Topics:
- Malleability and homomorphisms
- Nonrepudiation vs. authentication
- Public-Key Infrastructures
- Certificate Authorities
- How https works
- PEM
- PGP/web of trust
- Names
- Authentication logic
Malleability and homomorphisms
An encryption algorithm is malleable if it allows computation on ciphertext to produce meaningful results in the corresponding plaintext.
For example, suppose the attacker knows the RSA encryption of two messages a and b, which are ae and be (mod n), but does not know a and b themselves. In that case the attacker can compute the encryption of the product of the messages, which is just the product of the encryptions:
(ab)e = ae be
The reason this is possible is because RSA is a homomorphism with respect to the operation of multiplication. A homomorphism is a structure-preserving map between two algebraic structures (such as groups, rings, or vector spaces). The word homomorphism comes from the Greek language: homo meaning "same" and morphos meaning "shape". In general the operations in the two structures can be different operations, but in this case it is multiplication in the plaintext and the ciphertext that is preserved by encryption.
Homomorphisms mean you have to be careful. For example, the RSA homomorphism is why we should not digitally sign things directly, because an attacker can manipulate a digital signature into a signature of something else meaningful. However, if we sign a secure hash of a message, that is secure because the attacker cannot find a suitable hash for the desired forged message.
Homomorphisms also create opportunities as well. In this RSA example, we can see that it is possible to have another computer do multiplication for you with knowing what two numbers it is multiplying. If we had a cryptosystem that was a homomorphism with respect to two operations of the right sort (such as multiplication and addition), then we could ship arbitrary computations to an untrusted node. However, it is not know whether such a cryptosystem exists that is not insecure in other ways.
Nonrepudiation vs. authentication
Authentication is the process (and the security property) whereby a request or message is determined to come from some principal. The recipient of the message uses knowledge of the sender in order to decide how to handle the request, that is, how to do authorization.
A digital signature also provides authentication. But a digital signature gives more than authentication, because it proves the authorship of the message to anyone, not just to the recipient. A digitally signed message can be transferred any number of times without losing its ability to convince.
The security property provided by digital signatures is known as nonrepudiation. If A sends a signed message to B, then B can present that message to any third party and prove that someone with A's private key must have sent it. It becomes difficult for A to repudiate the message, except perhaps to try to convince the third party that the public key isn't really A's public key or that the corresponding private key has been stolen.
Public Key Certification Authorities
In public key cryptography, each principal has a public key (known to everyone) and a private key (kept secret.) However, you must have the right public key for a principal you want to communicate with. Therefore, a way is needed to find the public key for a principal, given the principal's name. Since both the public key and the name are public, the question is whether this binding has integrity.If you try to use a public key that isn't really the right one or that is no longer valid (perhaps because the private key has been stolen), you are going to be communicating with the wrong principal. You may wrongly authenticate messages as being from that principal, violating authentication and integrity, and you may encrypt messages to that principal using the wrong key, violating confidentiality.
A standard solution is to use a certificate authority (certification authority, CA) to look up the public key for a given named principal. In order to trust that this binding is correct, a CA signs the representation of the binding. The public key for the CA is well-known, and therefore interested parties can ascertain that the signature is valid.
Certification authorities are used constantly. For example, Verisign and Thawte are certification authorities that support the SSL protocol. When you access an https web site at company.com, the SSL protocol will request that you receive a corresponding public key. The public key must say that it is for company.com and this must be signed by a certification authority you trust. Otherwise your browser will complain. If someone is spoofing the web site, you will get a message that the domain name of the web site does not match the certificate. Unfortunately users don't pay enough attention to these warnings. And web sites often don't bother to pay the CAs to establish a valid certificate, so you will receive "self-signed certificates" from some web sites. These are largely useless for authentication purposes.
If the CA is compromised, there is obviously a big problem. The private key for the CA should therefore be kept in a very safe place. Fortunately, unlike the KDC for secret key cryptography, the CA does not need to be online all the time. The CA has two functions: certify bindings (i.e. certification) and store the certificates. Once created, the certificates can be stored anywhere. and can even be procured (once signed) from an untrusted source. That is the valid of digital signatures.
What happens if a principal's private key is compromised? (In fact, in some cases it may be to an individual's benefit to suggest that a private key was compromised.) Once a principal's private key is compromised, then all the certificates associated with that principal will cause the wrong public key to be used. A solution is to insist that certificates have expiration dates. This limits damage but doesn't completely eliminate it. (Note that the KDC could have dealt with this problem just by deleting the KDC entry. This problem is a direct consequence of not having the CA on-line all the time.)
We need a scheme to assert that a certificate that has not yet expired is no longer valid. A solution is to assign a unique serial number to each certificate and maintain a certificate revocation list (CRL). A certificate is of the form: {principal name, public key, serial number, expiration date}CA and a CRL is of the form {time of issue, revoked serial number, revoked serial number, . . .}CA. A certificate is considered invalid if the expiration date has expired or the serial number of the certificate appears on a recent CRL. It is tempting to use the time of the message to compare to the expiration date, but this is a bad idea. An attacker that knows a compromised private key can use whatever time needed when creating a message (e.g. send a message that was sent "yesterday"). It is also important to use the most current CRL possible.
Note that the existence of CRLs requires that the CA or some other source of CRLs be online. Without access to a recent CRL, there is no way to know whether to trust a given certificate. There are also some engineering tradeoffs that arise when using CRLs. For instance, if the expiration time is small (not too far in the future), then certificates will be constantly reissued and lots of traffic will be generated. Large expiration times lead to long CRLs. If CRLs are issued frequently, then the amount of time vulnerable to compromise is short but lots of network traffic is generated. If the CRLs are issued infrequently, then the possibility of compromise increases.
Public-Key Infrastructures
Having a single CA is unrealistic. There is no one entity that is trusted by everyone for everything (even in real life). Moreover, performance will not scale well. A solution is to have multiple CAs. The issue now becomes: how does a principal in one CA's domain get a public key for a principal in a different CA's domain? This service is provided by a public-key infrastructure (PKI).
Imagine there is a user A in the CIA domain. Call the certifying authority CA-CIA. Similarly, imagine there is a user B in the KGB domain and CA-KGB is the CA. How can A communicate with B? A needs to know how to determine that a certification encrypted under CA-KGB's private key is valid. Thus A needs the public key of CA-KGB. A receives {CA-KGB, PCA-KGB}CA-CIA from CA-CIA. It then receives {B, PB}CA-KGB from CA-KGB. If A trusts both CA-CIA and CA-KGB then A must conclude that PB is B's public key.
But what should lead Alice to believe that she can trust CA-KGB? One solution is to have an agreed-upon mapping from principal names to the name of the CA that is considered an authority on those names. For example, one might go to the "cs" CA for names like myers/cs and go to the "cornell" CA for names like cs/cornell, etc. See the figure below for an example of this hierarchy.
PEM -- Privacy Enhanced Mail
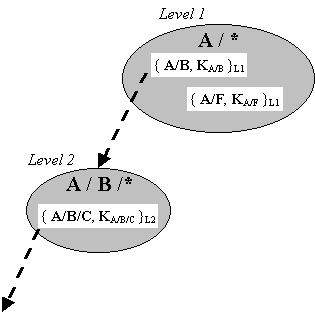
Privacy Enhanced Mail (PEM) is an example of a public key infrastructure. Details can be found in RFCs 1421, 1422, 1423, and 1424. PEM ties CAs to the structure of the principal's name. There are two versions of PEM.In the first version, names are hierarchical (e.g. A/B/C/D). An e-mail address such as myers@cs.cornell.edu is represented as edu/cornell/cs/myers. In such a scheme, it easy to add a new name uniquely. The PEM proposal is to have a CA for each subtree of the namespace. That is, a CA named A/B/C is responsible for all names of the from A/B/C/* (where * is a wildcard.) A CA named A/B is responsible for all names of the form A/B/*. A rule for certificates is that the issuer of a certificate must be a prefix of the principal's name in the certificate. That is, CA A/B can issue a certificate for A/B/C/D. Consider the following scenario
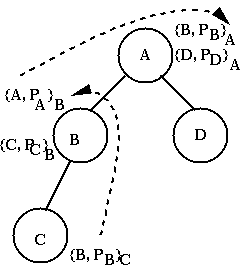
A can sign the public key of B, while B can certify the public key of A and of C. To check the public key of A/B/C/D, a user would in general check a chain signatures starting from A and working down to D.
A problem with the above scheme is that the CA at the root is too trusted. Compromising A's private key in the above example would compromise everything below A. A new scheme was therefore proposed. The root is the Internet Policy Registration Authority (IPRA) and there are three classes of PCAs (Policy Certificate Authorities) below the IPRA. The PCAs sign things. The rule is that there is only one path in the hierarchy to any principal. It is easy to find the path, and therefore easy to acquire the necessary certificates. There are three classes of PCAs:
- High assurance -- Super secure with strict tests before issuing certificates to check identity. The same rules apply to all the CAs below the high assurance PCA in the subtree.
- Discretionary assurance -- Well-managed at the top level, but no rules are imposed on organizations that are certified below the top level.
- No assurance -- No statement can be made about the authority of this PCA.
Pretty Good Privacy (PGP)
Pretty Good Privacy (PGP) provides another example of a public key infrastructure. PGP takes a different view of certification from PEM and does not use a tree-like structure. There are certificates in PGP, but each user is responsible for maintaining their own set of public keys on a key ring. Users decide for themselves who to trust. How are the public keys acquired? Keys can be sent signed by someone already trusted by the user. Keys are initially acquired in person. A chain of certificates is trusted if the user trusts every link in the chain, that is, believes that the signer gave the correct association of name and public key at every link.PGP asks each user to assign a "trust rating" to each public key that is on the user's public key ring. There are two parameters: valid -- the user believes that the key is associated with whom the user was told it is associated with, and trust -- a measure of how much the user trusts the principal as a signer. The trust parameter is three-valued: none, partial, and complete. If a certificate is signed by a principal the user completely trusts, then that key is valid. If a certificate is signed by two partially trusted users, then again the key is valid. Clearly, it is possible to devise very intricate trust management/key validity schemes. This area is not well-understood at this time. What are good properties for inferring trust? Should trust necessarily be transitive? Should trust be monotonic (once trusted, always trusted)?
Keys are generated in PGP as follows: 1.) the user specifies the size of the key (in bits) and then 2.) the user types a pass phrase. This pass phrase is then run through an MD5 cryptographic hash to obtain an IDEA key. The "private key" of the user is computed from the random timing in some typing that the user does. The private key is then encrypted locally with the IDEA key that was generated. Note: having the private key always encrypted implies that if the computer was stolen, the private key is still secure.
Naming
Public-key infrastructures manage the binding between two different kinds of names for a principal. It is useful to consider the properties of names in isolation. People tend to make common mistakes with naming when building systems.Definition
A name is an abstraction that allows us to designate an entity without details. Naming an object permits us to refer to that object without having to describe its properties.
Naming is not absolutely necessary; we could live in a world without naming by using descriptions to refer to objects, but these descriptions can take time and space. For example, to fully describe the password file in a Unix system, we would need to list every user and password in the file! In this case, a file name provides a much more useful and terse way to refer to the file. Like other abstractions, names simplify thinking about things.
Properties
Naming should possess the following properties:
- The use of one name does not prevent other names from being used. For example, naming a file in the current directory shouldn't prevent you from naming a file in some other directory.
- If an object does not have a name, then it is not accessible. A name is the only way to denote an object.
- Singular objects do not require names. As an example, in uniprocessor machines, the single processor was unnamed and referred to implicitly. However, in multiprocessor or networked systems, each processor should have its own name.
Purposes
We can achieve several things by using names:- Sharing
Different entities can share an object through its name. If there are two or more processes accessing the same object, they can set up names and use them to denote the object. In this case, each entity could use a different name for the same object. - Secrecy
Naming can provide secrecy. In a large name space, usually only a small fraction of possible names are used. Moreover, it is not obvious what this fraction will be. An entity that knows a certain name possesses knowledge that may not otherwise be available. For example, computer passwords are typically chosen from a large set of unguessable character sequences, and provide a mechanism for secrecy. Binding of names in programming languages also provide secrecy. - Capabilities When names are secret, knowledge of the name can then convey power over the thing that is named. When a name gives power to manipulate the named thing, it is called a capability. For example, a public key allows identification of a principal, which can be shared with everyone. But a public key gives no ability to control the principal. Holding the private key of a principal gives power over the principal. For example, one can then cause messages to be sent on behalf of the principal, effectively causing the principal to take actions in a system. Thus, a private key is an example of a capability.
Concerns
We now look at some issues regarding naming.- Scalability
It is generally a bad idea in system design to assume that only a small number of names will ever be needed. Such an assumption is inherent in a fixed name size.
For naming to be scalable, we need the following:- variable length names: The name space is potentially infinite.
- unique names: The same name cannot be used to refer to two different objects. Duplicate names would preclude controlled sharing and secrecy. Verifying the uniqueness of a new name can be done by comparison against existing names and takes linear time.
- no single central authority to produce names: At best, a single authority becomes a performance bottleneck, and at worst it is a single point of failure. Multiple entities should be able to check a name against existing names for uniqueness.
- a manageable cost to produce new names: A distributed linear algorithm is usually not good enough.
- Hierarchical naming
One possible solution to the above performance problem is hierarchical naming. In hierarchical naming, we can denote names in the format: a/b/c/d/e/... Many names are actually of this type. For example, the phone number +1(607)255-9221 can be mapped to +1/607/255/9221, and the internet addressfbs@cs.cornell.edu to edu/cornell/cs/fbs. A name without hierarchy is just a.Hierarchical names have the following implementation advantages:
- indefinite growth in both directions: For example, we can add either area codes or extensions to expand phone numbers.
- distributed authority to create names: For example, one authority would be in charge of names beginning with a/b/c, while another would be in charge of names beginning with a/b/d. As long as each authority maintains the uniqueness of names within its assigned sub-domain, we will have global uniqueness of names.
- Name information
Typically, we need more information about an object than only its name. There are two ways to do this:- names accompanied by hints: We must be able to access hints for a given name, and, if the hints are stale, we must be able to correct them.
- impure names: A name is pure if there is no content in the name. An impure name contains attributes of the object it names. Intuitively, impure names are great, since we can easily extract necessary information from the name itself. On the other hand, impure names have a built-in consistency problem; when the information is no longer correct, the name must change. A mechanism is required for changing names. For example, a .forward file is used to handle email addresses that are no longer valid.