Overview
Intelligibility is just as important as accuracy. Intelligible models, a special class of generalized additive models (GAMs), recover low dimensional additive structure via shaping single features and pairwise interactions that can be easily visualized. Intelligible models also accurately approximate high dimensional full complexity functions.
This package (as part of the MLTK package) provides a collection of tools that learn and visualize intelligible models that are comparable to complex models such as random forests.
Code
The source code requires Java 7 and is released under the BSD license. API documentation can be found here. If you have questions or suggestions with the code, please email Yin Lou.
Usage
1. Data Format
Datasets should be provided in separate white-space-delimited text files without any headers. We support continuous, nominal and binned attributes. All datasets should have the same number and order of columns. The structure of the attribute description is the following:
attribute_name: type [(class)]
There are two types of binned attributes. One is specified using the number of bins, and the other is specified using number of bins, upper bounds and medians for each bin.
| Example attribute file | Example data file |
|---|---|
|
f1: cont f2: {a, b, c} f3: binned (256) f4: binned (3;[1, 5, 6];[0.5, 2.5, 3]) label: cont (class) |
0.1 1 2 0 5 -2.3 0 255 1 2 3.1 2 128 2 -3 5 1 0 1 0.2 0.1 1 37 0 0.1 |
2. Discretizing the Dataset
Usage: mltk.core.Discretizer -r attribute file path -i input dataset path -o output dataset path [-d] discretized attribute file path [-m] output attribute file path [-n] maximum num of bins (default: 256) [-t] training file path
When training set is provided, output attribute file path is also needed to save discretization information. Discretization is required for interaction detection and shaping pairwise interactions.
Example. Use the following commands to discretize the California Housing dataset. Remember to set the CLASSPATH with the command export CLASSPATH=<path to gam.jar>:$CLASSPATH, or use the -cp option with java command.
$ java mltk.core.Discretizer -r cal_housing.attr -t cal_housing.train.all -m cal_housing_binned.attr -i cal_housing.train -o cal_housing_binned.train
This command uses "cal_housing.train.all" to create discretizers (saved in cal_housing_binned.attr), and discretizes "cal_housing.train" (saved in cal_housing_binned.train).
$ java mltk.core.Discretizer -r cal_housing.attr -d cal_housing_binned.attr -i cal_housing.valid -o cal_housing_binned.valid
$ java mltk.core.Discretizer -r cal_housing.attr -d cal_housing_binned.attr -i cal_housing.test -o cal_housing_binned.test
These two commands use the discretized information (in "cal_housing_binned.attr") and discretize the validation set (cal_housing_binned.valid) and test set (cal_housing_binned.test).
3. Building GAM
Usage: mltk.predictor.gam.GAMLearner -r attribute file path -t train set path [-T] test set path [-v] valid set path [-o] output model path [-R] residual path [-g] task between classification (c) and regression (r) (default: r) [-c] maximum number of leaves (default: 3) [-m] maximum number of iterations (default: 0) [-b] bagging iterations (default: 100) [-l] learning rate (default: 0.01) [-s] seed of the random number generator (default: 0)
The task can be "regression" or "classification". If validation set is provided, the best model on the validation set will be produced. Learning rate 0.01 is recommended for classification and for regression, the learning rate is recommended to be 1 (one can use 0.01 but it takes much longer to train a model).
Example. Use the following command to train an additive model on California Housing dataset.
$ java mltk.predictor.gam.GAMLearner -r cal_housing_binned.attr -t cal_housing_binned.train -v cal_housing_binned.valid -T cal_housing_binned.test -m 1000 -l 1 -R cal_housing.residual -o gam.model
This command should produce the following output. Residuals are saved in cal_housing.residual and GAM model is saved in gam.model. The residuals are used in interaction detection and the "gam.model" will be used to build GA^2M model.
RMSE on Test: 57680.782921282895
4. Interaction Detection
Usage: mltk.predictor.gam.interaction.FAST -r attribute file path -t dataset path -R residual path -o output path [-b] number of bins (default: 8) [-p] number of threads (default: 1)
All attributes must be binned or nominal. Residuals after feature shaping needs to be provided (-R in training GAM).
Example. Use the following command to measure the strength of all pairs of interactions (saved in interactions.txt).
$ java mltk.predictor.gam.interaction.FAST -r cal_housing_binned.attr -t cal_housing_binned.train -R cal_housing.residual -o interactions.txt
The output is a list of triples, where the first two elements are indices of the attributes, and the third element is the residual sum of squares (RSS). Stronger pairwise interactions have lower RSS. For California Housing dataset, it is expected that first two attributes (longitude and latitude) are strongly interacting.
5. Building GA^2M
Usage: mltk.predictor.gam.GA2MLearner -r attribute file path -t train set path -i input model path -I list of pairwise interactions path -m maximum number of iterations [-T] test set path [-v] valid set path [-o] output model path [-g] task between classification (c) and regression (r) (default: r) [-b] bagging iterations (default: 100) [-l] learning rate (default: 0.01) [-s] seed of the random number generator (default: 0)
All attributes must be binned or nominal. -I can use the output from interaction detection or any list of pairs (the strength of a pair can be omitted).
Example. Use the following command to train a GA^M model on California Housing dataset.
$ java mltk.predictor.gam.GA2MLearner -r cal_housing_binned.attr -t cal_housing_binned.train -v cal_housing_binned.valid -T cal_housing_binned.test -i gam.model -I interactions.txt -m 1000 -l 1 -o ga2m.model
This command should produce the following output and produce a GA^2M model (saved in ga2m.model).
RMSE on Test: 49839.289160578825
6. Diagnostics
Usage: mltk.predictor.gam.tool.Diagnostics -r attribute file path -d dataset path -i input model path -o output path
This command produces a list of terms in the model, sorted by their weights.
Example. Use the following command to measure the weights for each component in a GAM model (saved in diagnostics.txt).
$ java mltk.predictor.gam.tool.Diagnostics -r cal_housing_binned.attr -d cal_housing_binned.train -i ga2m.model -o diagnostics.txt
The output is a list of terms, followed by their weights.
7. Visualization
Usage: mltk.predictor.gam.tool.Visualizer -r attribute file path -d dataset path -i input model path -o output directory path [-t] output terminal (default: png)
This command generates a set of Gnuplot scripts for plotting effects in the GAM. A new directory will be created if the specified directory path does not exist. Once all the scripts are generated, the following bash command can be used to generate plots.
Example. Use the following commands to generate plots for the GAM.
$ java mltk.predictor.gam.tool.Visualizer -r cal_housing_binned.attr -d cal_housing_binned.train -i ga2m.model -o plots
$ cd plots
$ for f in *.plt; do gnuplot $f; done
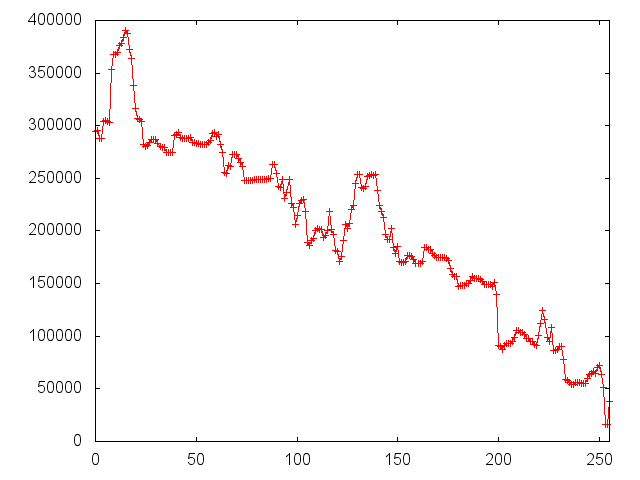
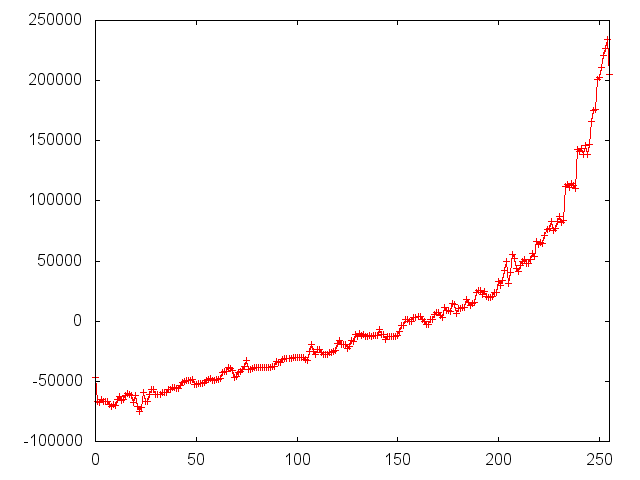
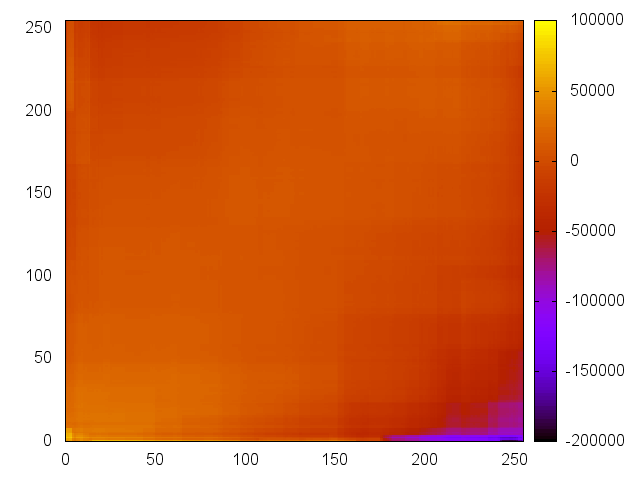
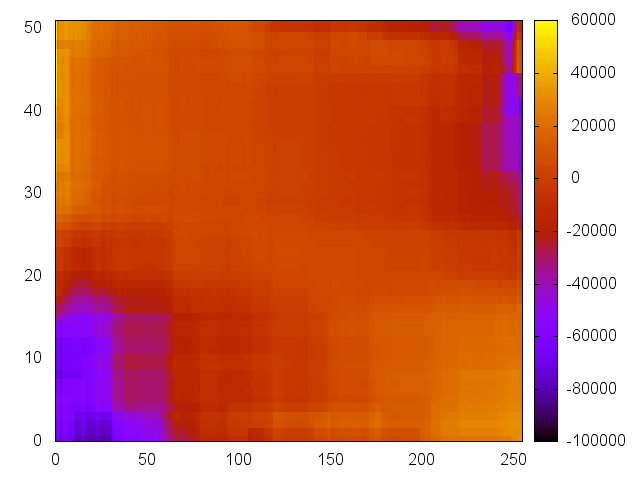
Some sample plots are shown below. A complete set of plots can be downloaded from here.
 |
 |
 |
 |
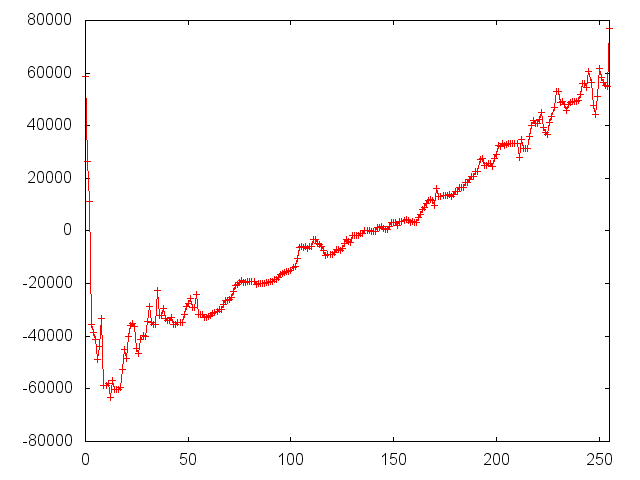 |
| latitude | longitude | medianIncome | population | households |
 |
 |
 |
 |
 |
| latitude vs. longitude | medianIncome vs. totalRooms | population vs. housingMedianAge | medianIncome vs. population | households vs. housingMedianAge |
Reference
Accurate Intelligible Models with Pairwise Interactions.
Yin Lou, Rich Caruana, Johannes Gehrke, and Giles Hooker.
KDD'13, Chicago, IL, USA. [BibTex]
@inproceedings{lou2013ga2m,
author = {Lou, Yin and Caruana, Rich and Gehrke, Johannes and Hooker, Giles},
title = {Accurate Intelligible Models with Pairwise Interactions},
booktitle = {Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
year = {2013},
location = {Chicago, IL, USA}
}
Intelligible Models for Classification and Regression.
Yin Lou, Rich Caruana, and Johannes Gehrke.
KDD'12, Beijing, China. [BibTex]
@inproceedings{lou2012intelligible,
author = {Lou, Yin and Caruana, Rich and Gehrke, Johannes},
title = {Intelligible Models for Classification and Regression},
booktitle = {Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining},
year = {2012},
location = {Beijing, China}
}
Acknowledgements
This work was done while Yin Lou was an intern at Microsoft Research/Bing in Summer 2011 and Summer 2012. We thank anonymous reviewers for their valuable comments. This research has been supported by the NSF under Grants IIS-0911036 and IIS-1012593. Any opinions, findings, conclusions or recommendations expressed are those of the authors and do not necessarily reflect the views of the sponsors.