
PUBLICATIONS
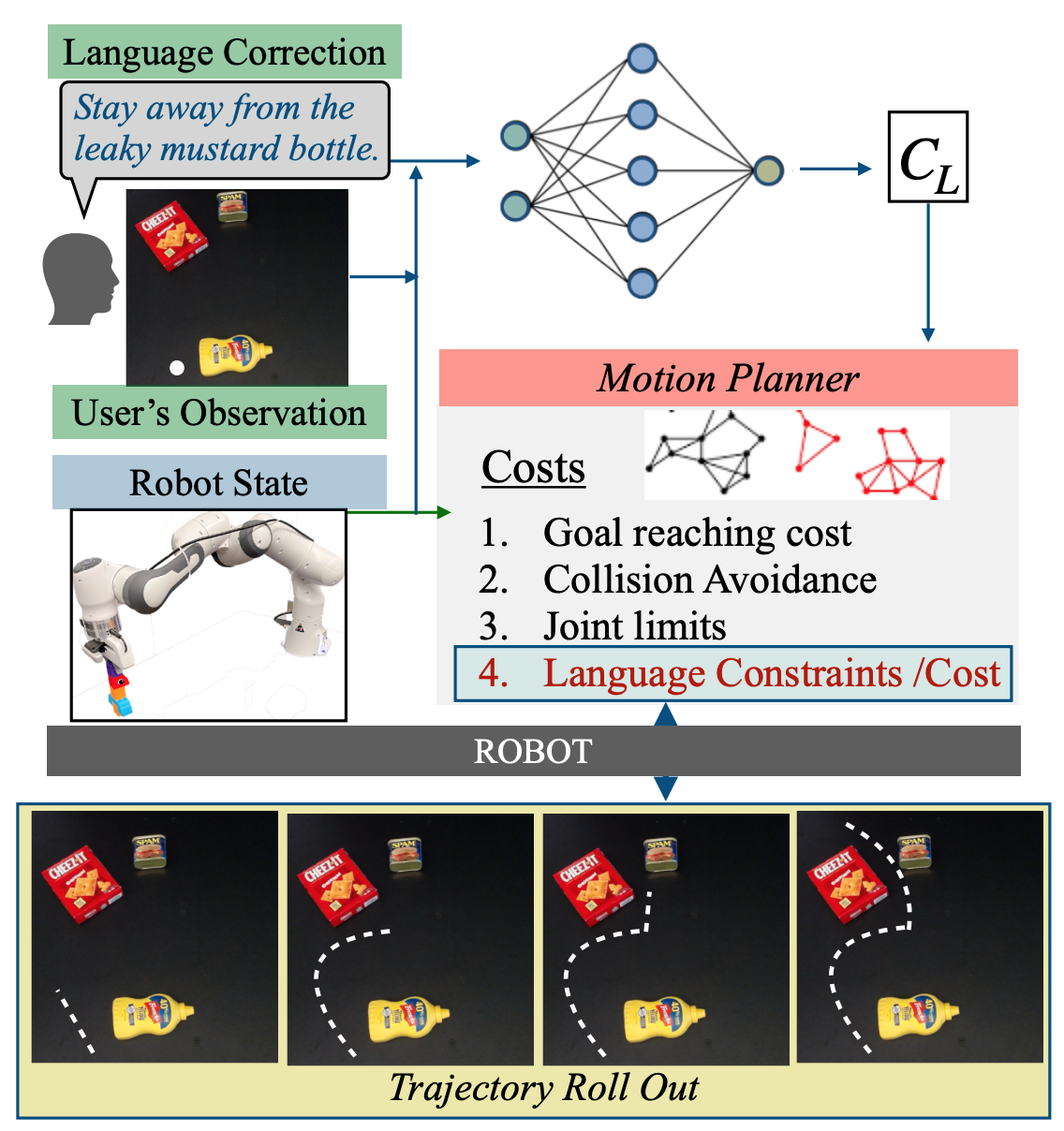
Correcting Robot Plans with Natural Language Feedback (RSS 2022) Pratyusha Sharma, Balakumar Sundaralingam, Valts Blukis, Chris Paxton, Tucker Hermans, Antonio Torralba, Jacob Andreas, Dieter Fox
In this paper, we explore natural language as an expressive and flexible tool for robot correction. We describe how to map from natural language sentences to transformations of cost functions. We show that these transformations enable users to correct goals, update robot motions to accommodate additional user preferences, and recover from planning errors. These corrections can be leveraged to get 81% and 93% success rates on tasks where the original planner failed, with either one or two language corrections. Our method makes it possible to compose multiple constraints and generalizes to unseen scenes, objects, and sentences in simulated environments and real-world environments. [Website] [PDF] [Bibtex]
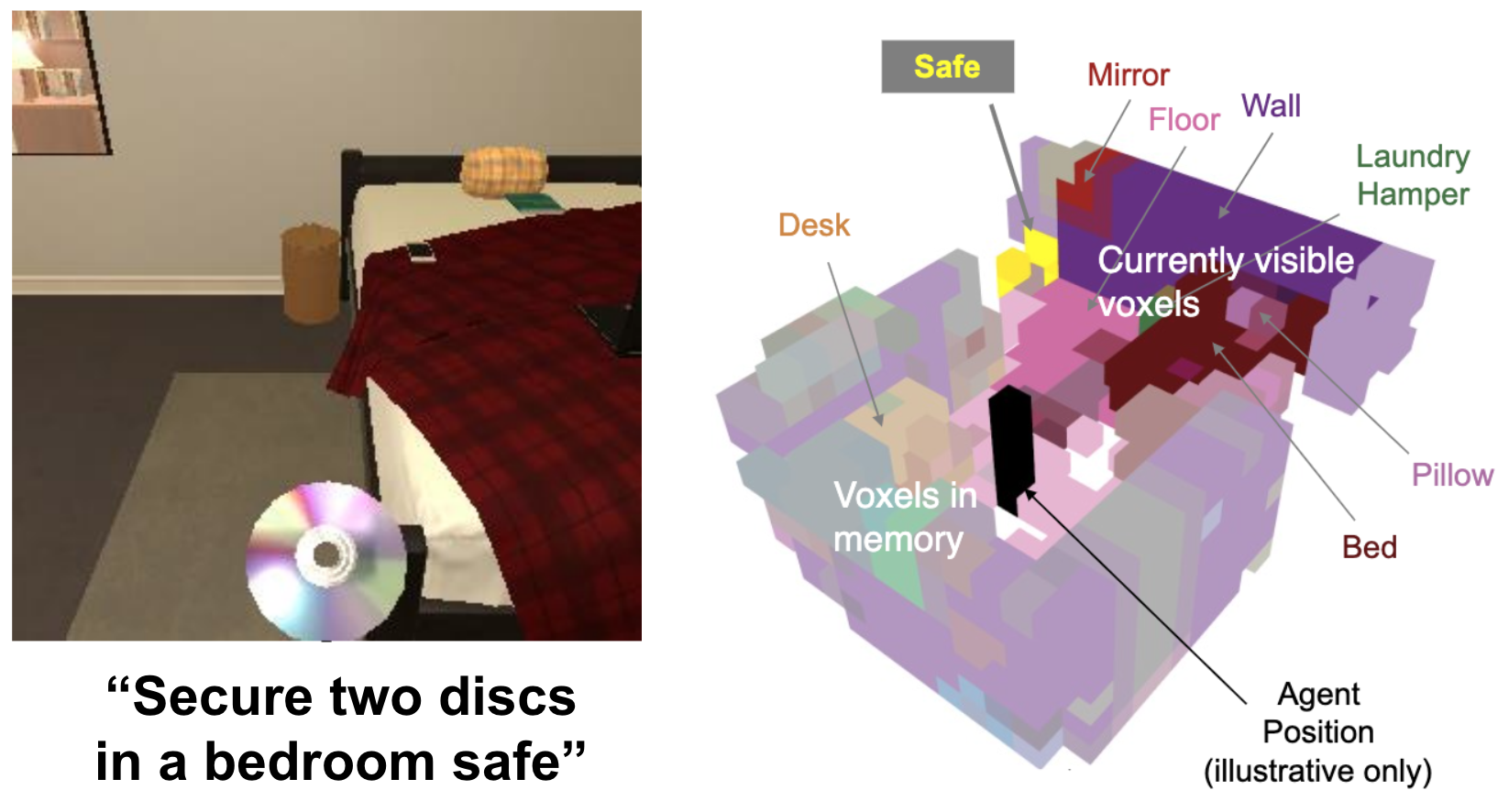
A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution (CoRL 2021) Valts Blukis, Chris Paxton, Dieter Fox, Animesh Garg and Yoav Artzi
Natural language provides an accessible and expressive interface to specify long-term tasks for robotic agents. However, non-experts are likely to specify such tasks with high-level instructions, which abstract over specific robot actions through several layers of abstraction. We propose that key to bridging this gap between language and robot actions over long execution horizons are persistent representations. We propose a persistent spatial semantic representation method, and show how it enables building an agent (HLSM) that performs hierarchical reasoning to effectively execute long-term tasks. We evaluate our approach on the ALFRED benchmark and achieve state-of-the-art results, despite completely avoiding the commonly used step-by-step instructions. [Website] [PDF] [Bibtex]
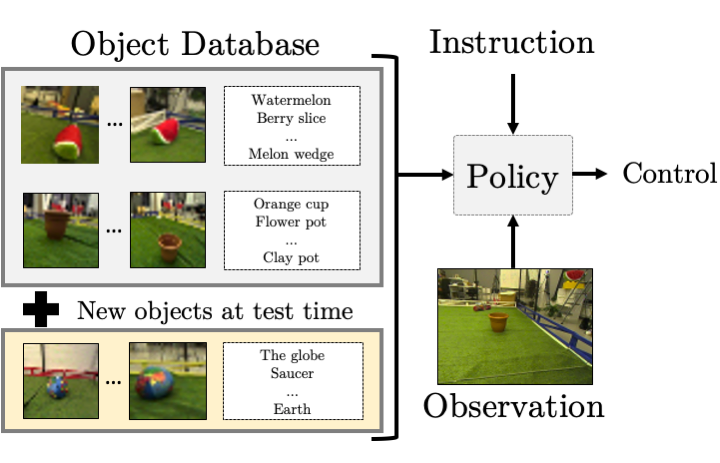
Few-shot Object Grounding for Mapping Natural Language Instructions to Robot Control (CoRL 2020) Valts Blukis, Ross A. Knepper and Yoav Artzi
We propose an approach for extending a representation learning instruction following model to reason about new previously unseen objects without any re-training or design changes. Our approach explicitly models alignments between objects in the environment and references in the instruction. We treat the alignment as a few-shot learning task that uses a database of exemplars, and show how to extend the system's reasoning by adding entries to the database. We demonstrate the approach on a physical quadcopter task of mapping raw observations and instructions to continuous control. [PDF] [Bibtex]

Learning to Map Natural Language Instructions to Physical Quadcopter Control using Simulated Flight (CoRL 2019) Valts Blukis, Yannick Terme, Eyvind Niklasson, Ross A. Knepper and Yoav Artzi
We present a physical quadcopter system that follows natural language navigation instructions by mapping raw first-person camera images and pose estimates to control velocities. We address partial observability by learning language-directed exploration. We introduce the SuReAL algorithm that simultaneously performs supervised and reinforcement learning on different parts of a neural network model to achieve good sample complexity and robustness to errors. We use a domain-adverasrial loss to train on real-world and simulation data, without any real-world flight during training. [PDF] [Bibtex] [Poster] [YouTube Demo]

Mapping Navigation Instructions to Continuous Control Actions with Position-Visitation Prediction (CoRL 2018) Valts Blukis, Dipendra Misra, Ross A. Knepper and Yoav Artzi
We present a 2-stage approach to following natural language navigation instructions on a realistic simulated quadcopter by mapping first-person images to actions. In the first planning stage, we learn perception, language understanding, and language grounding by predicting where the quadcopter should fly. In the second execution stage, we learn control using imitation learning. The model outperforms prior methods and uses the differentiable mapping system from GSMN (two projects below). [PDF] [Bibtex] [YouTube Demo]

Mapping Instructions to Actions in 3D Environments with Visual Goal Prediction (EMNLP 2018) Dipendra Misra, Andrew Bennett, Valts Blukis, Max Shatkhin, Eyvind Niklasson and Yoav Artzi
We propose a single model approach for instruction following, which decouples the problem into predicting the goal location using visual observations and taking actions to accomplish it. We propose a new model for visual goal prediction and introduce two large scale instruction following datasets involving navigation in an open 3D space and performing navigation and simple manipulation in a 3D house. [PDF] [arXiv] [Bibtex]

Following High-Level Navigation Instructions on a Simulated Quadcopter with Imitation Learning (RSS 2018) Valts Blukis, Nataly Brukhim, Andrew Bennett, Ross A. Knepper and Yoav Artzi
We present the Grounded Semantic Mapping Network (GSMN) that embeds a differentiable mapping system within a neural network model. It accumulates a learned, internal map of the environment and uses this map to solve a navigation instruction following task by mapping directly from first-person camera images to velocity commands. The mapper works by projecting learned image features from the first-person view to the map reference frame, allowing our model to outperform traditional end-to-end neural architectures. [PDF] [arXiv] [Poster] [Slides] [Bibtex]
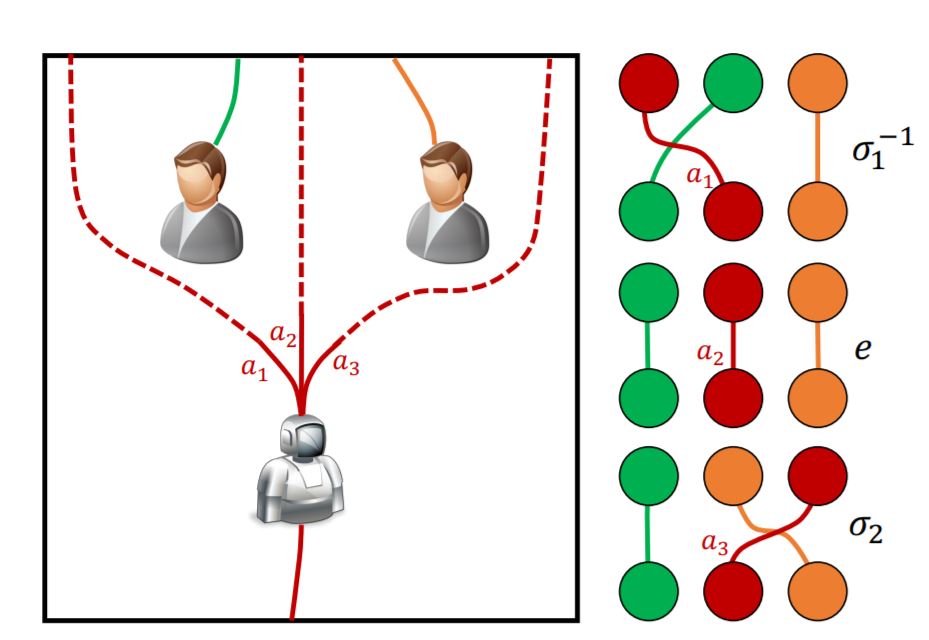
Socially Competent Navigation Planning by Deep Learning of Multi-Agent Path Topologies (IROS 2017) Christoforos I. Mavrogiannis, Valts Blukis and Ross A. Knepper
If we can anticipate how pedestrians around us will act, we can efficiently navigate around them. We behave in a legible way by minimzing the uncertainty (entropy) of the distribution over future pedestrian trajectory topologies and thus avoiding confusing behavior. Topologies are defined using braid theory and predicted with a seq2seq model. [PDF] [Bibtex]
ROBOTICS PROJECTS
Waiterbot (1st Runner-up, Tech Factor Challenge 2014-2015)
Waiterbot is a hand-built prototype for a fully featured restaurant robot. We built it in a team of 4 enthusiasts (Azfer Karim, Jagapriyan, Mohamed Musadhiq and me) for the 2014-2015 Tech Factor Challenge competition in Singapore. It can navigate from table to table, pick up and deliver orders and even serve water. It uses a custom-built gripper to pick up cups, bowls and plates (although it struggles with crockery).
Battlefield Extraction Robot (Grand Prize, Tech Factor Challenge 2013-2014)
ABER (Autonomous Battlefield Extraction Robot) is a rescue robot that can automatically find and pick up a casualty in a war or disaster scenario, where limited remote operation is possible. It's built on ROS and uses a unique conveyor-belt pickup system that inflicts minimum damage in case of bone fractures. Received DSTA Gold Medal for best final-year project in NTU, School of Electrical and Electronic Engineering.