Over the past three lectures, we've been talking about the architecture of the CPU and how it affects performance of machine learning models.
However, the CPU is not the only type of hardware that machine learning models are trained or run on.
In fact, most modern DNN training happens not on CPUs but on GPUs.

- In this lecture, we'll look at why GPUs became dominant for machine learning training, and we'll explore what makes their architecture uniquely well-suited to large-scale numerical computation.

- Right now, GPUs are dominant for ML training...we'll get to why later

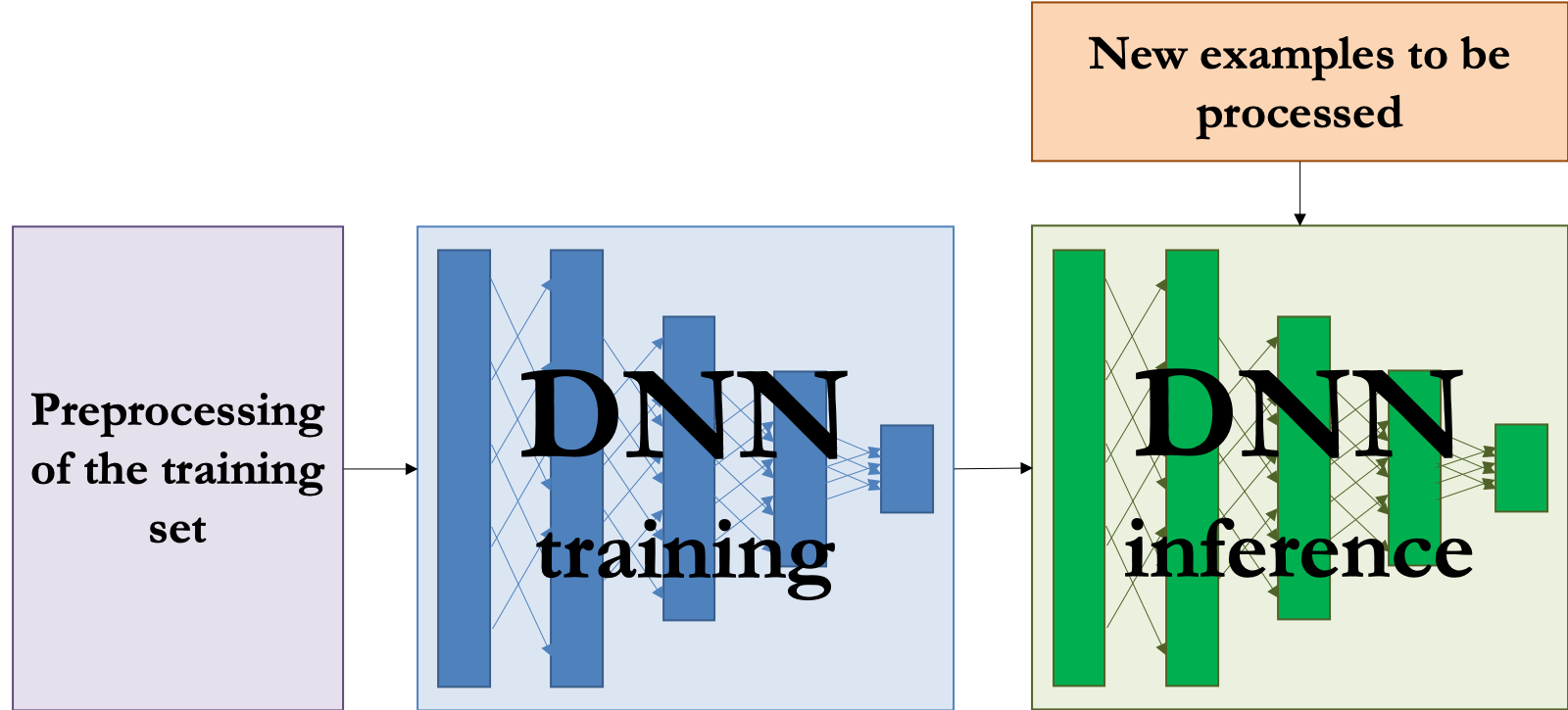
Where can hardware help?¶
Everywhere!
There’s interest in using hardware everywhere in the pipeline
- both adapting existing hardware architectures, and
- developing new ones
What improvements can we get?
- Lower latency inference
- To be able to make real-time predictions
- Higher throughput training
- To be able to train on larger datasets to produce more accurate models
- Lower power cost
- Especially important as data and model sizes scale
How can hardware help?¶
Speed up the basic building blocks of machine learning computation
- Major building block: matrix-matrix multiply
- Another major building block: convolution
Add data/memory paths specialized to machine learning workloads
- Example: having a local cache to store network weights
- Create application-specific functional units
- Not for general ML, but for a specific domain or application
Why are GPUs so popular for machine learning?¶
Why are GPUs so popular for training deep neural networks?¶
To answer this...we need to look at what GPU architectures look like.
A brief history of GPU computing.¶
GPUs were originally designed to support the 3D graphics pipeline, much of which was driven for demand for videogames with ever-increasing graphical fidelity.

Important properties of 3d graphics rendering:
- Lots of opportunities for parallelism
- rendering different pixels/objects in the scene can be done simultaneously.
- Lots of numerical computations
- 3d rendering is based on geometry.
- Mostly polygons in space which are transformed, animated, and shaded.
- All of this is numerical computation: mostly linear algebra.
GPU computing (continued)¶
The first era of GPUs ran a fixed-function graphics pipeline. They weren't programmed, but instead just configured to use a set of fixed functions designed for specific graphics tasks: mostly drawing and shading polygons in 3d space.
In the early 2000s, there was a shift towards programmable GPUs.
Programmable GPUs allowed for people to customize certain stages in the graphics pipeline by writing small programs called shaders which let developers process the vertices and pixels of the polygons they wanted to render in custom ways.
These shaders were capable of very high-throughput parallel processing
- So that they could process and render very large numbers of polygons in a single frame of a 3d animation.
- Intuition: if I am rendering multiple independent objects in a scene, I can process them in parallel.
- And there was powerful economic incentive for hardware designers to increase the throughput of these GPUs so that game designers could render models with more polygons and higher resolution.
GPU computing (continued)¶
The GPU supported parallel programs that were more parallel than those of the CPU.
But unlike multithreaded CPUs, which supported computing different functions at the same time, the GPU focused on computing the same function simultaneously on multiple elements of data.
- Example application: want to render a large number of triangles, each of which is lit by the same light sources.
- Example application: want to transform all the objects in the scene based on the motion of the player character (which controls the camera). That is, the GPU could run the same function on a bunch of triangles in parallel, but couldn't easily compute a different function for each triangle.
GPU computing (continued)¶
This illustrates a distinction between two types of parallelism:
- Data parallelism involves the same operations being computed in parallel on many different data elements.
- Task parallelism involves different operations being computed in parallel (on either the same data or different data).
How are the different types of parallelism we've discussed categorized according to this distinction?
- SIMD/Vector parallelism?
- Multi-core/multi-thread parallelism?
- Distributed computing?
The general-purpose GPU¶
Eventually, people started to use GPUs for tasks other than graphics rendering.
However, working within the structure of the graphics pipeline of the GPU placed limits on this.
To better support general-purpose GPU programming, in 2007 NVIDIA released CUDA, a parallel programming language/computing platform for general-purpose computation on the GPU.
- Other companies such as Intel and AMD have competing products as well.
Now, programmers no longer needed to use the 3d graphics API to access the parallel computing capabilities of the GPU.
This led to a revolution in GPU computing, with several major applications, including:
- Deep neural networks (particularly training)
- Cryptocurrencies
A function executed on the GPU in a CUDA program is called a kernel.
An illustration of this from the CUDA C programming guide:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
This syntax launches $N$ threads, each of which performs a single addition.
The general-purpose GPU (continued)¶
Importantly, spinning up hundreds or thousands of threads like this could be reasonably fast on a GPU, while on a CPU this would be way too slow due to the overhead of creating new threads.
Additionally, GPUs support many many more parallel threads running than a CPU.
- Typical thread count for a GPU: tens of thousands.
- Typical thread count for a CPU: at most a few dozen. Important downside of GPU threads of this type: they're data-parallel only.
- You can't direct each of the individual threads to "do its own thing" or run its own independent computation (although GPUs do support multi-task parallelism to a limited extent).
- Importantly: more modern GPUs now support some level of task-parallelism.
- Threads are bound together into "warps" (of ~32 threads) that all execute the same instruction.
- But threads in different warps have limited ability to run independently.
GPUs vs CPUs¶
CPU is a general purpose processor
- Modern CPUs spend most of their area on deep caches
- This makes the CPU a great choice for applications with random or non-uniform memory accesses
GPU is optimized for
- more compute intensive workloads
- streaming memory models
Machine learning workloads are compute intensive and often involve streaming data flows.
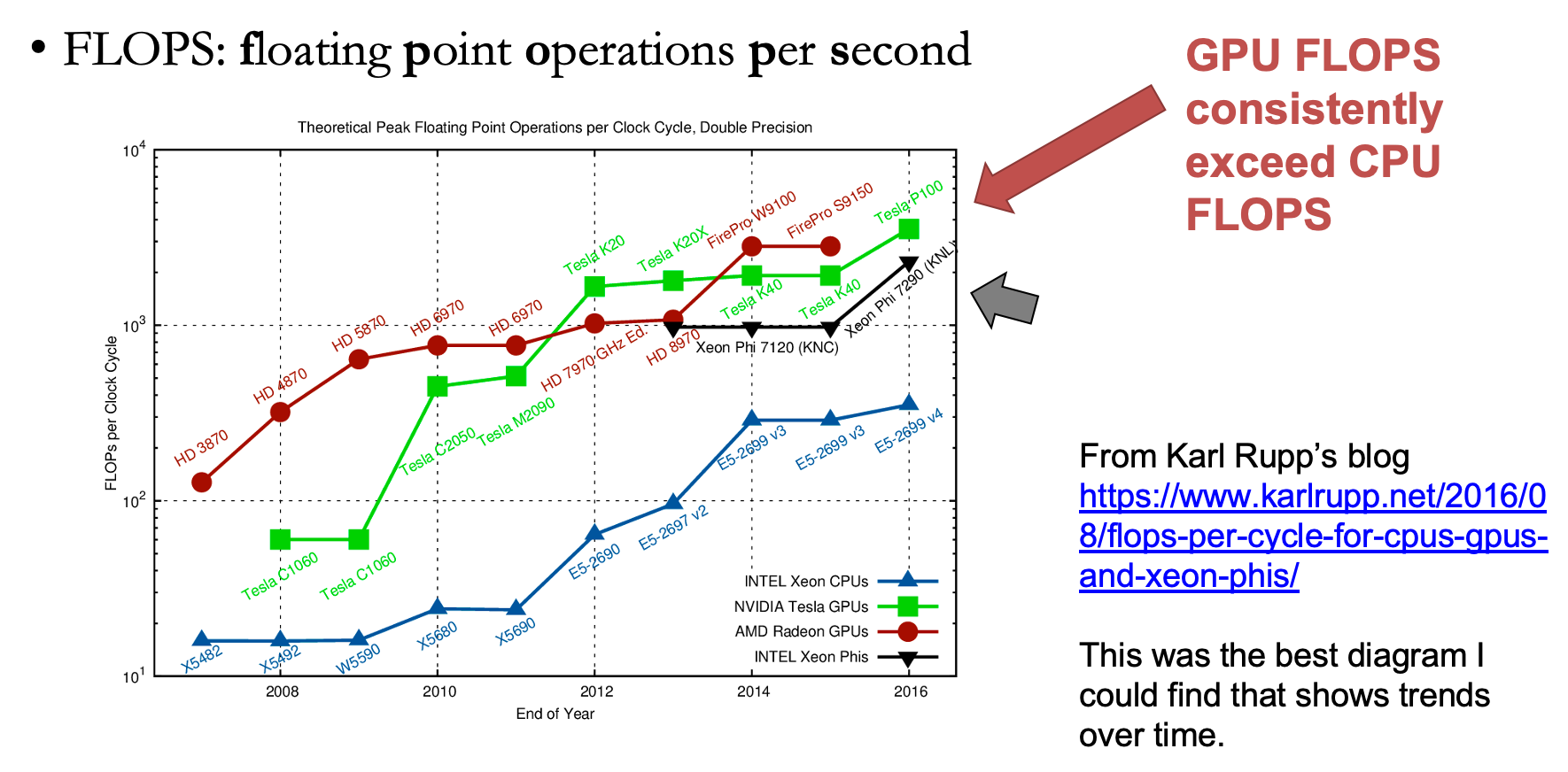
FLOPS: GPU vs CPU¶
Memory Bandwidth: GPU vs CPU¶
- GPUs have higher memory bandwidths than CPUs
- NVIDIA A100 80GB GPU has 2 TB/s memory bandwidth
- Whereas an Intel Xeon Platinum CPU has only about 120 GB/s memory bandwidth at about the same time
- But, this comparison is unfair!
- GPU memory bandwidth is the bandwidth to GPU memory
- e.g. on a PCIE2, bandwidth is only 32 GB/s for a GPU
What limits deep learning?¶
Is it compute bound or memory bound?
- i.e. is it more limited by the computational capabilities or memory capabilities of the hardware?
Ideally: it's compute bound
- Why? Matrix-matrix multiply over $\R^{n \times n}$ takes $O(n^2)$ memory but $O(n^3)$ compute
But often it is memory/communication bound
- When we are doing convolutions with small filter sizes, compute becomes less dominant
- Especially when we are running at large scale on a cluster
- Especially when data/models do not fit in caches on the hardware
So we have to consider both in ML systems!
GPUs in machine learning.¶
Because of their large amount of data parallelism, GPUs provide an ideal substrate for large-scale numerical computation.
In particular, GPUs can perform matrix multiplies very fast.
Just like BLAS on the CPU, there's an optimized library from NVIDIA "cuBLAS" that does matrix multiples efficiently on their GPUs.
There's even a specialized library of primitives designed for deep learning: cuDNN.
Machine learning frameworks, such as TensorFlow, are designed to support computation on GPUs.
And training a deep net on a GPU can decrease training time by an order of magnitude.
How do machine learning frameworks support GPU computing?
Machine Learning Frameworks and GPUs¶
A core feature of ML frameworks is GPU support.
High-level approach:
Represent the computational graph in terms of vectorized linear-algebra operations.
For each operation, call a hand-optimized kernel that computes that op on the GPU.
- i.e. matrix-matrix multiply
- i.e. convolution for a CNN
- when GPU code is not available for a function, run it on the CPU
- but this happens rarely
Stitch those ops together by calling them from Python
- and eventually make the results available back on the CPU
Challengers to the GPU¶
More compute-intensive CPUs
- Like Intel’s Phi line — promise same level of compute performance and better handling of sparsity
Low-power devices
- Like mobile-device-targeted chips
Configurable hardware like FPGAs and CGRAs
Accelerators that speed up matrix-matrix multiply
- Like Google's Version 1 TPU
Accelerators special-designed to accelerate ML computations beyond just matrix-matrix multiply
- Version 2/3 TPUs
- Many competitors in this space