Efficient Instruction Scheduling for Pipelined Architectures
Introduction
A pipelined architecture allows for machine instructions to overlap each other for greater throughput, but it comes with the cost of pipeline hazards. These hazards emerge when one structural or data resource is needed by more than one instruction, forcing the hardware to resolve the hazard by delaying subsequent instructions for one cycle, known as a pipeline interlock (a.k.a., stalls). These interlocks decrease throughput and this paper proposes a heuristic way to minimize interlocks that has a better worst-case runtime than other solutions while maintaining comparable results.
Background
Pipelined Processors
As a quick refresher, pipelined processors allow different instructions to execute on different parts of the processor which offers significant improvements over single-stage processors where only one instruction is live at a time. A very basic pipeline structure may have the following stages, in order: Fetch, Decode, Execute, Memory, Writeback.
Pipeline Hazards
You may recall from CS 3410 or another equivalent systems class that there are three types of hazards:
- Structural - A hardware resource is needed by multiple instructions in one cycle.
- Data - A piece of information is needed before it is available.
- Control - A branch is not resolved when the next instruction location is needed.
We can ignore control hazards as this paper only reorders instructions within a basic block.
The architecture of this paper is based on has three hazards:
- Loading to a register from memory and then using that register as a source. This is commonly known as a load-use hazard.
- Any store followed by any load.
- Loading from memory followed by any arithmetic or logical instruction.
For example, this program with a load-use hazard:
load 0(sp), r0 add #1, r0, r0 //hazard caused by use of r0 immediately after load add #5, r1, r1
Rescheduling it as follows eliminates the hazard:
load 0(sp), r0 add #5, r1, r1 add #1, r0, r0 //r0 not used immediately after load
We were unsure of why the second and third hazards presented by the paper were problematic, and we will discuss it later in this post. For now, it is sufficient to accept that they are hazards for their target architecture.
Summary
Goals
The authors wanted to target a range of architectures which could differ in what constituted hazards and how interlocks are implemented. To this end, it was not possible to prevent all interlocks for all architectures, but rather to design a heuristic algorithm that performed well in general. They also wanted this algorithm as efficient as possible to improve practicality.
Assumptions
To create an algorithm that was generalizable across architectures, the authors made three important assumptions to simplify the problem:
- Each memory location is assumed to be referenced by an offset from one base register.
- We were unsure of why this was needed. Our best guess is that more complex addressing modes could take too long calculate, such as scaled indexing which could need multiplication, or memory indirect indexing which could take multiple cycles to return.
- All pointers are assumed to alias (though this can be made tighter if the compiler produced aliasing information).
- The target architecture will have a hardware hazard detection with interlock such that it is not necessary to remove all hazards.
Technical Approach
This optimization is carried out by reordering assembly instructions after code generation and register allocation. It acts on basic blocks and it's a transformation from assembly to assembly. To create such a transformation, scheduling constraints first need to be modeled and then the heuristic for selection order must be applied while abiding by those constraints. The scheduling contraints provide all sets of orderings that guarantees correctness and then the heuristic chooses the ordering that the most likely to have the least amount of hazards.
Expressing Constraints
As instructions cannot be arbitrarily reordered due to dependencies, they are placed in a directed acyclic graph (dag) where each node (an instruction) succeeds the instruction(s) it is dependent on. In terms of scheduling, this means that parent nodes must be executed before child nodes, and root nodes do not have dependencies so they can be placed wherever convenient.
This dag serializes based on three criteria, followed by an example for each:
-
Definitions vs. definitions:
load -8(sp),r4 //r4 is defined add #1, r0, r4 //r4 is redefined
-
Definitions vs. uses:
store r0, A //A is defined load A, r5 //A is used as a source
-
Uses vs. definitions:
load -4(sp), r3 //sp is used add #8, sp, sp //sp is defined (and also used)
This criteria is broad enough to account for all serialization constraints. Deployed on a larger example, the dependency dag will look like:
| Instruction List | Dependency Dag | Reordered Instructions |
|---|---|---|
 | 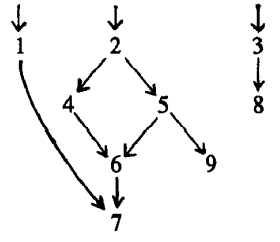 |  |
This dag is created by scanning backward through the block, and for each instruction, finding the definitions or uses that precede it. As such, this construction costs O(n2) where n is the number of instructions in the basic block.
There are also carry/borrow dependencies which are definitions or uses of carry/borrow bits, which should be treated similarly to a register since they are another stateful processor resource. They are changed during arithmetic operations where a carry or borrow is used, making them frequently defined but rarely used. Adding them to the dependency dag would be unnecessarily constraining, so the authors placed them in a special subgraph for instructions that uses a carry or borrow.
This dag representation differs from other literature on instruction ordering as they include edges for definitions vs definitions. This is necessary for the final definition of a resource at the end of a basic block (as it could be used by instructions that follow the basic block), or for defs to one register followed by a read from the same register.
Selecting an Order: The Static Evaluator
Now, using this dag, any scheduling order following a topological sort will produce an execution indistinguishable from the original order.
Their algorithm travels down the dag from the roots and selects candidates---instructions whose immediate predecessors have all been scheduled (or root instructions).
When choosing the "best" candidate to schedule, they provide two guidelines:
- Schedule an instruction that will not interlock with the one just scheduled (if possible).
- Schedule the instruction that is most likely to cause interlocks with instructions after it. If an instruction may cause interlock, they want to schedule it as early as possible.
Lookaheads would definitely improve scheduling, but that also significantly increases worst-case complexity. Instead, they use three concrete heuristics that evaluate the candidates' static local properties. In order of importance, they are as follows:
- Whether an instruction interlocks with any of its immediate successors.
- The number of immediate successors.
- The height of the daf rooted at that node.
These criteria yields instructions which:
- May cause interlocks. This is desirable because it allows instructions that are likely to interlock to be scheduled as early as possible as that gives the greatest number of candidates for subsequent instructions.
- Uncover the most potential successors, thereby giving greater freedom of future choices.
- Balance the progress along the paths of the dag, which ensures a more even number of choices throughout the process.
The steps in this algorithm for dag traversal and scheduling are outlined pretty clearly in the paper and so we will not duplicate them here. The final result is displayed in the table above. The original order had four interlocks (referring to instructions via line number): 3-4, 5-6, 7-8. and 8-9. The reordered version only has one: 8-1.
Computational Complexity of the Algorithm
Let the number of instructions in the basic block be n.
Constructing the dag
In the worst case, every instruction needs to be compared with the instructions already in dag. During this process, we can also compute the information needed by the heuristic evaluation, such as the length of the longest path and the number of immediate successors. It is thus O(n2).
Scheduling the instructions
To schedule an instruction, we need to evaluate all the candidates based on the heuristic. Evaluation can be done in O(1) because we already build the dag contains all the relevant information. Thus, scheduling is also O(n2).
Overall complexity
The overall complexity is O(n2). This is significantly better compared to other algorithms in this space which are O(n4), even when adjusted to have similar hardware assumptions.
Experiments
The authors implemented this instruction scheduler and made the following observations from benchmark results:
- In practice, these heuristics effectively remove avoidable interlocks and run in approximately linear time.
- The memory referencing assumptions greatly improve results, and effectiveness increases with better aliasing information (provided by other parts of the compiler).
- The carry/borrow subgraph (the dag for carry/borrow dependencies) does not improve much for most programs. Significant improvements only occur when the program is computationally intensive.
- It is unclear as to how they would improve scheduling as they are for constructed for correctness.
- Using more versatile dags proposed by other literature only slightly improves the instruction scheduling effectiveness, despite them having significantly worse complexity.
The referenced additional information on performance in the [Joh86] paper which tested load/store scheduling and showed a 5% improvement. It was published in the same proceedings by colleagues working on the same architecture, and this improvement was measured by the reduction in interlocks caused by load/store instructions.
Such a small suite of benchmarks and statistics would be unacceptable today, but it was perhaps okay for 1986.
Our Thoughts
This paper left a few things to be desired.
First, we did not quite understand some of the hazards this paper was concerned about. The first hazard of "loading a register from memory followed by using that register as a source" is clear as that's a traditional load-use hazard where the load finishes at the end of the cycle while the value it was loading was needed at the beginning of the cycle.
However, the second hazard of "storing to any memory location followed by loading from any location" was puzzling as it is not clear why this would not work. Even if we considered the addresses to alias and assumed no store-to-load forwarding, it seems reasonable that the store would finish before the subsequent load and that the load would return the correct value. If we go a step further and assume memory accesses take multiple cycles, there still does not appear to be a problem as this is a read-after-write dependency, and the writing happens before the read. Another explanation could be that memory accesses could occur at different points in the pipeline, such as both before and after the execution stage. If an add instruction required a read from memory and then writing back to memory, and that add instruction was followed by a load, that load would have to stall until the add instruction's write finished, resulting in an interlock. However, this explanation would not work if we assumed a PA-RISC architecture as the only memory operations allowed are explicit loads and store.
The third hazard of "loading from memory followed by using any register as the target of an arithmetic/logical instruction or a load/store with address modification" (verbatim from the paper) was even more confusing. This seemed to imply that the memory stage included the one and only arithmetic logic unit (ALU) in the processor as it specifically mentioned load/stores with address modification (which we took to imply adding an offset to a base address register). We did not like this explanation so we looked up many HP Precision Architecture designs. In particular, this architecture seemed to give a convincing explanation:

In this pipeline, it takes one cycle for the ALU to calculate address, then only in the next cycle is the ALU address result written to a register, and only in the cycle after that is the loaded data finally written to a register. Each stage is subdivided into two halves, where register writes can onyl happen in the first half and reads in the second. As such, an ALU operation cannot happen the cycle following a load/store address calculation since that value has not been written to a register yet, making an interlock necessary.
Perhaps improvements to pipeline designs in the three decades since this paper was published caused these mysteries, but all of this could be easily resolved if they had provided more information on exactly what kind of architecture they drew their hazards from. Their only reference was to [Kog81], which is a computer architecture textbook only available in print, and they cited the entire book without specific page numbers. We requested it from the Cornell Library Annex and combed through it, but it did not give any specific instruction set architecture designs.
Of these three hazards, the example they provided included two interlocks each for hazard types two and three. We would have preferred at least one of each type of interlock to have a more representative example. This paper also did not provide an example that would have utilized the carry/borrow dependency subgraph.
In terms of performance evaluation, they had a good analysis for the worst-case complexity, but their empirical results could have included more data. They mentioned numbers for the amount of interlocks mitigated, but they only talked about three benchmarks. The [Joh86] paper that they referenced for more information stated that "the range of improvement [for load/store scheduling] varied greatly with the program being optimized", which can be rationalized by assuming that the programs being tested had high variation in their instruction types. However, looking at the actual measurements, the percentage improvements were 54%, 19%, 4%, 1%, 0%, 0%,and 0% (one benchmark with no load/store interlocks was omitted). It seems strange that there is an insignificant improvement for more than half of the benchmarks tested, and I wish the authors gave an explanation for this in the original paper.
Even with these complaints, this paper did a number of things well. They did the requisite research for other literature in the pipelined instruction scheduling field and made fair and knowledgeable comparisons to other approaches. They also were clear in defining the subproblem they needed to solve and gave clear explanations of their approach in solving them with justifications for design decisions (e.g., not using a lookahead). Furthermore, they did not just give a heuristic and empirically argue that it works, but instead gave intuition behind the desired behaviors before diving into the actual algorithm. Lastly, the structure of this paper was also very streamlined in going from problem to solution to evaluation. Nowhere in the paper were we confused about why it was talking about something.
Overall, this paper offers a simple and efficient way of improving performance by reducing interlocks. While it may not be optimal on all architectures, its design goal was to perform well on most architectures while maintaining a low computational complexity, which they have successfully done.
Other Remarks
Modern high performance processors such as those manufactured by Intel and AMD use more complex pipelines and fancier hardware optimizations. Instructions are also broken down into micro-ops and the documentation for them is not always released by the company. This makes optimal instruction scheduling very hard on these modern processors. However, the algorithm proposed in this paper inspired a class of algorithm called list scheduling and they are used in modern compilers such as LLVM today.