Fig. 1
The question underlying this debate is how our scientific research communications infrastructure should be reconfigured to take maximal advantage of newly evolving electronic resources. Rather than "electronic publishing" which connotes a rather straightforward cloning of the paper methodology to the electronic network, many researchers would prefer to see the new technology lead to some form of global "knowledge network", and sooner rather than later.
Some of the possibilities offered by a unified global archive are suggested by the Los Alamos e-print arXiv (where "e-print" denotes self-archiving by the author), which since its inception in 1991 has become a major forum for dissemination of results in physics and mathematics. These e-print archives are entirely scientist driven, and are flexible enough either to co-exist with the pre-existing publication system, or to help it evolve to something better optimized for researcher needs. The arXiv is an example of a service created by a group of specialists for their own use: when researchers or professionals create such services, the results often differ markedly from the services provided by publishers and libraries. It is also important to note that the rapid dissemination they provide is not in the least inconsistent with concurrent or post facto peer review, and in the long run offer a possible framework for a more functional archival structuring of the literature than is provided by current peer review processes.
As argued by Odlyzko [1], the current methodology of research dissemination and validation is premised on a paper medium that was difficult to produce, difficult to distribute, difficult to archive, and difficult to duplicate -- a medium that hence required numerous local redistribution points in the form of research libraries. The electronic medium is opposite in each of the above regards, and, hence, if we were to start from scratch today to design a quality-controlled distribution system for research findings, it would likely take a very different form both from the current system and from the electronic clone it would spawn without more constructive input from the research community.
Reinforcing the need to reconsider the above methodology is that each article typically costs many tens of thousands of dollars minimum in salary, and much more in equipment, overhead, etc. A key point of the electronic communication medium is that for a minuscule additional fraction of this amount, it's possible to archive the article and make it freely available to the entire world in perpetuity. This is, moreover, consistent with public policy goals [2] for what is in large part publicly funded research. The nine-year lesson so far from the Los Alamos archives is that this additional cost, including the global mirror network, can be as little as a dollar per article, and there is no indication that maintenance of the archival portion of the database will require an increasing fraction of the time, cost, or effort.
Odlyzko [1] has also pointed out that average aggregate publisher revenues are roughly $4000/article, and that since acquisition costs are typically 1/3 of library budgets, the current system expends an additional $8000/article in other library costs. Of course, some of the publisher revenues are necessary to organize the peer review, though the latter depends on the donated time and energy of the research community, and is subsidized by the same grant funds and institutions that sponsor the research in the first place. The question crystallized by the new communications medium is whether this arrangement remains the most efficient way to organize the review and certification functions, or if the dissemination and authentication systems can be naturally disentangled to create a more forward-looking research communications infrastructure.
Fig. 1
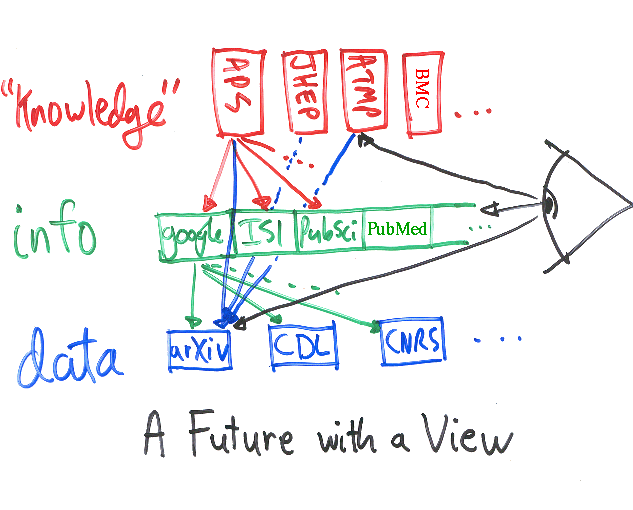
The figure (Fig. 1) is meant to illustrate one such possible hierarchical structuring of our research communications infrastructure. At left it depicts three electronic service layers, and at right the eyeball of the interested reader/researcher is given the choice of most auspicious access method for navigating the electronic literature. The three layers, depicted in blue, green, and red, are respectively the data, information, and "knowledge" networks (where "information" is usually taken to mean data + metadata [i.e. descriptive data], and "knowledge" here signifies information + synthesis [i.e. additional synthesizing information]). The figure also represents graphically the key possibility of disentangling and decoupling the production and dissemination on the one hand from the quality control and validation on the other (as was not possible in the paper realm).
At the data level, the Figure suggests a small number of potentially representative providers, including the Los Alamos e-print arXiv (and implicitly its international mirror network), a university library system (CDL = California Digital Library), and a typical foreign funding agency (the French CNRS = Centre National de Recherche Scientifique). These are intended to convey the likely importance of library and international components. Note that there already exist cooperative agreements with each of these to coordinate via the "open archives" protocols (http://www.openarchives.org/) to facilitate aggregate distributed collections.
Representing the information level, the Figure shows a generic public search engine (Google), a generic commercial indexer (ISI = Institute for Scientific Information), and a generic government resource (the PubScience initiative at the DOE), suggesting a mixture of free, commercial, and publicly funded resources at this level. For the biomedical audience at hand, I might have included services like Chemical Abstracts and PubMed at this level. A service such as GenBank is a hybrid in this setting, with components at both the data and information layers. The proposed role of PubMedCentral would be to fill the electronic gaps in the data layer highlighted by the more complete PubMed metadata.
At the "knowledge" layer, the Figure shows a tiny set of existing Physics publishers (APS = American Physical Society, JHEP = Journal of High Energy Physics, and ATMP = Applied and Theoretical Mathematical Physics; the second is based in Italy and the third already uses the arXiv entirely for its electronic dissemination); and BMC (= BioMedCentral) should also have been included at this level. These are the third parties that can overlay additional synthesizing information on top of the information and data levels, and partition the information into sectors according to subject area, overall importance, quality of research, degree of pedagogy, interdisciplinarity, or other useful criteria; and can maintain other useful retrospective resources (such as suggesting a minimal path through the literature to understand a given article, and suggesting pointers to outstanding lines of research later spawned by it). The synthesizing information in the knowledge layer is the glue that assembles the building blocks from the lower layers into a knowledge structure more accessible to both experts and non-experts.
The three layers depicted are multiply interconnected. The green arrows indicate that the information layer can harvest and index metadata from the data layer to generate an aggregation which can in turn span more than one particular archive or discipline. The red arrows suggest that the knowledge layer points to useful resources in the information layer. As mentioned above, the knowledge layer in principle provides much more information than that contained in just the author-provided "data": e.g. retrospective commentaries, etc. The blue arrows -- critical here -- represent how journals of the future can exist in an "overlay" form, i.e. as a set of pointers to selected entries at the data level. Abstracted, that is the current primary role of journals: to select and certify specific subsets of the literature for the benefit of the reader. A heterodox point that arises in this model is that a given article at the data level can be pointed to by multiple such virtual journals, insofar as they're trying to provide a useful guide to the reader. (Such multiple appearance would no longer waste space on library shelves, nor be viewed as dishonest.) This could tend to reduce the overall article flux and any tendency on the part of authors towards "least publishable units". The future author could thereby be promoted on the basis of quality rather than quantity: instead of 25 articles on a given subject, the author can point to a single critical article that "appears" in 25 different journals.
Finally, the black arrows suggest how the reader might best proceed for any given application: either trolling for gems directly from the data level (as many graduate students are occasionally wont, hoping to find a key insight missed by the mainstream), or instead beginning the quest at the information or knowledge levels, in order to benefit from some form of pre-filtering or other pre-organization. The reader most in need of a structured guide would turn directly to the highest level of "value-added" provided by the "knowledge" network. This is where capitalism should return to the fore: researchers can and should be willing to pay a fair market value for services provided at the information or knowledge levels that facilitate and enhance the research experience. For reasons detailed above, however, we expect that access at the raw data level can be provided without charge to readers. In the future this raw access can be further assisted not only by full text search engines but also by automatically generated reference and citation linking. The experience from the Physics e-print archives is that this raw access is extremely useful to research, and the small admixture of noise from an unrefereed sector has not constituted a major problem. (Research in science has certain well-defined checks and balances, and is ordinarily pursued by certain well-defined communities.)
Ultimately, issues regarding the correct configuration of electronic research infrastructure will be decided experimentally, and it will be edifying to watch the evolving roles of the current participants. Some remain very attached to the status quo, as evidenced by responses to successive forms of the PubMedCentral proposal from professional societies and other agencies, ostensibly acting on behalf of researchers but sometimes disappointingly unable to recognize or consider potential benefits to them. (Media accounts have been equally telling and disappointing in giving more attention to the "controversy" between opposing viewpoints than to a substantive accounting of the proposed benefits to researchers, and to taxpayers.) It is also useful to bear in mind that much of the entrenched current methodology is largely a post World War II construct, including both the largescale entry of commercial publishers and the widespread use of peer review for mass production quality control (neither necessary to, nor a guarantee of, good science). Ironically, the new technology may allow the traditional players from a century ago, namely the professional societies and institutional libraries, to return to their dominant role in support of the research enterprise.
The original objective of the Los Alamos archives was to provide functionality that was not otherwise available, and to provide a level playing field for researchers at different academic levels and different geographic locations -- the dramatic reduction in cost of dissemination came as an unexpected bonus. (The typical researcher is entirely unaware and sometimes quite upset to learn that the average article generates a few thousand dollars in publisher revenues.) As Andy Grove of Intel has pointed out [3], when a critical business element is changed by a factor of 10, it is necessary to rethink the entire enterprise. The Los Alamos e-print archives suggest that dissemination costs can be lowered by more than two orders of magnitude, not just one.
But regardless of how different research areas move into the future (perhaps by some parallel and ultimately convergent evolutionary paths), and independent of whether they also employ "pre-refereed" sectors in their data space, on the one- to two-decade time scale it is likely that other research communities will also have moved to some form of global unified archive system without the current partitioning and access restrictions familiar from the paper medium, for the simple reason that it is the best way to communicate knowledge and hence to create new knowledge.
[1] A. Odlyzko, "Tragic loss or good riddance? The impending
demise of traditional scholarly journals," Intern. J. Human-Computer Studies
(formerly Intern. J. Man-Machine Studies) 42 (1995), pp. 71-122, and in the
electronic J. Univ. Comp. Sci., pilot issue, 1994.
A. Odlyzko, "Competition and cooperation: Libraries and publishers in the
transition to electronic scholarly journals,"
Journal of Electronic
Publishing 4(4) (June 1999), and in
J. Scholarly Publishing 30(4) (July 1999), pp. 163-185.
Articles also available at
http://www.research.att.com/~amo/doc/eworld.html.
[2] S. Bachrach et al., "Who Should 'Own' Scientific Papers?",
Science, Volume 281, Number 5382, Issue of 4 Sep 1998,
pp. 1459-1460.
See also "Bits of Power: Issues in Global Access to Scientific Data",
by the Committee on Issues in the Transborder Flow of Scientific Data;
U.S. National Committee for CODATA; Commission on Physical Sciences,
Mathematics, and Applications; and the National Research Council;
National Academy Press (1997).
[3] Andy Grove, "Only the Paranoid Survive: How to Exploit the Crisis
Points That Challenge Every Company and Career," Bantam Doubleday Dell, 1996
(as cited in A. Odlyzko, "The economics of electronic journals"
First Monday 2(8) (August 1997), and
Journal of Electronic Publishing
4(1) (September 1998). Definitive version on pp. 380-393 in
Technology and Scholarly Communication, R. Ekman and R. E. Quandt, eds.,
Univ. Calif. Press, 1999.)