Learning to Match Images in Large-Scale Collections
Abstract
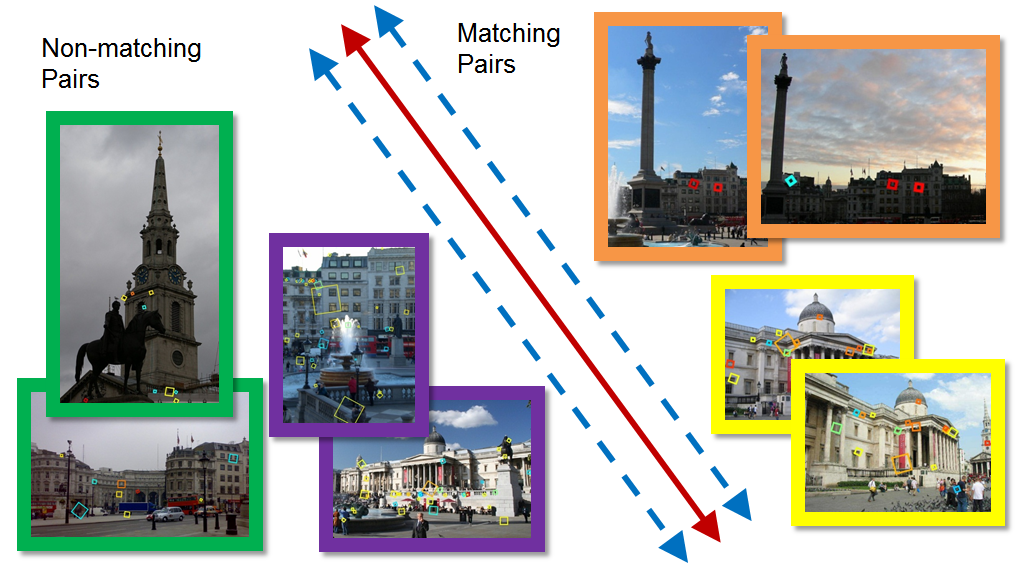
Many computer vision applications require computing structure and
feature correspondence across a large, unorganized image collection. This is a
computationally expensive process, because the graph of matching image pairs is
unknown in advance, and so methods for quickly and accurately predicting which
of the O(n2) pairs of images match are critical. Image
comparison methods such as bag-of-words models or global features are often
used to predict similar pairs, but can be very noisy. In this paper, we propose
a new image matching method that uses discriminative learning
techniques—applied to training data gathered automatically during the image
matching process—to gradually compute a better similarity measure for
predicting whether two images in a given collection overlap. By using such a
learned similarity measure, our algorithm can select image pairs that are more
likely to match for performing further feature matching and geometric
verification, improving the overall efficiency of the matching process. Our
approach processes a set of images in an iterative manner, alternately perform-
ing pairwise feature matching and learning an improved similarity measure. Our
experiments show that our learned measures can significantly improve match
prediction over the standard tf-idf weighted similarity and more recent
unsupervised techniques even with small amounts of training data, and can
improve the overall speed of the image matching process by more than a factor
of two.
Paper - ECCV 2012 Workshop on Web-scale Vision and Social Media
|
Slides (coming soon) |
Datasets
Coming soon.
Acknowledgements
This work was supported in part by the NSF (grants IIS-0713185 and
IIS-1111534), Intel Corporation. We also thank Flickr users for use of
their photos.