Richard Lanas Phillips
Researcher | Data Scientist

Researcher | Data Scientist
My research interests are in the ways we collect data and apply models across populations, especially as related to public health and scientific discovery. How should we apply models to groups with different needs and data sources? How can we make models respond well to shifts in underlying populations? How can machine learning help us make meaningful comparisons with respect to systematic risks? I'm currently working on tools to optimize robust models over highly structured (and often messy) data, increase algorithmic transparency, and to improve active sampling and dataset engineering.
I’m affiliated with the Center for the Study of Inequality, supported by a fellowship from the Canadian health informatics group IC/ES, and lead the MD4SG working group on discrimination and inequity.

I’m collaborating with Madeleine Udell and Laura C. Rosella to develop machine learning segmentation approaches for multi-scale data collected from all Ontarians over time. By rigorously testing existing and new analytic approaches to segmentation and studying the impact in a decision-making organization, there becomes an opportunity to better use population level data to inform health system planning and management. This project combines individual-scale health data from billing services, prescription information, survey responses, immigration and other demographic information, lab results, and more from over 15 million people.
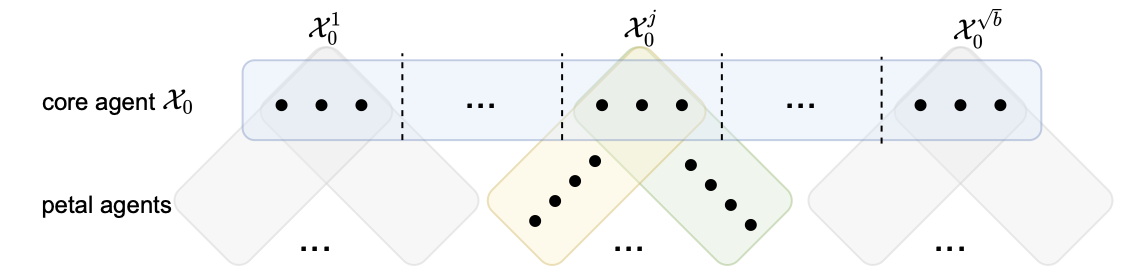
We study fundamental issues related to equity and collaborative incentive in federated learning. Rather than assuming that one benefits from learning over as much data as possible, we consider what burdens individual populations should shoulder given their performance demands and the structure of their data as related to other collaborators. We build models for PAC learning, random sampling, and resource sharing and compare these; we consider the existence of equilibria, feasibility, and lower bounds for the gap between global optimality and optimality under incentive constraints.
I studied several datasets on the WILDS team. We looked for the existence of problematic covariate shift in real-world datasets in different domains. The initial release of the data contains 7 bechmark datasets with specified domains, metrics, and baselines. Across the project, however, many other datasets were also explored. For my contribution, I studied covariate shift through issues of fairness and geography in several algorithmic fairness-related datasets.
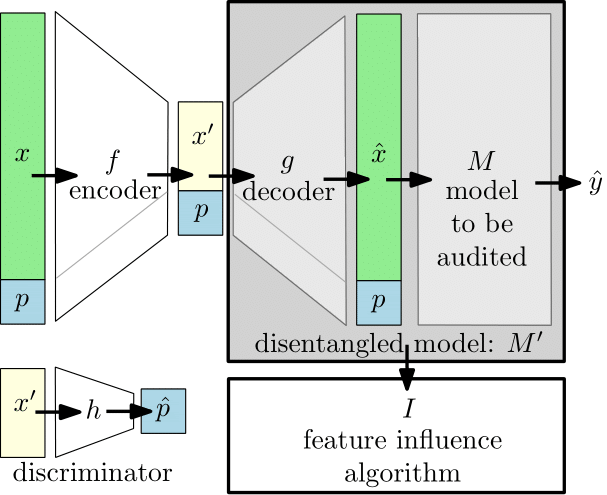
We showed how disentangled representations might be used for auditing. This is useful for finding proxy features and searching for potential introduction of bias in correlated features. Our solution allowed for the explicit computation of feature influence on either individual or aggregate-level outcomes.
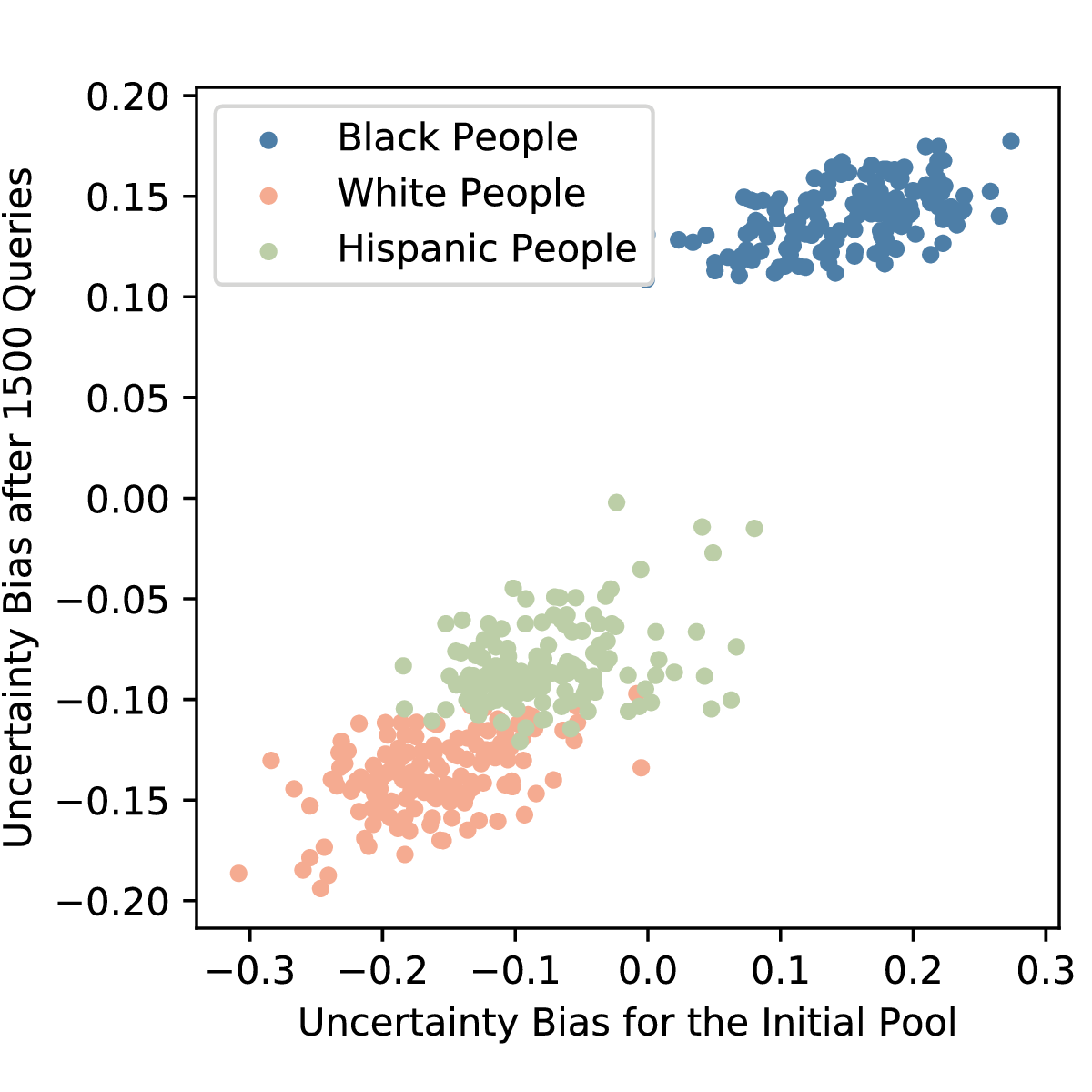
This project proposed a way we might explain why active learning queries are being suggested to a domain expert. We built this to help batch active learning queries in a way that let chemists design natural experiments. We also explored some auditing and fairness applications of the proposed framework.

At Haverford College, I worked on the Dark Reaction Project team. The goal of this project was to take thousands of unused, "failed" reactions and leverage them into a machine learning model. This was successful in speeding up exploration and the system helped expose human biases in the exploratory synthesis pipeline.