Priority queues are a kind of queue in which the elements are dequeued in priority order.
| <% ShowSMLFile("src/imp_prioq.sml") %> |
There are many ways to implement this signature. For example, we could implement it as a linked list where the cells of the list are connected through refs so it can be updated imperatively:
| <% ShowSMLFile("src/list_prioq.sml") %> |
What is the asymptotic performance of this implementation?
insert: O(n),
because it has to bubble a new element in to its rightful place in the
sorted list.extract_min: O(1),
because it can just remove the first element of the list.Another alternative implementation is to use red-black trees or another of the balanced search trees. For example, in red-black trees we can find the minimum element by simply walking down the left children all the way from the root. Extracting the minimum element requires deleting it from the tree; we haven't seen how to do this, but it's about twice as complicated as the insertion we've already seen. This implementation has better performance for many applications:
insert: O(lg n),
because an element must be inserted into the tree according to its priority,
which serves as the key.extract_min: O(lg n),
because red-black deletion also requires walking up and down the tree.In fact, we can tell that this is the best we do in terms of asymptotic
performance, because we can implement sorting using O(n)
priority queue operations, and we know that sorting takes O(n
lg n) time in general. The idea is simply to insert
all the elements to be sorted into the priority queue, and then use extract_min
to pull them out in the right order:
| <% ShowSMLFile("src/heapsort.sml") %> |
Although they have good asymptotic performance, it turns out that red-black trees are overkill for implementing priority queues: they are more complicated and slower than necessary. There is a simple, fast way to implement priority queues.
A heap is a special kind of balanced binary tree. (The term heap is also used to refer to the part of computer memory that is used to allocate new objects at run time; this is a different kind of heap.) The tree satisfies two invariants:
Suppose the priorities are just numbers. Here is a possible heap:
3
/ \
/ \
5 9
/ \ /
12 6 10
Obviously we can find the minimum element in O(1) time. Extracting it while
maintaining the heap invariant will take O(lg n)
time. Inserting a new element and establishing the heap invariant will
also take O(lg n) time. So
asymptotic performance is the same as for red-black trees but constant factors
are better for heaps.
The key observation is that we can represent a heaps as an array.
The root of the tree is at location 0 in the array and the children of the node
stored at position i are at locations 2i+1 and 2i+2. This means that the array
corresponding to the tree contains all the elements of tree, read across row by
row. The representation of the tree above is:
[3 5 9 12 6 10]
Given an element at index i, we can compute where the children are stored,
and conversely we can go from a child at index j to its parent at index floor((j-1)/2).
The rep invariant for heaps in this representation is actually simpler than when
in tree form:
Rep invariant for heap a (the partial
ordering property):
a[i] <= a[2i+1] and a[i] <= a[2i+2]
for 1 <= i <= floor((n-1)/2)
Now let's see how to implement the priority queue operations:
Put the element at first missing leaf. (Extend array by one element.)
Switch it with its parent if its parent is larger: "bubble up"
Repeat #2 as necessary.
Example: inserting 4 into previous tree.
3
/ \
/ \
5 9 [3 5 9 12 6 10 4]
/ \ / \
12 6 10 4
3
/ \
/ \
5 4 [3 5 4 12 6 10 9]
/ \ / \
12 6 10 9
This operation requires only O(lg n)
time -- the tree is depth
ceil(lg n) , and we do a bounded amount of work on each level.
extract_min works by returning the element at the root.
The trick is this:
Original heap to delete top element from (leaves two subheaps)
3
/ \
/ \
5 4 [3 5 4 12 6 10 9]
/ \ / \
12 6 10 9
copy last leaf to root
9
/ \
/ \
5 4 [9 5 4 12 6 10]
/ \ /
12 6 10
"push down"
4
/ \
/ \
5 9 [9 5 4 12 6 10]
/ \ /
12 6 10
Again an O(lg n) operation.
We can sort using this implementation of priority queues.
How expensive is the sorting function built from this?
n insertions, at O(lg n) cost, for O(n
lg n) total
n deletions, at O(lg n) cost, for
O(n lg n) total.
Thus, O(n lg n) total cost.
It's called heapsort and it's a reliable standard sorting algorithm.
If you have to sort by doing comparisons only, this is as fast as possible (up to a constant factor).
There are plenty of other O(n lg n)
algorithms with better properties in some cases, for example:
One last comment -- you might be worried about the fixed size for the array of values. The
solution is just to use a resizable array abstraction (like Java Vectors), which you
should be able to figure out how to
build.
In recitation we talked a bit about graphs: how to represent them and how to traverse them. Today we will discuss one of the most important graph algorithms: Dijkstra's shortest path algorithm, a greedy algorithm that efficiently finds shortest paths in a graph. (Pronunciation: "Dijkstra" is Dutch and sounds like "dike").
Many more problems than you might at first think can be cast as shortest path problems, making this algorithm a powerful and general tool. For example, Dijkstra's algorithm is a good way to implement a service like MapQuest that finds the shortest way to drive between two points on the map. It can also be used to solve problems like network routing, where the goal is to find the shortest path for data packets to take through a switching network. It is also used in more general search algorithms for a variety of problems ranging from automated circuit layout to speech recognition.
Let's start by defining a data abstraction for weighted, directed graphs so we can express algorithms independently of the implementation of graphs themselves. In a weighted graph, each of its edges has a nonnegative weight that we can think of as the distance one must travel when going along that edge.
| <% ShowSMLFile("src/wgraph.sig") %> |
There are some constraints on the running time of certain operations in this specification. Importantly, we assume that given a vertex, we can traverse the outgoing edges in constant time per edge. Some graph implementations do not have these properties, but we can easily write an almost trivial implementation that does:
| <% ShowSMLFile("src/wgraph.sml") %> |
A path through the graph is a sequence (v1, ..., vn) such that the graph contains an edge e1 going from v1 to v2, an edge e2 going from v2 to v3, and so on. That is, all the edges must be traversed in the forward direction. The length of a path in a weighted graph is the sum of the weights along these edges e1,..., en-1. We call this property "length" even though for some graphs it may represent some other quantity: for example, money or time.
To implement MapQuest, we need to solve the following shortest-path problem:
Given two vertices v and v', what is the shortest path through the graph that goes from v to v' ? That is, the path for which summing up the weights along all the edges from v to v' results in the smallest sum possible.
It turns out that we can solve this problem efficiently by solving a more general problem, the single-source shortest-path problem:
Given a vertex v, what is the length of the shortest path from v to every vertex v' in the graph?
It is this problem that we will now investigate.
The single-source shortest path problem can also be formulated on an undirected graph; however, it is most easily solved by converting the undirected graph into a directed graph with twice as many edges, and then running the algorithm for directed graphs. There are other shortest-path problems of interest, such as the all-pairs shortest-path problem: find the lengths of shortest paths between all possible source–destination pairs. The Floyd-Warshall algorithm is a good way to solve this problem efficiently.
Let's consider a simpler problem: solving the single-source shortest path problem for an unweighted directed graph. In this case we are trying to find the smallest number of edges that must be traversed in order to get to every vertex in the graph. This is the same problem as solving the weighted version where all the weights happen to be 1.
Do we know an algorithm for determining this? Yes: breadth-first search. The running time of that algorithm is O(V+E) where V is the number of vertices and E is the number of edges, because it pushes each reachable vertex onto the queue and considers each outgoing edge from it once. There can't be any faster algorithm for solving this problem, because in general the algorithm must at least look at the entire graph, which has size O(V+E).
We saw in recitation that we could express both breadth-first and depth-first search with the same simple algorithm that varied just in the order in which vertices are removed from the queue. We just need an efficient implementation of sets to keep track of the vertices we have visited already. A hash table fits the bill perfectly with its O(1) amortized run time for all operations. Here is an imperative graph search algorithm that takes a source vertex v0 and performs graph search outward from it:
| <% ShowSMLFile("src/traversal1.sml") %> |
This code implicitly divides the set of vertices into three sets:
Except for the initial vertex v0,
the vertices in set 2 are always neighbors of vertices in set 1. Thus, the
queued vertices form a frontier in the graph, separating sets 1 and 3. The expand
function moves a frontier vertex into the completed set and then expands the
frontier to include any previously unseen neighbors of the new frontier vertex.
dequeue
function, which selects a vertex from a queue. If q is a FIFO
queue, we do a breadth-first search of the graph. If q is a LIFO
queue, we do a depth-first search.
If the graph is unweighted, we can use a FIFO queue and keep track of
the number of edges taken to get to a particular node. We augment the visited
set to keep track of the number of edges traversed from v0;
it becomes a map dist from vertices to edge counts (ints), possibly
implemented as a hash table (an even more imperative alternative is to store
distances directly in the vertices).
The only algorithmic modification needed is in expand, which adds to the
frontier a newly found vertex at a distance one greater than that of its
neighbor already in the frontier:
| <% ShowSMLFile("src/traversal2.sml") %> |
Now we can generalize to the problem of computing the shortest path between
two vertices in a weighted graph. We can solve this problem by making minor
modifications to the BFS algorithm for shortest paths in unweighted graphs. As
in that algorithm, we keep a visited map that maps vertices to their distances
from the source vertex v0. We
change expand so that instead of adding 1 to the distance, its adds
the weight of the edge traversed. Furthermore, when we find an already visited
vertex, we update its distance only if the new distance is less than the old
distance. Here is a first cut at an algorithm:
| <% ShowSMLFile("src/traversal3.sml") %> |
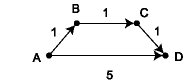
This is nearly Dijkstra's algorithm, but it doesn't work. To see why, consider the following graph, where the source vertex is v0 = A.
The first pass of the algorithm will add vertices B and D to the map visited,
with distances 1 and 5 respectively. D will then become part of the completed
set with distance 5. Yet there is a path from A to D with the shorter length 3.
We need two fixes to the algorithm just presented:
SOME case a check is needed to see whether the path
just discovered to the vertex v' is an improvement on the
previously discovered path (which had length d)q should not be a FIFO queue. Instead, it should be a priority
queue where the priorities of the vertices in the queue are their
distances recorded in visited. That is, dequeue(q) should be a
priority queue extract_min operation that removes the vertex
with the smallest distance.incr_priority(q,v)
that increases the priority of an element v already in the
queue q. This new operation is easily implemented for heaps
using the same bubbling-up algorithm used when performing heap insertions.With these two modifications, we have Dijkstra's single-source shortest path algorithm:
| <% ShowSMLFile("src/traversal5.sml") %> |
There are two natural questions to ask at this point: Does it work? How fast is it?
Every time the main loop executes, one vertex is extracted from the queue.
Assuming that there are V vertices in the
graph, the queue may contain O(V)
vertices. Each extract_min operation takes O(lg V)
time assuming the heap implementation of priority queues. So the total time
required to execute the main loop itself is O(V
lg V). In addition, we must consider the time spent in the
function expand, which applies the function handle_edge
to each outgoing edge. Because expand is only called once per
vertex, handle_edge is only called once per edge. It might call insert(v'),
but there can be at most V such calls
during the entire execution, so the total cost of that case arm is at most O(V
lg V). The other case arm may be called O(E)
times, however, and each call to increase_priority takes O(lg
V) time with the heap implementation. Therefore the total run time
is O(V lg V + E lg V),
which is O(E lg V) because V
is O(E) assuming a connected graph.
There is a more complicated priority-queue implementation called a Fibonacci heap that implements
incr_priorityin O(1) time, so that the asymptotic complexity of Dijkstra's algorithm becomes O(V lg V + E). However, this bound is largely of theoretical interest because large constant factors make Fibonacci heaps impractical for most uses.
Each time that expand is called, a vertex is moved from the
frontier set to the completed set. Dijkstra's algorithm is an example of a greedy
algorithm, because it just chooses the closest frontier vertex at every
step. A locally optimal, "greedy" step turns out to produce the global
optimal solution. We can see that this algorithm finds the shortest-path
distances in the graph example above, because it will successively move B and C
into the completed set, before D, and thus D's recorded distance has been
correctly set to 3 before it is selected by the priority queue.
The algorithm works because it maintains a loop invariant that
holds every time the while loop is executed:
For every visited vertex v, the recorded distance (in visited) is the
shortest-path distance to that vertex from v0,
considering just the paths that traverse only completed vertices and the
vertex v itself. We will call these paths
internal paths.
This invariant obviously holds when the main loop starts, because the only visited vertex is v0 itself, at recorded distance 0. If the invariant holds when the algorithm terminates, the algorithm works correctly, because all vertices are completed and all paths are internal paths. To show that the algorithm works, we need to show that the algorithm terminates and that each iteration of the main loop preserves the invariant.
Clearly the algorithm terminates, because a vertex can only be inserted once and every loop removes some vertex from the frontier. Showing the invariant is preserved is more interesting.
Each step of the main loop takes the closest frontier vertex v and promotes it to the completed set. For the invariant to be maintained, it must be the case that the recorded distance for the closest frontier vertex is also the shortest internal-path distance to that vertex. However, adding v to the completed set creates no new internal paths to v, so the existing distance must still be the best internal-path distance.
We need to show that the invariant holds on all the other visited vertices too. To show this we begin by observing that the recorded distance to the vertex that is removed from the priority queue can never decrease from one loop iteration to the next; that is, executing the loop can only increase the priority of the minimum-priority element in the queue. Consider what happens during one execution of the loop. Extracting the minimum element clearly leaves behind elements that have distances at least as large. One iteration may add some new elements to the queue, but at distances no less than that of the vertex just removed. It may also reduce the distance estimate to some elements already in the queue, but the new distance estimate will also be no less than that of the vertex just removed.
For vertices that are not successors to v, adding v can only create new internal paths if those paths go through another completed vertex v′. But by the monotonicity argument in the previous paragraph, the distance to v' must be less than the distance to v, so any such new internal path will be at least as long as the already known path.
A vertex v′ that is a successor to v is either a completed vertex, a newly visited vertex, or on the frontier:
d+w is the shortest internal-path distance of v′.d+w, and this path might be better than the
previously known paths. Adding v might also
create other new internal paths that visits some completed vertex (or
vertices) v′′ after v
and before v′. However, the other
completed vertices are closer than v, so
for any such path, there is another shorter path to v′′
(and hence v′ ) that doesn't go
through v. The existing distance estimate
for v′ must already include this
estimate.We might also be concerned that incr_priority could be called on
a vertex that is not in the priority queue at all. But this can't happen because
incr_priority is only called if a shorter path has been found to a
completed vertex v′. Because of the
monotonic increase in distances, this shorter path cannot exist.
The invariant implies that we can use Dijkstra's algorithm a little more efficiently to solve the simple shortest-path problem in which we're interested only in a particular destination vertex. Once that vertex is dequeued from the priority queue, the traversal can be halted because its recorded distance is correct. Thus, to find the distance to a vertex v the traversal only needs to visit the graph vertices that are at least as close to the source as v is.
Cormen, Leiserson, and Rivest. Introduction to Algorithms.
Aho, Hopcroft, Ullman. Data Structures and Algorithms.