Pseudo-Random Numbers
The numbers we produced on a digital computer are not truly random since a deterministic algorithm created them and the results are reproducible exactly. They are typically used to present sampling from known distribution. The most famous one is a uniform distribution between zero and one.
![]()
The pseudo random numbers that we generate on the computer attempt to represent sampling from the above distribution. We expect that a large sample (say N) of pseudo-random numbers from the above distribution could be histogrammed and yield a uniform distribution.
So the creation of the desired distribution by sampling and
histogramming is one criterion by which pseudo-random numbers are judged.
Random numbers can also be tested by measures of correlations. For example,
consider a sequence of random numbers ![]() that was generated by
repeated calls to the computer random-number-generator. The average over all
that was generated by
repeated calls to the computer random-number-generator. The average over all ![]() s, of
s, of ![]() should be zero for
every choice of
should be zero for
every choice of ![]() since “true” random
numbers are not correlated. Same thing is true also for higher order
correlations, e.g.
since “true” random
numbers are not correlated. Same thing is true also for higher order
correlations, e.g. ![]() . The correlation test is a true killer and essentially all
the algorithms to create pseudo-random numbers fail to these tests, sooner or
later.
. The correlation test is a true killer and essentially all
the algorithms to create pseudo-random numbers fail to these tests, sooner or
later.
Besides passing quality tests, we want to generate these numbers very quickly. The algorithms that do usually try the following:
![]()
m is the largest integer that can be presented on the
computer (e.g. ![]() ), a is an (odd) multiplicative factor and b is
a relatively prime with respect to m (b and m have no
common factor). Example: a=2,147,437,301 ; b=453,816,981 ;
), a is an (odd) multiplicative factor and b is
a relatively prime with respect to m (b and m have no
common factor). Example: a=2,147,437,301 ; b=453,816,981 ; ![]() .
.
The numbers produced by ![]() are uniformly
distributed between zero and one. They are correlated however, in the same
manner that we discussed earlier. To remove the correlation it is possible (for
example) to store the random numbers in a long array and then to shuffle the
elements of the array (at random…).
are uniformly
distributed between zero and one. They are correlated however, in the same
manner that we discussed earlier. To remove the correlation it is possible (for
example) to store the random numbers in a long array and then to shuffle the
elements of the array (at random…).
The above scheme to generate uniformly distributed random numbers is usually available at the level of the operating system. The calculation is however limited to the uniform distribution between zero and one. How can we generate other distributions?
- For example, how to generate a uniform distribution between –2 and +2 using computer generated pseudo random numbers between zero and one?
The above conversion is easy. Let us consider a more interesting example. Use uniformly distributed number to create a probability density of the type
![]() between
between ![]()
To generate that distribution we define first the distribution function:
![]()
If I now take ![]() variables that are
uniformly distributed and for each sample
variables that are
uniformly distributed and for each sample ![]() I compute
I compute ![]() then
then ![]() is distributed according to
is distributed according to ![]() . For the above distribution we have
. For the above distribution we have 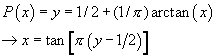
So the procedure is
- Sample
uniform
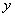 between 0 and 1
between 0 and 1 - Compute
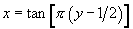
· Another
famous trick is to use the central limit theorem to generate Gaussian random
numbers (i.e. 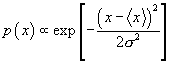 )
)