Vector Instruction Support in the Bril Interpreter
Problem Statement
The Bril interpreter does not take advantage of the vector instructions available in modern CPUs. This presents two problems: the first is that a Bril backend cannot generate vector instructions because they are not present in the intermediate language. The second issue is that interpreting vector instructions is slow because it requires a loop over each vector element. We propose to support vector instructions in the interpreter and accelerate the interpretation of them using intrinsic vector instructions.
Vector Instructions
Single-Instruction Multiple-Data (SIMD) allows computer hardware to obtain significant speedups over the conventional execution paradigm, Multiple-Instruction Multiple-Data (MIMD). SIMD executes fewer instructions than MIMD to accomplish the same amount of work. In SIMD, multiple arithmetic operations are grouped together under one instruction. Generally, this arithmetic is executed over multiple execution units at the same instant (spatial SIMD), although some implementations allow the same instruction to use the same functional unit over multiple cycles (temporal SIMD). Various hardware architectures allow the programmer to support SIMD by exposing vector instructions in their ISA. Typically, there is a vector register file which holds multiple elements per register and can participate in vector arithmetic.
Vector Support in the Bril Interpreter
Memory Support
Vector instructions are only useful when operating on large chunks of data. Conversely, registers are not designed to hold this amount of data. A prerequisite for vector instructions is support for data memory in the interpreter. The interpreter memory is implemented as a flat heap. The program is allowed to access any location in the fixed size memory and there is no memory management.
Memory access requires both load and store operations. To emulate arrays, we can loop over multiple addresses and perform a load and/or store at each location. Load and store instructions in Bril are implemented similarly to their assembly counterparts. A load takes in a memory address (an int register in Bril) and writes to a destination register. A store is an effect operation and does not write to a register. It uses two source registers: a register containing a value and a register containing an address. The Bril syntax is given below.
// load value from address 2 addr: int = const 2; data: int = lw addr; // store value to address 2 sw data addr;
Interpreted Vector Instructions
Vector instructions were added to the Bril interpreter. We specifically implement fixed-sized vector instructions of length four (akin to native Intel __m128 SSE instructions). TypeScript and JavaScript (TypeScript always compiles to JavaScript) do not have support for vector intrinsic in the current standard. Thus, we implement the Bril vector instructions as a loop over four values. Additionally, we add vector registers in Bril which must be used in the vector instructions. We target a vector-vector add (vvadd) program, so we include interpreter support for vadd, vload, and vstore instructions. The vload and vstore instructions communicate data between vector registers and the interpreter stack. The vadd instructions adds two vector registers and writes to a destination vector register. An example vvadd program is shown below.
// locations of memory (arrays of 4 elements) a: int = const 0; b: int = const 4; c: int = const 8; // load into src vector registers va: vector = vload a; vb: vector = vload b; // do the vector add vc: vector = vadd va vb; // store from vector register to memory vstore vc c;
Intrinsic Vector Support
It's awkward that the interpreter supports vector instructions but doesn't actually use a native vector assembly instruction to perform the computation. We expect that the performance of the interpreted vector instructions will be poor. To explore this hypothesis, we create a version of an interpreted vector add instruction using three methods: 1) TypeScript, 2) serial C++, and 3) vectorized C++. We run each test for 10,000 iterations and average the execution time over five runs. We assumed 10,000 iterations was enough time for the Node (Google V8) JIT to warmup. The average time per loop iteration for each implementation is given below.
| Method | Time per iteration (ns) |
|---|---|
| TypeScript | 317 |
| Serial C++ | 16 |
| Vector C++ | 9 |
There is a fair benefit to using native vector instruction from C (35x) speedup over the TypeScript version. A large portion of this benefit comes from just using C in the first place. The serial C version achieves 20x better performance while the vector version further improves the performance by a more modest 1.8x.
C++ binding for TypeScript
In order to utilize vector intrinsic, we need to call the C++ implementations in the Bril interpreter. We use nbind to allow TypeScript to execute binaries generated from C++. These sorts of calls will add potentially significant overhead to the execution. We quantify this overhead to see if it is practical in the interpreter. Note that each time we run a single vector instruction we must make a call to the binding. We run a vector add program with various iterations. Each iteration does two vector loads, a vector add, and a vector store along with instructions to facilitate the iteration. We run five configurations (128, 1024, 2048, 4196, 8192) and average the execution time over five runs. We compare the execution time with and without calls to the binding (literally just comment the line out). Note that the calls include passing arguments to the C++ binary, which incurs some additional overhead. On average there is a 10% overhead in the program due to the binding call. This overhead is expected to be offset from the substantial speedups offered by the C++ implementation.
Evaluation
Correctness
We write multiple test programs to verify that the memory and vector instructions functioned as expected. Turnt is used to test the expected output of the program from print instructions. The vector programs could not be verified with Turnt, however, because it needs to be executed in the interpreter directory to find the location of the C++ binaries. These programs were verified by manually inspecting the output. We test a simple store and then load, multiple stores and then multiple loads, and vvadd with both the TypeScript implementation and the C++ vector implementation. All functioned as specified in this document.
Performance
We evaluate the effectiveness of using intrinsic vector functions in the Bril interpreter. We run a multi-iteration vvadd program where each iteration does a single vector add of four elements. The program is shown below.
// initialize number of iterations size: int = const 8192; vecSize: int = const 4; // initialize data locations a: int = const 0; b: int = add a size; c: int = add b size; // loop i: int = const 0; vvadd_loop: // get base addresses to add ai: int = add a i; bi: int = add b i; ci: int = add c i; // do the vvadd va: vector = vload ai; vb: vector = vload bi; vc: vector = vadd va vb; vstore vc ci; // iterations (increment by vector length) i: int = add i vecSize; done: bool = ge i size; br done vvadd_done vvadd_loop; vvadd_done:
Notice that the program does not initialize values in memory or print the results. We do not want to include the initialization and cleanup time in the measured runtime. In the future, we could implement a Bril timer on/off instruction that could solve this problem. We time the execution of the interpreter using JavaScript's console.time and console.timeEnd functions. We take care not to time the file I/O part of the interpreter as this would dominate the runtime for the program sizes that we run.
We run vvadd with various iteration amounts (128, 1024, 2048, 4098, and 8196). We average the runtime of five executions of the same program. Our baseline is the TypeScript implementation of vector instructions. The following figure shows the speedup of various implementations relevant to the baseline. Our performance metric is the execution time of the whole program.
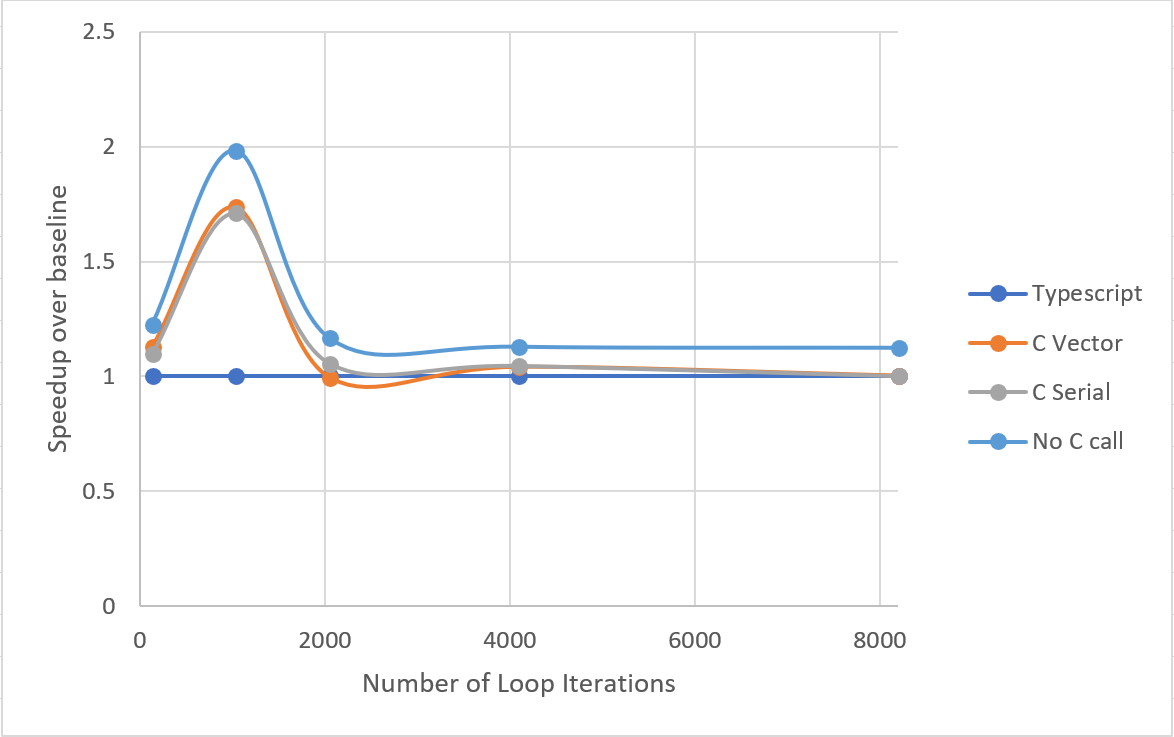
The C++ implementations outperform the TypeScript implantation at a smaller number of iterations. However, the performance equalizes for higher iterations. This is potentially due in part to the JavaScript JIT warming up on later iterations and matching the C++ generated code. However, C++ is still expected to get much better performance up to this point as measured previously. The JIT hypothesis does not explain the full trend.
The C++ implementations have very similar execution times even though a 2x performance gap was expected. This suggests that there is a bottleneck in the interpreter apart from the C++ implementations.
Both of these results are likely due to the overhead in TypeScript. The 4th series in the graph shows the speedup if the C++ calls are removed altogether (commented out). This results in a slight speedup, but not a substantial one. We can conclude that the TypeScript runtime dominates the execution time and optimizing the C++ implementation or binding calls will have little effect on the overall performance.
Conclusion
We were able to correctly implement vector instructions in the Bril interpreter. However, we were not able to obtain execution speedup of these instructions due to slowness of TypeScript. If one wanted to get speedups in the interpreter it would need to be written fully in C++ (or another fast language) rather than making fine-grained calls to C++.
In this work, vectorization was manually implemented in Bril. Future work could create a pass to automatically unroll loops and insert vector instructions.