\}^{3}_{i=1}=\{(0,0),(0,1),(0,2)\}$.blur+LB: blur filter with line buffer of size $3$.conv2d-nchw: baseline conv2d implementation with conventional $(n,c,h,w)$ dimensions, and the kernel size is $3\times 3$.conv2d-nchw+LB/WB: create line buffer (LB) and window buffer (WB) for conv2d kernel.5point: the five-point stencil kernel as mentioned in the previous section (see Fig. 3).5point+LB+WB: create line buffer (LB) and window buffer (WB) for 5-point stencil kernel.diag3d: three-point stencil in 3D with $\{\mathbf{a}^{(i)}\}^{3}_{i=1}=\{(0,0,0),(1,1,1),(2,2,2)\}$.diag3d+xyz: create three hyper-cubic reuse buffers for this three-point stencil.
| Kernel | Latency | Speedup | II | DSP | BRAM | LUT | FF |
|---|---|---|---|---|---|---|---|
blur | 20.93 ms | 1x | 2 | 0 | 0 | 451 | 389 |
blur+LB | 10.486 ms | 2.00x | 1 | 0 | 0 | 451 | 406 |
conv2d-nchw | 0.69 ms | 1x | 27 | 10 | 0 | 5598 | 7051 |
conv2d-nchw+LB | 0.70 ms | 0.99x | 1 | 270 | 0 | 69477 | 55401 |
conv2d-nchw+LB+WB | 43.72 us | 15.78x | 1 | 270 | 0 | 42420 | 28387 |
5point | 27.03 us | 1x | 3 | 0 | 0 | 470 | 202 |
5point+LB+WB | 10.27 us | 2.63x | 1 | 0 | 2 | 524 | 307 |
diag3d | 0.538 ms | 1x | 2 | 0 | 0 | 814 | 240 |
diag3d+xyz | 0.326ms | 1.65x | 1 | 0 | 4 | 861 | 755 |
We can see from the result that creating hierarchical reuse buffers can always achieve an initial interval (II) of 1, and shows a large speedup for different stencil kernels with different memory access patterns. Specifically, the conv2d kernel with line buffer and window buffer achieves the fastest speedup of 15.78x. The loop fusion and pipelining contribute most to the high throughput.
Also, we notice that only adding a line buffer is not enough for high-dimensional cases, which may introduce extra processing overheads. Creating hierarchical buffers can help hide the memory access overheads and obtain the best performance.
Write Buffer
We evaluate .buffer_at() on the FPGA backend with Vivado HLS. Since creating a write buffer between PE and off-chip memory is essentially customizing memory hierarchy, and we don’t have such freedom on CPU, we omit the experiments on the LLVM backend.
| Experiment | Latency | Speedup | DSP | BRAM | LUT | FF |
|---|---|---|---|---|---|---|
gemm | 25.778 sec | 1x | 5 | 0 | 525 | 576 |
gemm+buffer | 23.639 sec | 1.1x | 5 | 2 | 677 | 617 |
gemm+acc | 2.156 sec | 11.9x | 5 | 2 | 783 | 745 |
conv2d | 6.978 ms | 1x | 5 | 0 | 739 | 619 |
conv2d+acc | 0.639 ms | 10.9x | 5 | 2 | 858 | 1586 |
gemm: baseline, without any hardware customization.gemm+buffer: buffering a row of output tensor withhcl.buffer_at.gemm+acc: interleaving accumulation with loop reordering and write buffer.conv2d: 2D convolution baseline, without any hardware customization.conv2d+acc: 2D convolution with interleaving accumulation.
We observe that buffering a row of output tensor alone brings 1.1x speedup, with some BRAM overhead. Using interleaving accumulation to remove loop-carried dependency delivers 11.9x speedup compared to baseline.
In addition to the GEMM example, we add 2D convolution experiments with interleaving accumulation. Similarly, we first reorder the reduction loops and their outer loop, then create a write buffer and add pipelining. The complete implementation is here. Convolution with interleaving accumulation has 10.9x speedup to baseline, also with some BRAM and FF overhead.
Roofline Model
We draw the roofline model for all the kernels above to show the effect of optimizations. The peak performance of our target Ultra96-V2 is 18GFLOPs, and the peak bandwidth is 25.6GB/s. The diagonal roof and horizontal roof can be drawn using these two parameters. Each kernel is represented as one point in the figure.
Fig. 7 shows the roofline model for each of the two optimizations we implement. Fig. 7(a) shows 4 kernels with and without reuse buffer optimization, and Fig. 7(b) shows 2 kernels with and without write buffer optimizations. All the points move upper right in the roofline model after optimizations. Note that some points overlap with the baseline in this figure because of the scaling ratio. The detailed analysis for each kernel is illustrated as follows.

Fig. 8(a) shows Roofline Model analysis on Blur kernel with reuse buffer optimization. By adding line buffer, we decrease both the number of off-chip memory access and latency, making the point move upper right. Fig. 8(b) shows reuse buffer optimization on Conv2D kernel. With line buffer, redundant off-chip memory access is eliminated. But only with another window buffer, the performance can be largely improved. Fig. 8(c) and (d) show similar trends when adding reuse buffer.

Fig. 9(a) shows Roofline Model analysis on GEMM kernel with write buffer optimization. Adding write buffer could decrease off-chip memory access, but the performance is largely improved after applying interleaving accumulation. Fig. 9(b) shows similar results on Conv2D kernel.

Conclusion
In conclusion, we enhance the memory customization ability and add performance profiling infrastructure to MLIR-based HeteroCL. We extend the .reuse_at() primitive to generate reuse buffers for 3D and higher dimention tensors. We propose a .buffer_at() primitive to generate write buffers and demonstrate its use cases with interleaving accumulation. Finally, we add a profiling tool to evaluate operational intensity and plot a roofline model to guide users to make optimizations.
References
Yi-Hsiang Lai, Yuze Chi, Yuwei Hu, Jie Wang, Cody Hao Yu, Yuan Zhou, Jason Cong, Zhiru Zhang, “HeteroCL: A Multi-Paradigm Programming Infrastructure for Software-Defined Reconfigurable Computing”, FPGA, 2019.
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, Oleksandr Zinenko, “MLIR: Scaling Compiler Infrastructure for Domain Specific Computation”, CGO, 2021.
Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou, “SODA: Stencil with Optimized Dataflow Architecture”, ICCAD, 2018.
Johannes de Fine Licht, Maciej Besta, Simon Meierhans, Torsten Hoefler, “Transformations of high-level synthesis codes for high-performance computing”, TPDS, 2020.
Williams, Samuel, Andrew Waterman, and David Patterson, “Roofline: an insightful visual performance model for multicore architectures”, Communications of the ACM, 2009.
HeteroCL test programs, https://github.com/cornell-zhang/heterocl/tree/hcl-mlir/tests/mlir
Vivado HLS, https://www.xilinx.com/support/documentation-navigation/design-hubs/dh0012-vivado-high-level-synthesis-hub.html