Preventing Glitches and Short Circuits in High-Level Self-Timed Chip Specifications
Artifact
Stephen Longfield, Brittany Nkounkou, Rajit Manohar, and Ross Tate
Artifacts: Inferable Effect System Implementation and Semantics Equivalence Mechanical Proof
We present two artifacts that accompany our paper. The first is our implementation of the inferable effect system described in Section 4 which was used to produce the results presented in Section 6. The second is our mechanical proof of the semantics equivalence theorem stated in Section 3.3 of the paper. We have created a VirtualBox VM (username "osboxes", password "pldi2015") containing both of these artifacts, including all source files and all tools necessary to run them. Should one want to run the files on another machine, we also have the Inferable Effect System Implementation source files and the Semantics Equivalence Mechanical Proof source files available separately. Included in the Proof source files is a Proof Guide, which details the correspondence between the semantics definitions in the paper and the relative constructs in the proof source code. Please find instructions on how to run both artifacts below. Note that these instructions are also included in a README in each of the source file folders.
Inferable Effect System Implementation
If using the VM, the source files for the effect system implementation can be found in the "Implementation" folder which is on the Desktop.
With a command-line terminal navigated to the source file folder, the artifact can be run as follows:
How to use the tools
Requirements:
- Python 2.7.x -- http://www.python.org
- Python Packages: recordtype, ply, psutil -- http://pypi.python.org/pypi
Note: Our system is configured to measure Memory Usage in Linux. To do so in Windows, lines 923 and 924 of chp_machine.py should be respectively commented and uncommented. For other OSes, refer to http://pythonhosted.org//psutil/#psutil.Process.memory_info_ex
To run the analysis as described in the paper, on the 10 stage fifo:
python ./chp_machine.py < Examples/fifo10.chp
The input file is a CHP specification, using the CHP language as described in the paper (note that this version of the CHP language is a somewhat simplified version that doesn't support including other files, instantiation of modules, array accesses, etc.)
The output is three things, output directly to STDIO:
- The size of the Naive NFA
- The final NFA effect, in the format for Graphviz dot.
- Note that in some cases, this will only be a single dot. This indicates that the effect has no externally visible components, and does not contain any errors.
- A report, detailing:
- The number of unique states seen while running the analysis
- The maximum intermediate #of nodes in the NFA
- The size, which is the number of non-idle edges, in the final NFA
- The amount of memory used, in KB, as measured by psutil
How to compare to SPIN
Requirements:
- Bison 3.0.2 -- http://www.gnu.org/software/bison
- SPIN 6.3.2 -- http://spinroot.com/
First, the CHP specification needs to be translated into Promela, the input language of
SPIN, the environment needs to be set up (as SPIN only accepts closed systems, as opposed
to our analysis, which accepts open systems), and the claims we are verifying need to be
communicated to SPIN. All of this is done using "chp_promela.py". For example:
python ./chp_promela.py Examples/fifo10.chp fifo10.pml
When prompted for channel types while converting the GPS acquisition, indicate that both MAG and C1023 are Bool. For the microprocessor, indicate that channel DMEM has type Int and its maximum value is 10.
SPIN then needs to build the model for anaylsis. This is a separate step before analysis,
where many of the reductions are done. This is done using the spin executable. For example:
spin -a fifo10.pml
This generates the source files for the model, along with some log files. By default, these
are written to pan.[b|c|h|m|p|t]
To run the SPIN analysis, this then needs to be compiled. Compiler flags are used to limit the maximum memory size (given in MB). For example:
cc -DMEMLIM=500000 -o pan pan.c
We set DMEMLIM to 500000 (500 GB) for all examples.
It is also possible to turn off partial order reduction from these compiler options. For example:
cc -DMEMLIM=500000 -DNOREDUCE -o pan pan.c
We did not set DNOREDUCE in any of the runs reported in the paper.
Note that, for some large models, it isn't possible to fit the state vector into SPIN's
default state vector size (1028 bits), and the state vector size has to be increased. For example:
cc -DMEMLIM=500000 -DNOREDUCE -DVECTORZ=2048 -o pan pan.c
We set DVECTORZ to 2048 for the microprocessor and 100-stage fifo, using the default value for all other examples.
After the model has been compiled, run the program to see the result of the analysis. To
ensure that the entire space is explored, we set the maximum search depth to 1,000,000
instead of the default 10,000. In cases where this limit is reached (e.g., the larger FIFOs), the depth should be increased further until the full space is searched:
./pan -m1000000
SPIN then outputs a report on any errors found, as well as how much memory was used
to run the analysis, and how much time it took. The time reported in the paper is the
summation of all the steps (model build time, model compile time, and model run time).
Examples from the paper
The Examples directory contains the examples, which have their own readme to give some additional details on what is contained within each example. The examples that were used as benchmarks in the paper are as follows:
- GPS Acquisition: gps_acq.chp
- Microprocessor : micro_arch.chp
- FIFO, 10 Stage : fifo10.chp
- FIFO, 50 Stage : fifo50.chp
- FIFO, 100 Stage: fifo100.chp
- Arbitration, 5 : arb5.chp
- Arbitration, 10: arb10.chp
- Arbitration, 20: arb20.chp
- Token-ring, 5 : token5.chp
- Token-ring, 7 : token7.chp
- Token-ring, 10 : token10.chp
Semantics Equivalence Mechanical Proof
If using the VM, the source files for the semantics equivalence proof can be found in the "Proof" folder which is on the Desktop.
With a command-line terminal navigated to the source file folder, the artifact can be run as follows:
How to mechanically verify the proof
Requirements:
- The Coq Proof Assistant 8.4pl3 -- http://coq.inria.fr/
To compile a coq source file, for example "SemanticsBase.v", one simply executes:
coqc SemanticsBase.v
after which "SemanticsBase.glob" and "SemanticsBase.vo" will be generated in the same folder. The former contains an enumeration of the source's global constructs (for documentation purposes), and the latter contains the complete compiled library of the source. The source file will only successfully compile if its constructs can be successfully type-checked by Coq, which implies that the Propositions/Types declared in the file have been correctly proven/inhabited.
Our Coq proof is split up into 17 different source files, which must be compiled in the order of their logical dependence. Below, we provide a visual overview of those dependencies, along with a high-level description of each file.
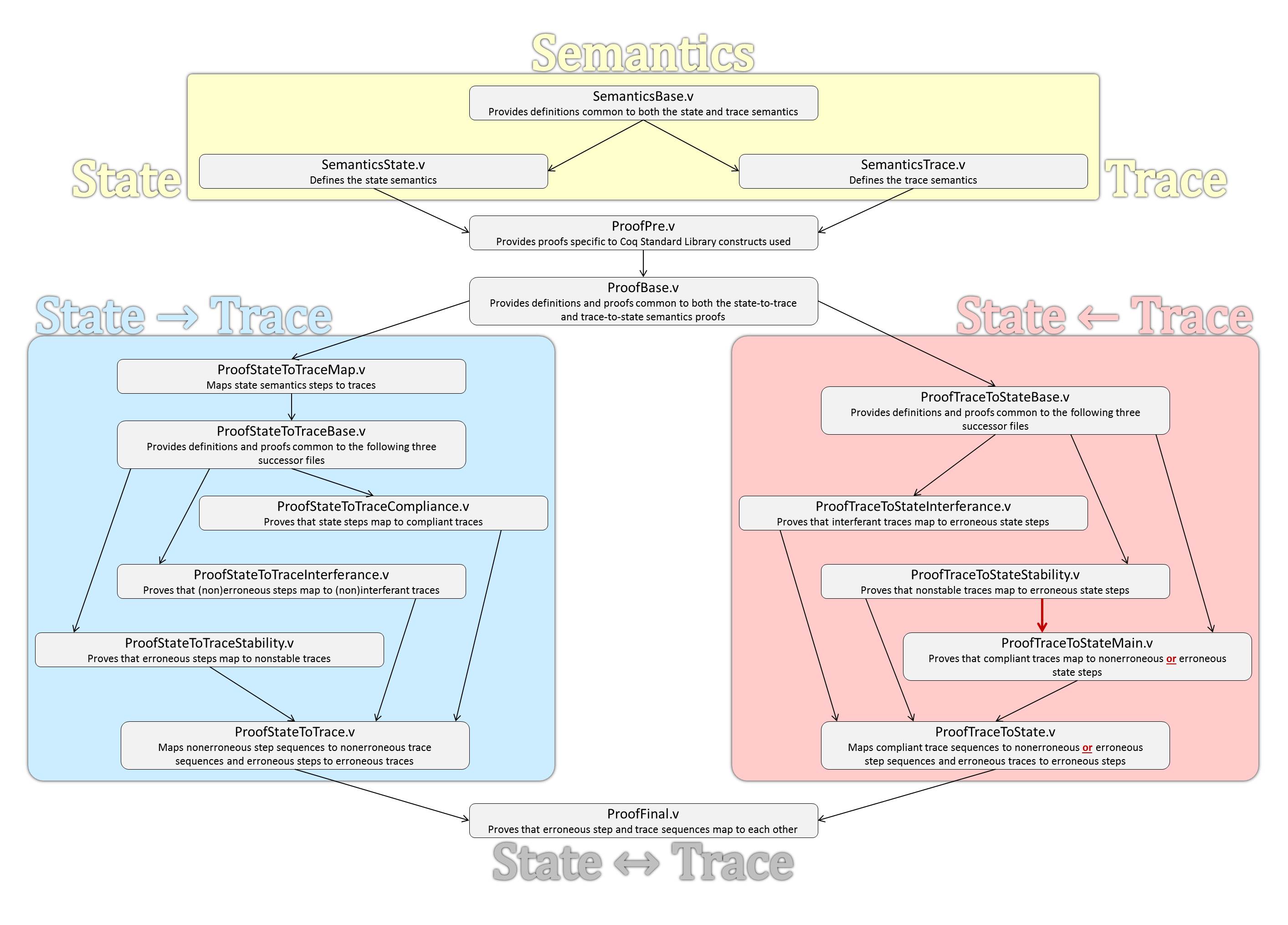
The provided Makefile performs this compilation procedure in its entirety. Upon compiling the last file, "ProofFinal.v", Coq will output the following:
Axioms:
Channel : Type
eq_Channel_dec : forall c1 c2 : Channel, {c1 = c2} + {c1 <> c2}
This output is a result of the last line in "ProofFinal.v", which reads:
Print Assumptions BigErrorStep_iff_BigErrorTrace.
This query prints all assumptions made in the construction of "BigErrorStep_iff_BigErrorTrace", whose definition completes the proof (as explained in the Proof Guide). Thus, the result of this query tells us that the only assumptions made in the entire proof system were that of a "Channel" type, and decidable equality within that type. For more information on the internal structure of the proof, we refer the reader to the provided Proof Guide.