Optimization: Bisection, steepest descent minimization, Newton Raphson, and conjugate gradient.
There are many examples in which we search for an optimum of a function. Sometimes this optimum is readily available using analytical consideration. In other cases we need to implement and/or to use appropriate numerical algorithms to solve the optimization problem. Here we consider minimization algorithms in continuous space.
Let us start by a simple optimization problem that has an analytical solution (in fact we already considered one example with an analytical solution, the problem of optimal rotation. However, it is probably incorrect to classify that problem as �simple�):
Suppose that an experiment was made that measures
observations ![]() as a function of time
as a function of time ![]() . We wish to fit the set of points to a straight line
. We wish to fit the set of points to a straight line ![]() , the
, the ![]() �and
�and ![]() �are unknown
parameters to be determined. The straight line (in contrast to the spline
formulation) does not necessarily pass through all the points. Experimental
data may include errors or noise that can cause deviations from a straight
line. Of course, it is also not obvious that the straight line is indeed the
correct functional form to represent the data. Nevertheless, here we are going
to assume that it is correct.
�are unknown
parameters to be determined. The straight line (in contrast to the spline
formulation) does not necessarily pass through all the points. Experimental
data may include errors or noise that can cause deviations from a straight
line. Of course, it is also not obvious that the straight line is indeed the
correct functional form to represent the data. Nevertheless, here we are going
to assume that it is correct.
One way of determining the parameters ![]() �and
�and ![]() �is to optimize a
function that will minimize the difference between the straight line and the
experimental points:
�is to optimize a
function that will minimize the difference between the straight line and the
experimental points:
![]() ��������������������������������������������� (1)
��������������������������������������������� (1)
Requiring that the first derivatives are equal to zero we have
![]() �������������� �����(2)
�������������� �����(2)
Define the average over ![]() �points as
�points as ![]() �we have
�we have
![]() ����������������������������������������� (3)
����������������������������������������� (3)
and also
![]() ������������������������������������� �����������(4)
������������������������������������� �����������(4)
Multiplying the last equation by ![]() �and subtracting the
result from equation (3) we have:
�and subtracting the
result from equation (3) we have:
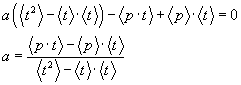 ���������������������������������� (5)
���������������������������������� (5)
and
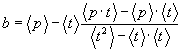 ��������������������������
��������������������(6)
��������������������������
��������������������(6)
This is an important result that is useful in numerous
functional fits. It can also be generalized to non-linear functional forms. The
unique feature of the above is the analytical solution. In reality an
analytical solution is quite rare. What are we going to do when the analytical
solution is not obvious? (e.g. we cannot determine ![]() �and
�and ![]() �in a closed form)
This can happen even in remarkably simple cases like
�in a closed form)
This can happen even in remarkably simple cases like ![]() . Where is the minimum of this one-dimensional function? So
here comes our first technique of bi-section, designed as the simplest possible
choice of finding a stationary point for a one-dimensional function. It is
simple but nevertheless effective. Since the computational efforts in such
optimization are not large, simplicity is a good thing. Programming complex and
elaborate algorithms is not always an advantage.
. Where is the minimum of this one-dimensional function? So
here comes our first technique of bi-section, designed as the simplest possible
choice of finding a stationary point for a one-dimensional function. It is
simple but nevertheless effective. Since the computational efforts in such
optimization are not large, simplicity is a good thing. Programming complex and
elaborate algorithms is not always an advantage.
We consider a function of one variable ![]() �defined in an interval
�defined in an interval
![]() �such that
�such that ![]()
The function and its first derivative are assumed
continuous. The product above implies that somewhere in the interval, there is
a stationary point 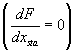 , searching for it:
, searching for it:
- Compute
a middle point
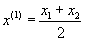
- Compute
the gradient of the function at that point -
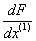
- If the
gradient is zero, return
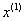 �and stop
�and stop - Compute
the products:
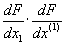 �if negative a
stationary point is at the interval
�if negative a
stationary point is at the interval 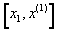 , if positive a stationary point is at
, if positive a stationary point is at 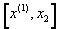
- Redefine
the interval as the half-interval that contains a stationary point (either
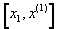 �or
�or  )
) - If the
length of the new interval is smaller than (given length)
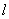 , return
, return 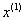 �and stop
�and stop - Return to step 1
Note that we made a number of strong assumptions. We assume that the interval indeed includes the point that we want. We also assumed that the first derivative is available to us and that it is continuous. Finally we checked for a stationary point and not for a minimum.
- Suggest a way of modifying the above algorithm, checking for a minimum.
It is useful to have a bi-section technique that does not
employ derivatives. Algorithm to find the minimum in an interval ![]() �that includes only
one minimum is
�that includes only
one minimum is
- Find
a middle point

- Compute

- Use
 �and the
function values
�and the
function values  �to construct a
parabolic approximation to the function:
�to construct a
parabolic approximation to the function: 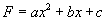 . Keep the coordinate and value of the function with
the lowest value found so far
. Keep the coordinate and value of the function with
the lowest value found so far - Find
the minimum of the parabola in step 3 -

- From the set of sampled points find the lowest minimum (so far) and the two points that are closest to it.
- Check
the distance from the point with lowest function value to its neighboring
points. If smaller than threshold,�
return
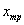 �and stop.
�and stop. - Substitute
 �and its two
neighbors into
�and its two
neighbors into 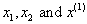
- Go to step 3.
o
Suppose we do not have an interval that includes the
desired point, but do have the gradient of the function. Given a starting point
![]() , how would you perform the search?
, how would you perform the search?
Searches in one dimension are easy and there are many ways
of doing these searches efficiently. Life is more interesting in more than one
dimension. It is not obvious at all where to put the next point even if we
bound the function in a box (in two dimension -- ![]() ).
).
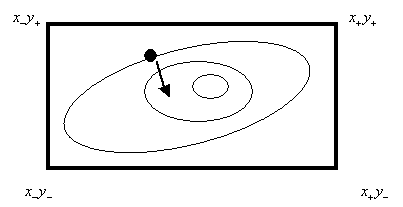
�A common trick is to
translate the multidimensional search into a sequence of searches in one
dimension. Here we emphasize local searches. That is, given a current
approximation to the position of the minimum ![]() , suggests a new coordinate that better approximates the
location of the minimum. For that purpose having the gradient of the function
is very useful
, suggests a new coordinate that better approximates the
location of the minimum. For that purpose having the gradient of the function
is very useful ![]() .
.
![]() �is a vector that
points into the direction of the maximal change of the function. For example, if
we are making a small displacement (in two dimension)
�is a vector that
points into the direction of the maximal change of the function. For example, if
we are making a small displacement (in two dimension) ![]() , such that
, such that ![]() , then the displacement was made along an equi-potential line
(no change in the value of the function). It is therefore clear that maximal
changes in the function can be obtained if the displacement is parallel (or
anti-parallel) to the gradient of the function. Since we want to reduce the
value of the function (in order to find a minimum) the best direction we can
pick for a step based on local consideration is along
, then the displacement was made along an equi-potential line
(no change in the value of the function). It is therefore clear that maximal
changes in the function can be obtained if the displacement is parallel (or
anti-parallel) to the gradient of the function. Since we want to reduce the
value of the function (in order to find a minimum) the best direction we can
pick for a step based on local consideration is along ![]() . Of course, as we make a finite displacement the value and
the direction of the gradient may change. Our search is therefore valid only if
a very small (infinitesimal) step is taken, the gradient is re-computed at the
newly generated position and a small step is taken again. One can translate
this procedure into a differential equation with a dummy variable
. Of course, as we make a finite displacement the value and
the direction of the gradient may change. Our search is therefore valid only if
a very small (infinitesimal) step is taken, the gradient is re-computed at the
newly generated position and a small step is taken again. One can translate
this procedure into a differential equation with a dummy variable ![]() �(we are not really
interested in
�(we are not really
interested in ![]() �but rather in the
asymptotic value of the function for large
�but rather in the
asymptotic value of the function for large ![]() -s).
-s).
The above pictorial scheme is captured in the equation:
![]() ����������������������������������������������������������� (7)
����������������������������������������������������������� (7)
with the initial conditions ![]()
- Show
that
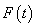 �is a
monotonically decreasing function
�is a
monotonically decreasing function - Suggests a convergence criterion for optimization using equation (7)
- Usually the calculations of the function gradient are expensive. Is equation (7) an efficient minimizer?