Related work
A number of systems address the requirements described in the previous section. Here some the most relevant are briefly described.
LOCUS
The LOCUS distributed operating system [15] incorporates a Unix-compatible file system with replication and transactional features. Replication is intended to increase availability and more efficient access. Files are assigned to file groups, which may be wholly or partially replicated at a site. The file creation operation specifies how many times a file should be replicated.
Each file group has a designated current synchronisation site (CSS), which is free to implement its own synchronisation policy. If the network becomes partitioned, a file group has a CSS in each section of the partition. All file open operations are directed to the CSS of the group a file belongs to, after which the CSS forwards the request to a server in the group. The client then interacts with this server. Changes made to a single file are atomic, and are temporarily recorded using a shadow-page mechanism. Upon a file close, the changes are committed by writing the file's inode to disk. Though this facility only permits modification to a single file within a transaction, it makes updates atomic across machine failures. Partitions of the network introduce the possibility of inconsistent versions of files arising in disjoint parts of the partition, which are resolved automatically when possible, and with user intervention in other cases. Upon a commit, the server must notify all other replica servers and the CSS, which decides when the update is complete. Since only one server modifies the file, individual replica servers do not take any commit or abort decisions. There is therefore no need for an expensive 2-phase commit. A more advanced facility for nested transactions is described in [8], but is not discussed here.
The system proposed in this paper differs from LOCUS in allowing servers holding a replica of an object to handle updates autonomously, without reference to any centralised synchronisation manager (a potential bottleneck in a large system). Propagation of updates among replica servers is also managed asynchronously, rather than synchronously as in LOCUS. While allowing some clients to see the effects of updates faster, it introduces the possibility of clients observing transient inconsistencies.
QuickSilver
The QuickSilver distributed system [4] provides an example of a general mechanism for controlling data sharing in a distributed environment. QuickSilver is an operating system based on a ``lean'' kernel, over which system services are implemented as user-level servers. Viewing replication as too expensive and insufficiently general to provide an effective basis for resilience to failures, the designers of QuickSilver chose to implement a transaction-based recovery service for use by servers. A server can declare itself to stateless or recoverable; a recoverable server is included in a transaction when the client owning the transaction sends it an IPC request. This IPC message registers the participation of the server with the transaction manager running on the server's machine.
Transactions are terminated when the client commits or aborts, or when a participating server aborts. 2-phase commit is employed, with the option that servers may cast a ``read-only'' vote after the preparation phase. This indicates that they have not modified any resources and wish to be excluded from the second round. Each transaction manager maintains its own log, which is shared with servers at that machine. Servers define their own recovery procedures using the log. The authors state that services which need to manage replicas, such as the naming services, do not use the full capabilities of the transaction mechanism, relying on atomic updates only. This is a service which has been handled with lazy updates in some other systems, such as Grapevine [2].
Argus
The Argus programming language [7] is an environment for writing distributed applications, supporting atomic actions, which are serialisable and can be nested. Programs access guardians (servers) by invoking handlers which the guardians define; individual guardians implement their own concurrency control for access to the objects they manage. Transaction nesting requires lock propagation among invocations at the same node, and two-phase commit. A log is used for recovery, with periodic snapshots of the state of guardians.
Clients accessing an Argus guardian are only able to modify objects through the interface the guardian provides. This provides a much higher degree of control over modifications to objects than the system described in this paper. The price paid is in the need to make a call to a guardian for every access, potentially requiring inter-machine communication each time. Mapping an object directly into the client's address space permits access by making a local procedure call.
Bayou
The Bayou storage system [13] is designed for a network of computers in which machines may be only intermittently connected. The assumption of weak connectivity leads to a scheme incorporating the idea of eventual consistency between data replicas, which may require rollback of updates when the propagation of changes between replicas reveals inconsistencies. Updates are propagated by asynchronous, pair-wise communication between replicas. In the absence of further updates, replicas will eventually become consistent, providing that the network is indefinitely partitioned. However, there is no upper bound on the time which an update will take to be reflected in all replicas.
Updates which have not attained stability are marked as tentative. Application-specific checks supplied with updates allow servers to detect possible conflicts. Each update specifies a ``dependency check'' to be made against the replica's data set. The update also includes a ``merge procedure'' to resolve any conflicts which are detected. The order in which updates are finalised is decided by the primary server of the data set. If a replica server is unable to communicate with the primary server, it must mark all updates as tentative. Update rollback is achieved using a log of tentative and committed updates maintained with each replica. The status of an update can be queried by the client.
Updates are communicated between pairs of servers using an anti-entropy [3] session, in which one server tells the other which updates it has seen. This algorithm, elaborated in [9], is similar to the gossip rounds of the probabilistic broadcast protocol, described in the next section. Unlike Bayou, the system proposed in this paper has no notion of committed writes -- there is no global order for updates and so no need for a primary server, a possible impediment to scalability.
Swallow
Swallow [12,10] is a reliable distributed data repository, which permits clients to access data in the framework of atomic actions. Each object in the repository is represented by a history of states, consisting of a series of immutable versions of the object. A repository stores its data on append-only optical disks, which provide stable storage. The existence of time-stamped versions permits accounting and consistent snapshots of the repository state.
Atomic transactions are implemented by a system of object headers and commit records. Each object has an object header with a pointer to the most recent version of the object; when a transaction modifies an object, it creates a tentative version, referenced by a separate pointer in the header. Each transaction has a commit record which the headers of modified objects and the tentative versions also reference. In this way, committing a transaction merely requires updating this record and writing it to stable storage. A protocol similar to two-phase commit is used for transactions that access more than one repository.
The notion of object versions incorporated into Swallow is used in the system presented here, but with a somewhat different purpose -- allowing different clients to see object versions with different degrees of stability. This is further elaborated upon in section 4.
Probabilistic broadcast
The probabilistic broadcast protocol [1,6] is a mechanism for one-to-many communication among a group of cooperating processes, which can reside on distinct machines. It is intended to be resilient to transient degradation of network performance and group members with potentially slow response times. It is also aims to be highly scalable, eventually accommodating groups whose sizes number in the thousands. Both these goals address shortcomings which the authors of [1] identify in current heavy-weight group communication protocols (for instance, the Horus system [14]).
The protocol consists of two complementary components: a message is sent by an initial, potentially unreliable multicast to the members of the group, followed by ``gossip'' to propagate the message to group members which did not receive the initial multicast. Gossip communication proceeds in rounds, which are not synchronised between processes. In each round, a process randomly selects another process in the group and sends it a digest of its most recently-received messages. The recipient of the digest may then ask the digest's sender to retransmit any messages which have not been received. After holding each message for a pre-specified number of rounds, a process may garbage-collect it to reclaim memory.
The theory underlying this gossip strategy is described in [3]. Messages spread through the group in a similar manner to an epidemic. In each new gossip round, a message ``infects'' processes which have not yet received it, until all group members have received a copy of the message. Given certain assumptions regarding the behaviour of the underlying network, the epidemic model allows the number of receivers of a message to be characterised by a bimodal distribution -- this is, a small probability exists that a only few processes have received the message, a large probability that all or nearly all processes have received the message, and intervening events have a negligible probability. The protocol can thus offer a probabilistic guarantee of the success of a broadcast.
Outline of implementation
The system proposed exploits the features of the probabilistic broadcast protocol to create a toolkit for implementing weakly-consistent shared objects in a distributed system. The object management system makes some sacrifices in the consistency of the objects, in exchange for an minimal client overhead and improved scalability.
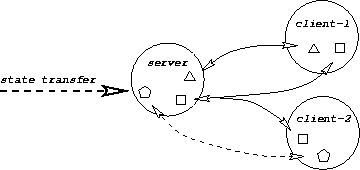
An object server runs on each host, responsible for caching replicas of objects and propagating local updates of an object to the other replicas which cache it. A client interested in accessing an object contacts its local server. The server obtains a replica of the object and maps it into the client's address space; the client then accesses the object through read and write library calls. Figure 1 illustrates a configuration of the components on a single machine. When the client updates the object, the server is alerted. It uses a probabilistic broadcast to notify the other servers maintaining the object -- that is, it uses an initial broadcast, followed by gossip rounds.
 |
A consequence of the probabilistic broadcast algorithm is that a message sent out to a group of servers has an associated bimodal probability distribution, which specifies the distribution of the number of servers reached by the message. As the number of rounds since the message was sent increases, the parameters of the distribution change and the probability that all or almost all the servers have received the message increases. We can view the probability of the occurrence ``all servers have received a copy of the update message'' as a measure of the stability of the update. It follows that the more rounds an update message is ``delayed'' by a server before being reflected in the client's copy of an object, the more stable the associated update is.
This feature can be exploited by a client interested in messages which have achieved a certain stability within the group of servers. By specifying a delay in terms of the number of rounds for which its local server should hold back an update, it can assure itself that the copy of the object that it sees has attained a particular level of stability. This means that a client which is principally interested in urgent updates can set a minimal delay, while one with a more long-term view would opt for a greater update delay.
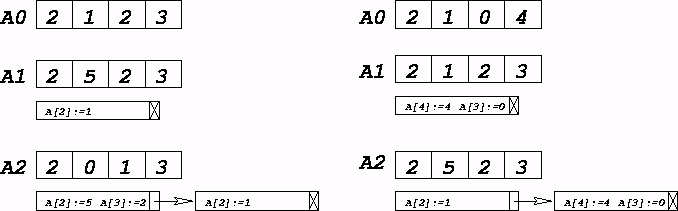 |
A consequence of different clients at a host wishing to see different views is that the server must maintain a sequence of temporally distinct versions of each object it replicates. Each object version has a queue of pending updates, sorted by age, which must be applied at the start of each new round of gossip. The client, however, sees only the version it is interested in, and accesses it by a call within its own address space. All updates to the object are handled asynchronously by the server, with the client accessing the object using an in-process procedure call. Figure 2 gives an conceptual example of object management by a server.
Further details
This section identifies the areas of the implementation which have still to be decided, as well as possible applications and experiments that will be conducted to evaluate the system.
Issues in implementation
It is intended that the system implementation will follow the description in the preceding section, but there the details of how the mapping of an object from a server to a client were left deliberately vague. It is currently planned that the Unix mmap facility will be used, with a backing file created by the server. An unresolved problem concerns the most appropriate method of mapping object and performing updates on them -- in particular, a question arises regarding whether the server should maintain a separate copy of the object for each client, or let clients share and have a single copy per version. The latter option would appear to require less space and work to apply updates, but the former may result in less contention between clients accessing the same shared memory region. It would also prevent a disastrous memory reference in one client destroying another client's copy of the object.
Given that a client reads and updates the object by making calls to local procedures, another question arises in the behaviour of updates. An update operation alerts the server so that it will propagate the update to other servers, but it is unclear whether the effect of a client's update should be immediately reflected in the client's copy of the object or not. In this situation, the correct behaviour is not obvious. Taking the attitude that the results of the update should be deferred until it satisfies the client's desired update stability seems preferable, since it is consistent with the treatment of incoming updates made remotely. However, it leads to a situation where local updates have a delayed effect and may result in the client being designed to block until the results are seen!
Finally, the issue of concurrency control between the client and server to control changes to the shared object copy must be considered. It seems desirable that a client read blocks until the server has finished writing a remote update to the object. What the most effective scheme to implement this is has not been decided.
Although it is a stated design goal that the system should be as simple as possible, and have a minimum of overhead, the addition of features such as causal ordering may be investigated to see if their complexity is warranted. It would be interesting to see how complicated a facility providing ``probabilistic transactions'' would be, in which updates forming the transaction are seen as an atomic group by recipients.
Applications and experiments
This section addresses what sort of applications a system with the guarantees described might be suited to, and how its performance might be examined.
 |
The probabilistic broadcast protocol only ensures a local ordering --
that is, if message m precedes message
![]() from a server
S, then all other servers will report m before
from a server
S, then all other servers will report m before
![]() .
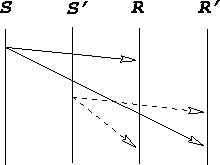
However, if we have two servers, each sending updates, a
case may arise where clients receive their messages in an incorrect
order, as depicted in Figure 3. As the diagram
illustrates, a multicasts from distinct servers are not guaranteed to
be received in a consistent order by different receiver
processes. This fact has repercussions if probabilistic broadcast is
used for data sharing, since two clients can view inconsistent copies
of a shared data object at the same time. Applications which seek to
share data using the system described here might be partitioned into
two classes:
.
However, if we have two servers, each sending updates, a
case may arise where clients receive their messages in an incorrect
order, as depicted in Figure 3. As the diagram
illustrates, a multicasts from distinct servers are not guaranteed to
be received in a consistent order by different receiver
processes. This fact has repercussions if probabilistic broadcast is
used for data sharing, since two clients can view inconsistent copies
of a shared data object at the same time. Applications which seek to
share data using the system described here might be partitioned into
two classes:
- Objects each ``reside'' at a single server, where all or almost all modifications are made; other servers cache read-only replicas.
- Objects are fully sharable, but the volume of updates is high and transient inconsistencies are tolerated.
Inconsistencies might arise in such a system when an object might move from the area managed by one server to another. In this case, there is a period after the handoff from one server to another where a message from the old server might be received late by the monitoring process. However, the volume of updates to the object would ensure that such an inconsistency would be quickly rectified, since more updates from the new server would quickly arrive to overwrite the incorrect value.
Experiments will be designed to simulate such a system in a network of
computers, each running a server, and with objects which ``move'' from
the control of one server to another in a random, but repeatable
manner. Clients will watch the updates to objects and log them to
allow analysis and detection of inconsistencies. The following
experiments are being considered:
- Measuring the throughput of the system and evaluating the overhead of the shared object mechanism
- Analysis of how serious inconsistencies are and how long they persist
- Measuring how much overhead concurrency control between client and server causes, and the cost of sharing objects via mmap.
- Comparison of the cost of building on top of a probabilistic-broadcast-based system, in comparison to one implemented on top of reliable group communication, such as is provided by the Ensemble system [5].