One VM to Rule Them All
A Short Story
You are the latest hire for the startup company QuantBet which specializes in developing computational models that are used for proprietary sports betting. QuantBet is fairly new, and as a gifted PL researcher, you are tasked with creating a new programming language QuantPL to assist gamblers in their analysis.
Sports betting is a fast business, and you want your code to run quickly. You begin your project by developing a parser for QuantPL and an Abstract Syntax Tree (AST) interpreter.
Your colleagues are impressed by your work with QuantPL which they claim is more intuitive when scripting models. But soon, they start to notice that it's a lot slower than what they're used to.
You think about developing a real VM. This would require spending a lot of time designing a run-time system in C without causing memory leaks. You think about using Java instead as your backend. You may have to even design a bytecode format and interpreter. If they complain more, you'll have to hire others to help you write a JIT compiler. This is a slow, costly and painful process.
You hear that rival company Quant2Bet has developed a language Quant2PL that is almost as fast as Java code without much effort. They're using something called Truffle and Graal, and only had to write an interpreter and a few high-level specialization strategies which automatically transformed into a JIT. Now you're stuck modifying your programming language from the very beginning. You decide this isn't worth your time, quit your job, and join Quant2Bet instead.
A Solution
"One VM to Rule Them All" (2013) presents an architecture that allows implementing new programming languages within a common framework, allowing for language-agnostic optimizations. Instead of designing the entire stack for a new programming language, you can just focus on creating a parser and AST interpreter. Now, you can reuse functionality from existing virtual machines and your language is already fast and optimized. In the following sections, we call the new language that we are trying to build the guest language and the backend for this infrastructure that acts as an interpreter the host language.
Background
- The Java Virtual Machine (JVM) is a virtual machine that allows computers to run programming languages that compile to Java bytecode.
- A Just-In-Time (JIT) compiler compiles a program at run time instead of before execution.
- Dynamic Dispatch is the process of iterating through implementations of a polymorphic operation and selecting which one to call at run time. Java implements runtime polymorphisms using dynamic dispatch. If a method is overwritten, the type of object determines which version of the overwritten method is called.
One VM to Rule Them All
This paper claims the following:
- A method of rewriting nodes in which an AST node can rewrite itself into a more specialized or general node. Nodes capture constructs of the guest language, such as addition or division.
- An optimizing compiler that takes in the structure of an interpreter and turns it into a compiler that emits bytecode. In Graal, the compiler is written in a subset of Java.
- A method called speculative assumption in which heuristics determine the probability of executing certain sections of code. For less frequent sections, deoptimization disregards compiled code and switches to execution using interpretation.
The combination of these claims result in high performance from an interpreter without the need of implementing a language-specific compiler.
Truffle and Graal
The prototype of the language implementation framework is called Truffle and the compilation infrastructure is called Graal, both of which are open source by Oracle. At a high level, a user of this ecosystem implements an AST interpreter for the guest language. In the interpreter, each node encapsulates information regarding a construct of the guest language. An addition node, for instance, may be specialized for integer, double and string inputs.
Node rewriting occurs during interpretation, using profiling feedback. When a subtree of the AST is deemed to be stable (meaning unlikely to be rewritten), the AST is partially evaluated at that subtree and the Graal compiler produces optimized machine code to run on the VM. The partial evaluation occurs with aggressive inlining alleviates the overhead in interpreter dispatch code.
If during execution a node is not the correct specialized type, we deoptimize. The optimized machine code is discarded and we switch to AST interpretation. The node rewrites itself and the subtree is then recompiled.
Here, dynamic compilation is agnostic to the semantics of the guest language.
Example
The below diagram describes an instance of an AST interpreter during execution. In Figure 1, nodes are first uninitialized. After profiling feedback, nodes are rewritten to become specialized and are then compiled.
Now suppose in Figure 3, there is integer overflow. Continuing our example with JavaScript as the guest language, this would cause a change in value type. Our speculation that all nodes in that subtree are of type integer is incorrect, so we have to deoptimize, rewrite a second time, and then recompile. Note that node rewriting is not just for type transitions, but for any time of profiling feedback.
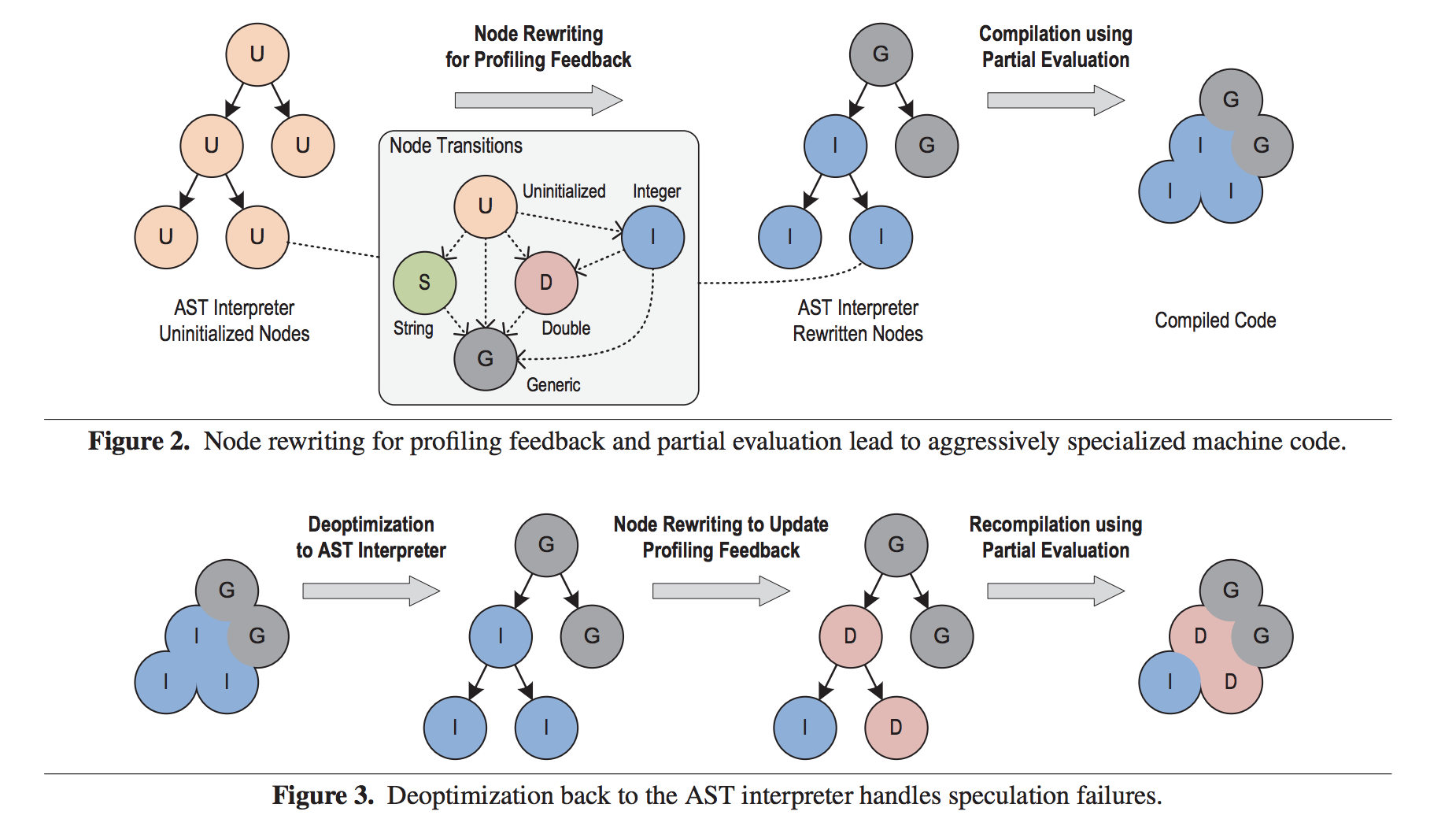
Node Rewriting
It is the duty of the developer of the guest language to implement node rewriting. As a guideline, the authors of the paper suggest that developers fulfill the following:
Completeness - Each node must provide rewrites for all cases that it does not handle itself.
Finiteness - The sequence of node replacements must eventually terminate to either a specialized node or a generic implementation that encompasses all possible cases.
Locality - Rewrites occur locally and only modify the subtree of the AST.
Examples of optimizations that use profiling feedback are type specializations, polymorphic inline caches and resolving operations. As program is successively executed, the profiler yields more optimized compiled code.
Consider the following example, where the guest language is JavaScript:
```
function sum(n) {
var sum = 0;
for (var i = 1; i < n; i++) {
sum += i;
}
return sum;
}
```
The following is an example of an AST after immediate parsing. Note that only constants are typed.
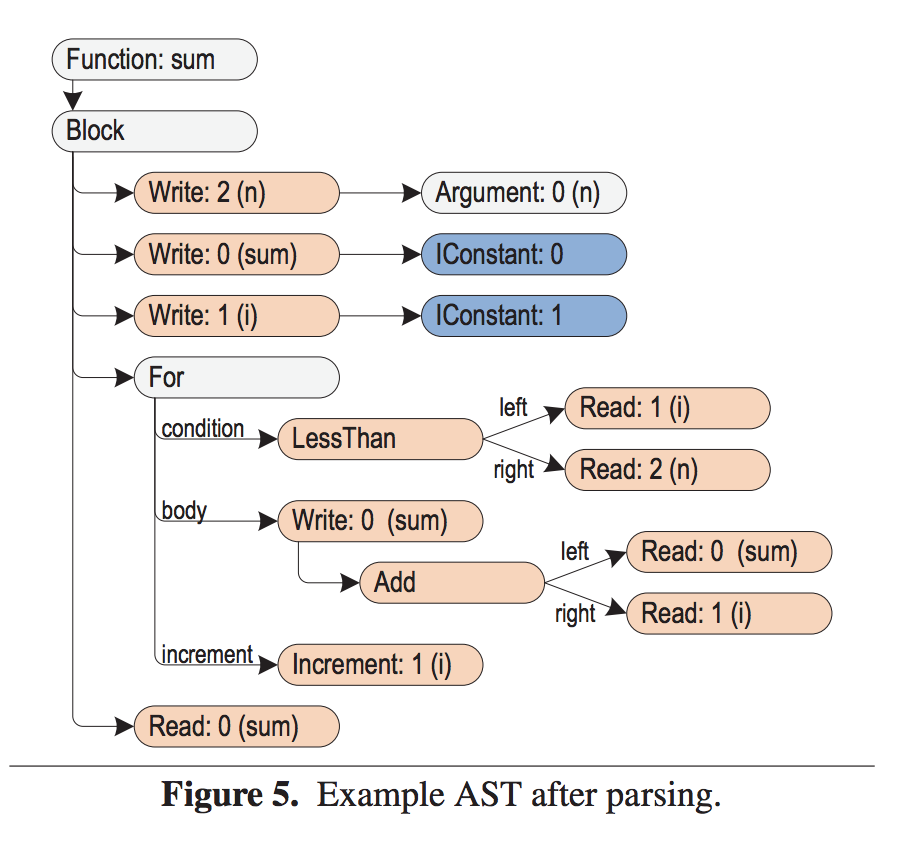
In code, we can write the integer addition node as follows. Here, Java is the host language for the JavaScript interpreter.

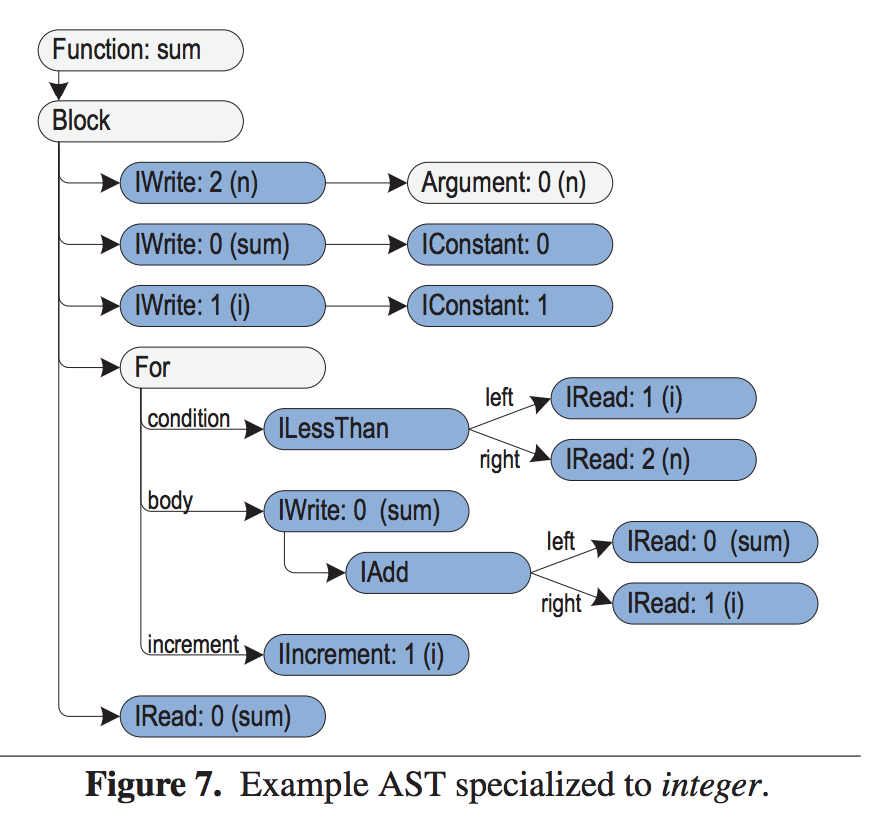
After execution, nodes replace themselves as specialized nodes for type integer called IAdd to be used for subsequent executions. Note that IAdd nodes only operate on integer values. If it does not receive an integer value, it will throw an exception, and the node will be rewritten.
The below picture shows an instance where nodes are specialized for the integer type (depicted by prefix "I").
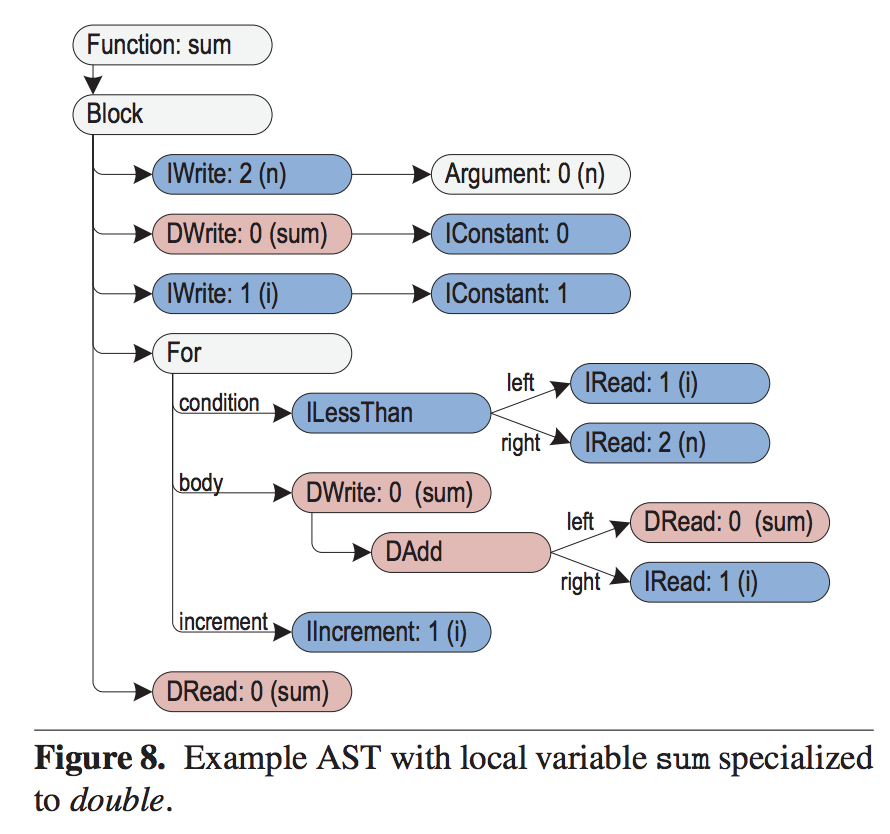
If sum overflows, we need to rewrite certain nodes to specialize for the double data type (prefix "D"). The following image shows this case:
We can actually write more compact code using Java annotations if the host language is Java. For a given node, in this case add, we can use the annotation @Specialization to denote a specialized implementation and use @Generic to denote the default, unspecialized implementation. Now the Java compiler will call the Java Annotation Processor which iterates over all Node Specifications, marked by the annotations. It is essentially the same as before though now we can use developer tools and IDEs more seamlessly.
Performance
The main overhead is dynamic dispatch between nodes when rewriting occurs. To do this, we count the number of times a tree is called, and when it exceeds a certain threshold, the tree is assumed to be stable and is then compiled. Deoptimization points invalidate the compiled code, allowing for the node to be rewritten. The counter is reset, and after the threshold number of executions it will be deemed stable and compiled again.
This architecture allows for additional optimizations, such as:
Injecting Static Information: where a node adds a guard that leads to a compiled code block or a deoptimizing point.
Local Variables: where read and write operations on local variables are delegated to a Frame object that holds values. Escape Analysis is enforced allowing static single assignment (SSA) form.
Branch Probabilities: where probabilities of branch targets are incorporated to optimize code layout which decrease branch and instruction cache misses.
Current Implementation and Deployment
Currently, this infrastructure is prototyped using a subset of Java.
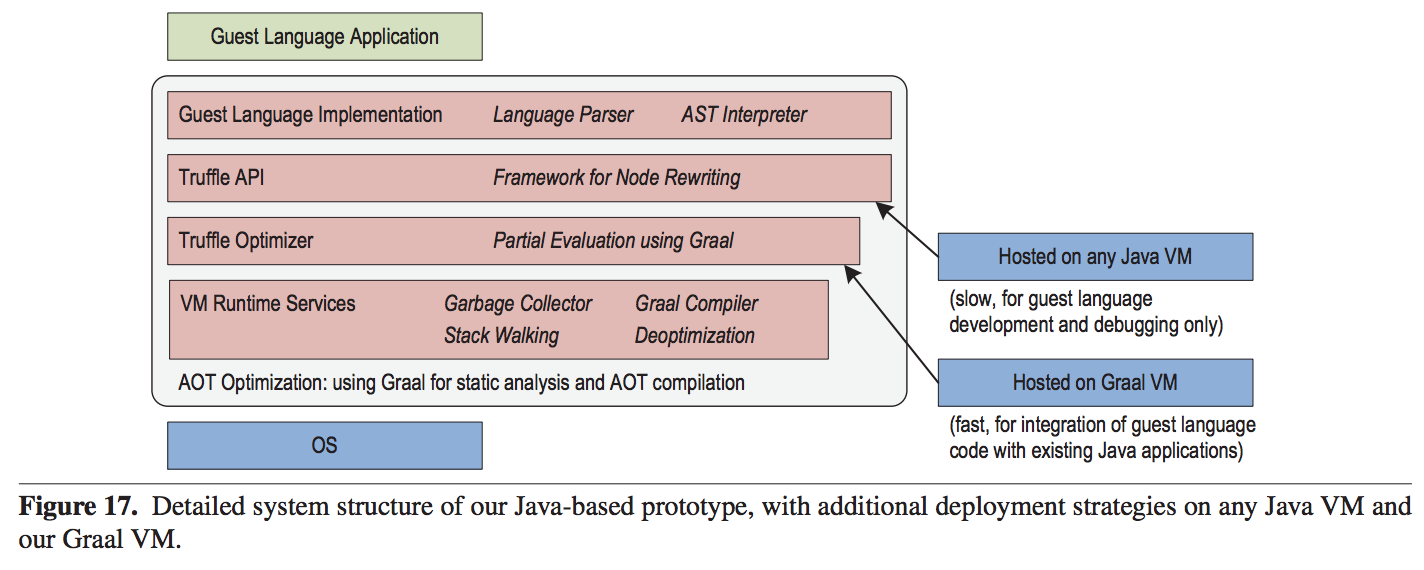
The Truffle API is the main interface to implement the AST. The Truffle Optimizer involves partial evaluation. The VM Runtime Services provides basic VM services which includes Graal.
The authors suggest two main deployment scenarios:
Java VM: The current implementation is in Java so it can technically run on any Java VM. This is especially useful for debugging and low cost.
Graal VM: This provides API access to the compiler, so the guest language runs with partial evaluation. This uses Graal as its dynamic compiler and is extremely fast. It is useful for integrating the guest language in a current Java environment.
A Survey on Languages
The following languages have been tested by the authors: JavaScript, Ruby, Python, J, and R. We will expand upon the first two as they pose interesting points.
JavaScript has many implementations, several which are of high performance. Node rewriting is used for type specialization and inline caching. Type specialization has been described before in the int/double example for addition. Inline caching seeks to optimize operations that are performed on specific-type objects. The implementation of this is similar to pattern matching in functional languages such as Haskell or OCaml.
Ruby is even more interesting. Ruby allows to redefine any method, so naturally, deoptimization can be applied to invalidate compiled nodes. Most notably, later papers indicate that Ruby implemented with Truffle is 45x faster than MRI (C backend). Truffle JVM is also approximately 2x faster than Topaz.
One question I'd like to pose is do these results change if the backend compiler were written in C instead of Java?
Merits and Shortcomings:
Merits
This is an interesting idea that definitely is worth exploring when implementing the backend for a new programming language. The main merit of Truffle is the ease of implementing a new programming language. The developer only has to implement an AST interpreter, and Truffle handles the rest of the heavy lifting. The main merit of Graal is its ease of pairing with Truffle. Graal itself is an impressive compiler which can run both JIT or AOT, has many optimizations as previously discussed and can convert Truffle ASTs into native code. Graal is also easily extendable for new optimizations.
Most of Truffle/Graal is available open-source!
Shortcomings
One shortcoming I noticed was the amount of memory needed for this ecosystem during runtime. At deoptimization points, metadata is stored, the partially evaluated AST is reloaded and the original AST is also kept in memory. This is a lot of information, and the different speculative optimization add even more memory usage. Running this compiler will consume a lot of RAM which can be costly and may even outweigh performance. This is not to mention the memory cost of Truffle and Graal themselves at runtime. Currently, SubstrateVM is a suggested solution to this shortcoming which aims to reduce the memory footprint of applications by compiling Java programs into executable containers. But SubstrateVM itself has many shortcomings, including dynamic class loading/unloading, finalizers, etc.
Another shortcoming involves the author's solution to the dynamic dispatching problem. The authors describe keeping a counter, and only after the counter reaches a threshold, the AST is compiled for each specialization within a node. This means that peak performance only occurs after many iterations of the program, when node rewriting is unlikely. Traditional JITs have a similar approach where code is compiled once it is "hot". However since in this paper, only a specific portion of a node is compiled, it may take even longer for the execution count to reach the threshold, since all executions would have to follow the same specialized path. Considering the example of the addition node, suppose that the snippet of code involving adding two integers is compiled. In a subsequent execution, if the node is rewritten to double addition, the execution counter resets, whereas in a traditional JIT compiler, the entire node would remain compiled.
In Industry
Both Twitter and Goldman Sachs have prototyped integrating Truffle/Graal into their stack.
Related Work
PyPy is runs much quicker than Python. Python is normally interpreted in CPython. PyPy runs faster than CPython since it is a JIT compiler. PyPy implements a Python VM written in RPython. PyPy is also a meta-JIT that people use to write JITs for languages.
Metacircular VMs are written in the guest language instead of the host language. This allows sharing between the host and guest systems.
Self Optimizing Interpreters rely on improving interpretation performance during execution. This paper claims that since compilers analyze larger portions of the code, it can perform global optimizations that an interpreter is not able to do.
It would be interesting to quantify this statement and develop interpreter optimizations to combine with Graal. I curious to see if interpreter optimizations in general make a significant difference.
Final Thoughts
The paper is interesting in its claims, though it does not provide benchmark tests. The main benchmark I was surprised that the paper did not include is how guest language performance using the Truffle/Graal ecosystem compares with the LLVM compiler for a variety of languages.
It actually took a lot of searching, and eventually I found a talk by Thomas Wuerthinger at Devoxx which shows the following performance measures. Maybe these weren't measured at the time of publishing this paper, or the authors were wary of displaying results that are marginally the same as their counterparts.
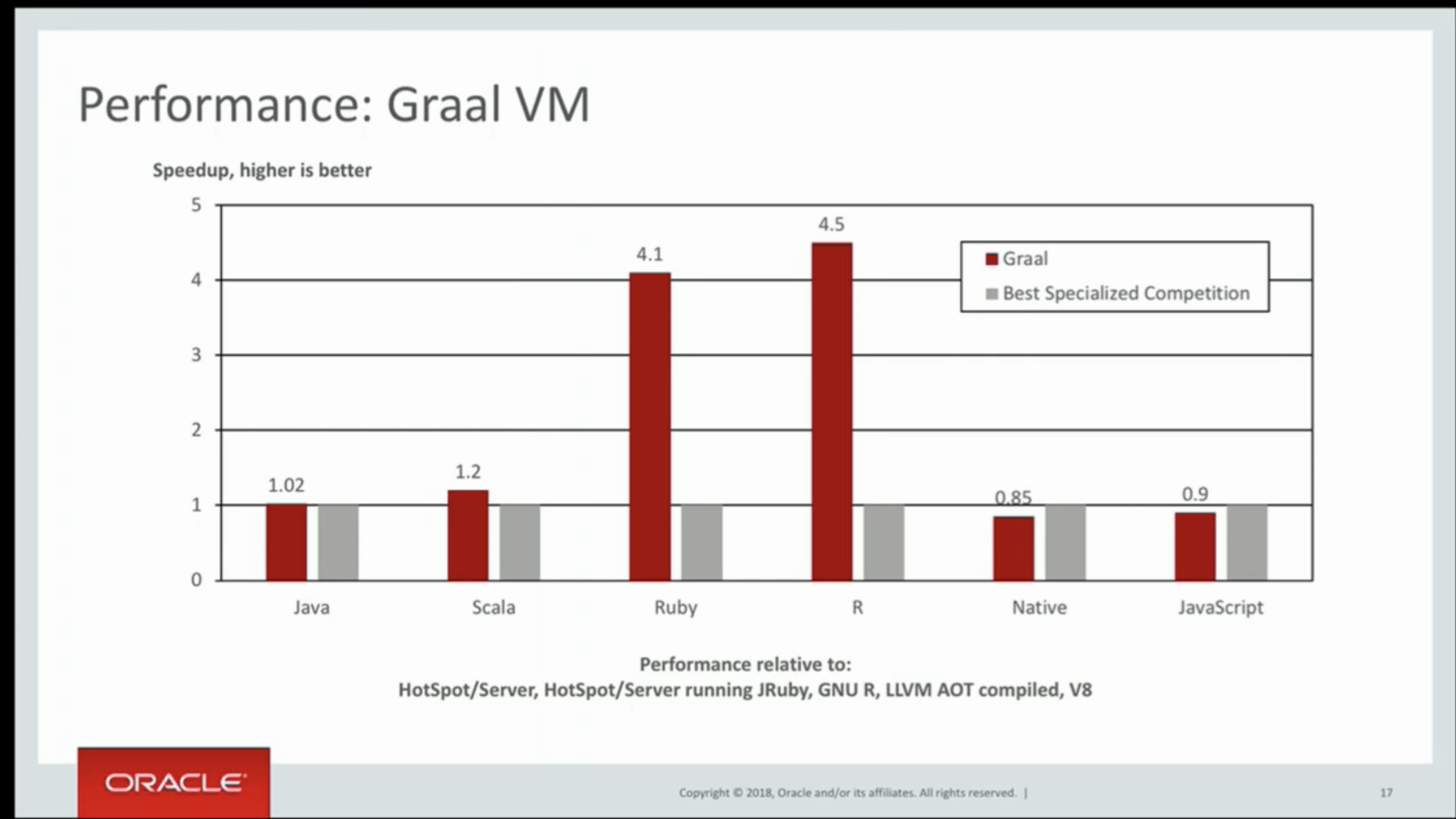
This paper also markets Truffle/Graal as the first of its kind, but in its references, it acknowledges that it is actually not. I mainly attribute this to the fact that the paper was published out of Oracle Labs and there may have been conflicts of interest between academics and industry-minded folks. In fact, on a YCombinator message board thread, developers openly refuse to even consider using a product by Oracle.
Related Reading
Metropolis which tries to implement Java using Java.
Top 10 things to do with GraalVM.
Getting Started with GraalVM.