Last time we started talking about GPU computing.
This time we'll go into more detail!
Modern NVIDIA GPU structure¶
GPU chip connected via high-bandwidth interconnect to memory (HBM = high-bandwidth memory)
GPU is made up of Streaming Multiprocessors (SMs)
- These are analogous to the cores of a CPU => essentially independent parallel units
- Unlike a CPU, which can run (keep state resident) only one thread at a time (or two with hyperthreading) each SM can have many resident threads
- e.g. 2048 resident threads per multiprocessor on compute capability 9 (H100)
Threads are organized in two different ways: one from the perspective of the hardware and one from the perspective of the software
From the software perspective, threads are organized into blocks and blocks are organized into a grid
- Multiple threads in the same block are guaranteed to run on the same SM
- Multiple threads in the same block can communicate with each other efficiently via shared memory, a fast memory space within an SM that's shared among the threads in a block
- Number of threads in a block limited to 1024
- A grid is a collection of blocks, and distributes work across the SMs

From the hardware perspective, threads are organized into warps
- A warp is 32 threads
- Warps share execution resources, (usually) all execute the same instruction at once
- In many situations a warp behaves like a big SIMD unit
- Warp divergence (threads in a warp executing different instructions) is allowed in software, but expensive!
- Avoid if possible
- Threads in a warp can communicate among each other using special warp shuffle instructions; usually faster than shared memory
Important property of warps: coalesced memory accesses
- Typical case: All the threads of a warp access HBM (global memory) at the same time at adjacent locations
- Hardware combines ("coalesces") all 32 accesses into one memory access
- This is the only way to read memory at full bandwidth!
Warps are organized into a warpgroup
- A warpgroup is 4 warps (128 threads)
- Asynchronous tensorcore instructions are called at the level of a warpgroup
TensorCores accelerate matrix multiply
- Good way to think about it is as a $(16, 16) \times (16, 16) \rightarrow (16,16)$ matrix multiply.
- You can go smaller in some cases but usually don't.
- Good way to think about it is as a $(16, 16) \times (16, 16) \rightarrow (16,16)$ matrix multiply.
TensorCore operations are warp-level or asynchronous warpgroup-level
- Warp-level means that all the threads of the warp need to participate in the instruction!
- The inputs are shared among the threads
- E.g. let's say that we are doing a $16 \times 16 \times 16$ matrix multiply on a single warp in float16. How many 32-bit registers will each thread have as inputs? How many will each thread have as outputs?
- Asynchronous warpgroup-level means that all the threads of a warpgroup need to participate in the instruction, but the result arrives asynchronously
- TensorCores represent most of the FLOPS capability of the GPU.
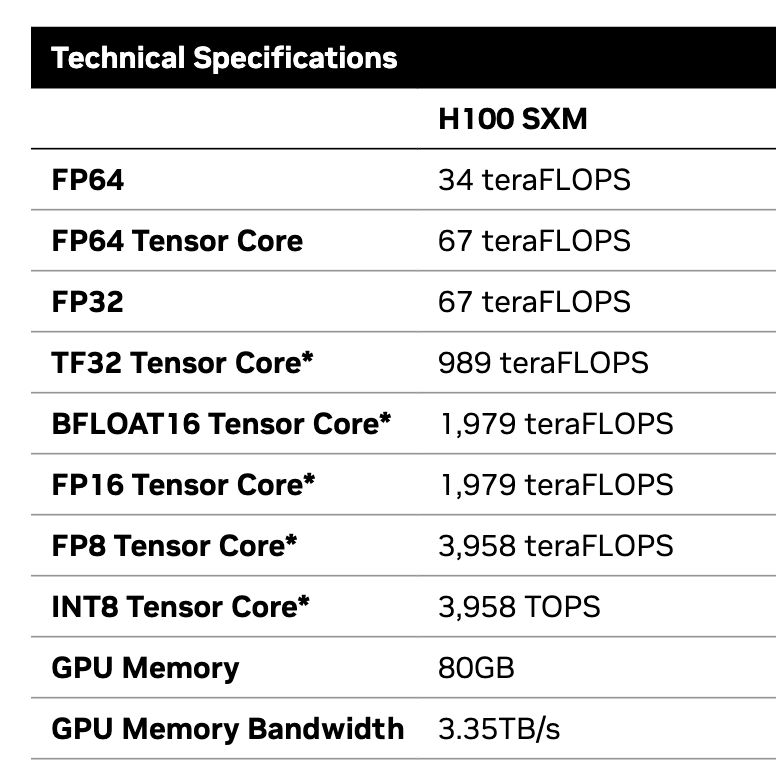
3958/67
59.07462686567164
Multiple GPUs in a rack are connected together via NVLink
NVLink lets GPUs communicate with each other fast and access each others' memory directly!
- Gives us a shared-memory model for distributed learning over multiple GPUs