The kinds of semantics we have looked at are operational semantics: descriptions of how to evaluate programs (there are other kinds of semantics, such axiomatic semantics, which tell you how to prove statements about programs). There is even more than one way to specify an operational semantics for a given programming language. We have been exploring a particular operational model of evaluation called the substitution model. The key idea of the substitution model is that when a variable is bound to a value (by pattern-matching), the value is substituted in place of all occurrences of the variable that are bound by the pattern in question.
In a functional language, we can think of the execution of the program as a series of rewrite steps applied to the program text. This is also how we usually think about the evaluation of an arithmetic expression. For example, if we see the expression (2+3)*4+3*4, we know that it evaluates in four steps:
(2+3)*4+3*4 -> 5*4+3*4 -> 20+3*4 -> 20+12 -> 32
In each step, we take some part of the expression and replace it with a new expression. For example, in the first step we replace 2+3 with 5. Thus, each rewrite step acts locally to replace a subexpression with its value. These local rewritings are called reductions.
Sometime there are several rewrite steps we can choose for a given expression; these different choice lead to different evaluation orders. There are actually several possible evaluation orders for this expression; for example, here is a different one:
(2+3)*4+3*4 -> (2+3)*4+12 -> 5*4+12 -> 20+12 -> 32
It doesn't matter what order we evaluate things in; we always get the same result regardless. This will also be true for SML as long as we stick to functional language features (that is, stay away from imperative features such as refs, arrays, :=, etc.) One benefit of functional programming is precisely that the result of evaluating an expression is always the same; it does not depend on the order of evaluation and it is always the same no matter how many times it is evaluated.
Here are some examples of simple SML evaluations:
#2(2+3*4, false) -> #2(2+12, false) -> #2(14, false) -> false false::(false orelse true)::nil -> false::true::nil
These evaluations use various reductions that are part of SML. For example,
there are lots of arithmetic reductions of the form v1 op
v2->v3, In addition there are
reductions on tuples; as seen in the first example, we have a reduction
#i(v1,...,vn) -> vi (where 1 <= i <= n)
Every SML expression form has its own reductions. For example, the if..then..else
expression has two reductions that capture the essential computational behavior
of the expression:
if true then e1 else e2 -> e1 if false then e1 else e2 -> e2
When does the program stop? In arithmetic, it's when we reach a number, because there are no further steps to take. In general, we have some set of expressions in the programming language that can't be evaluated any further; we call these expressions values. Values are things that you can type at the SML prompt and get the same thing right back. For example, in SML, the following are values:
1 true "hello" (true, "5", 1) fn(x:int) => x 5::4::nil (=[5,4])
The following expressions are not values, because an evaluation step can be performed on them:
1+2
true orelse false
(true, "5", 0+1)
(fn(x:int) => x) (3)
We can write a BNF grammar for values v, just as
we did earlier for expressions:
c ::= integer_const
| bool_const
| string_const
| real_const
| char_const
v ::= c (* constants *) | (v1,...,vn) (* tuples of values *) | (fn (id:t):t' => e) (* anonymous functions *) | {id1=v1, ..., idn=vn} (* records of values *) | Id | Id(v) (* data constructors *)
Anything described by this grammar is a value and thus a legal result of an SML program. In other words, any tuple whose elements are values is a value itself; any records whose fields are bound to values is a value, any data constructor applied to a value is also a value, and any anonymous function is a value�even if its body is an arbitrary expression e. In other words, the body of a function is not evaluated at all until it is applied to an argument.
How do we know that a program will always reach a value? Actually, we don't.
A program might go into an infinite loop. But no matter how long the program
executes, as long as it hasn't reached a value there will always be a reduction
to perform. For example, we'll never have to apply a reduction to #i(v1,...,vn)
where i > n. The SML type checker ensures that
this and other bad things will never happen. This is what it means to say that
SML is type-safe.
Of course, SML is quite a bit more complicated than 3rd-grade arithmetic. The
biggest difference is that in SML expressions can contain variables: names
that are bound to values. In the substitution model we handle variables
by substituting for them using the values to which they are bound. For
example, the expression let val x=2 in x+3 end
is evaluated by taking its right-hand side, x+3, and substituting
all occurrences of x with the value to which it bound, 2.
Therefore, it steps to 2+3 and then to 5. In general,
an expression of the form let val x=v in e'
end is evaluated by replacing it with e', but with
occurrences of x replaced by v. We
denote the result of this substitution as e'{v/x};
that is, there is a reduction
let val x=v in e'
Here are some examples of substitution:
x{true/x} = true
x{true/y} = x
(x+(2*x)){1/x} = 1 + (2*1)
(x + let val x = 1 in x end){2/x} = (2 + let val x = 1 in x end)
(fn x: int => x+1)(#1 x){(3,"three")/x} = (fn x: int => x+1)(#1 (3,"three"))
Occurrences of a variable in an expression can be either bound, unbound,
or binding occurrences. For example, in the expression x+3, the variable
x is unbound: its meaning is not defined by the expression. In the expression x + let val
x = 1 in x+3 end, the first occurrence of x
is unbound; the second is a binding occurrence that binds x to the
value 1 throughout the body of the let expression. The third occurrence is a
bound occurrence because it occurs within the scope of the second,
binding occurrence.
The last two substitution examples illustrate an important point: when we substitute for some variable x, we don't replace the binding or bound occurrences of x, because that variable is really a different variable despite having the same name.
We can also use substitution to explain the action of a function invocation. An expression of the form
(fn(x: t) => e) (v)
reduces to
e{v/x}
That is, we take the body of the function and replace all unbound occurrences
of x (which must have been bound by the binding occurrence
in the argument list) with the actual argument value v.
What about named functions? A declaration of the form
fun f(x: t):t' = e
is mostly just syntactic sugar for the declaration
val f = fn(x: t) => e
(it isn't completely syntactic sugar because a named function can refer to itself recursively. But that's another story.) So we can understand the evaluation of calls to non-anonymous functions as using the same rule that anonymous functions do. Here's an example:
let val y = 3 in
fun f(x:int):int = x*y
in
f(2+y)
end
-> (let reduction)
let fun f(x:int):int = x*3
in
f(2+3)
end
-> (let reduction)
(fn(x:int):int => x*3)(2+3)
-> (+ reduction)
(fn(x:int):int => x*3)(5)
-> (fn application reduction)
5*3
-> (* reduction)
8
The other thing we have to keep in mind is that we can't perform reductions just anywhere. Each SML expression imposes some order on the evaluation of its subexpressions. For example, no reductions can be performed on the body of a let expression until all of its declarations have been evaluated and the results substituted into the body. Similarly, no evaluations are performed
When we talk about language semantics, we first need to say what it is we are defining the semantics of; that is, what is our representation of a "program". One obvious representation is the stream of bytes that are the ASCII codes for the characters in the program. However, this representation is not convenient for talking about language semantics.
Early in the course we commented on a similarity between BNF declarations and
datatype declarations. In fact, we can define datatype declarations
that act like the corresponding BNF declarations. The values of these datatypes
then represent legal expressions that can occur in the language. For example,
our earlier BNF definition of legal SML types
(base types) b ::= int | real | string | bool | char
(types) t ::= b | t1->t2 | t1*t2*...*tn | { id1 : t1,..., idn : tn } | id
has the same structure as the following datatype declarations:
type id = string datatype baseType = Int | Real | String | Bool | Char datatype type_ = Base of baseType | Arrow of type_*type_ | Product of type_ List | Record of (id*type_) List | DatatypeName of id
Any legal SML type expression can be represented by a value of type type_
that contains all the information in the type expression. This value is known as
the abstract syntax for that expression. It is abstract, because it
doesn't contain any information about the actual symbols used to represent the
expression in the program. For example, the abstract syntax for the (type)
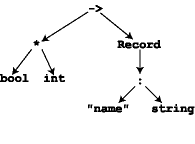
expression int*bool->{name: string} would be
Arrow( Product(Cons(Base Int, Cons(Base Bool, Nil))),
Record(Cons(("name", Base String), Nil)))
It will be convenient to draw abstract syntax as trees. For example, the expression above has the following abstract syntax tree (AST):
->
is written where Arrow could be as easily and as correctly written
instead.
Compilers typically use abstract syntax internally to represent the program that they are compiling, and we can also use it to talk about operational semantics. Inside a compiler it is the job of the parser to convert the string-of-characters representation of the program into the abstract syntax. Parsers can be built mostly automatically by giving the BNF grammar for the language to an parser generator. To learn how parser generators work, take CS 412!
Now that we have a representation of an SML program as a data structure, we have the opportunity to precisely define the semantics of SML by writing a definitional interpreter. An interpreter is a program that accepts as input another program written in some language, and executes that program (or simulates its execution, depending on your viewpoint). A definitional interpreter is an interpreter written for the purpose of describing the semantics of a programming language. Since its purpose is to help us understand what SML programs are supposed to do, we will put a premium on clarity and worry less about performance issues here. However, it is possible to produce a reasonably fast interpreter using the basic approach shown here.
Below is a definitional interpreter for a subset of SML. Here are some things to notice about this interpreter:
is_value
that figures out whether an expression is a value according to the rules
above.toString is a helpful function that prints out expressions in
a more readable form than the AST it accepts as input. It isn't really part
of the interpreter, though.subst explains how substitution is done. Notice that the
rules for substituting variables in let and fn expressions only substitute
into the bodies of these expressions if the variable being substituted is
not bound by the expression.eval_binop implements all the reductions for primitive types.eval takes an expression AST as input and gives
the value that the expression evaluates to.
eval() to finish the evaluation of the new
reduced expression.eval and eval'
so that the interpreter not only reports the final result of evaluation,
but also reports each intermediate step along the way.In Problem Set 5, you will be building an interpreter for a language that is not too different from ML, except that it is a concurrent language. Like this interpreter, your interpreter will have to implement reductions. Unlike this interpreter, your evaluator will only take one evaluation step at a time. This will be necessary in order to simulate the execution of multiple concurrent processes. So this interpreter is in some ways a good model of your code for problem set 5, but not in others.
The language above doesn't support datatypes or pattern matching. Here is a definitional interpreter based on the substitution model that does support pattern matching.
<% ShowSMLFile("code/interp2.sml") %>