![]()
![]()
![]()

|
|
|
|
Computational Resource - Status Q4 1998We are currently using an early release of Cluster CoNTroller, an NT Job Scheduling and Resource Management system developed at the Cornell Theory Center and now licensed and sold by MPI Software Technology, Inc. This system allows users to submit both parallel and serial programs to be executed either in batch mode or interactively. Cluster CoNTroller Cluster administrators to specify node features that users may want to request, for example, the amount of memory, the processor type, clock speed, special software, network interfaces or any other description. This has proven to be very useful since we received two shipments of cluster nodes for the grant. The first set were 300 Mhz Pentium IIs with 256 megabytes of memory. The second set were 400 Mhz Pentium IIs with 512 megabytes of memory. In just the short time that we allowed early users on the system several were able to take advantage of being able to request more memory so they could run larger simulations. More recently, a great deal of effort has gone into extending Cluster CoNTroller to be able to schedule and manage distributed cluster resources. Our first step was to incorporate nodes from the computational biology cluster into the CTC cluster NT domain across the Campus network. This went extremely well and we were able to run jobs seamlessly across campus. Our next attempt was to tie in workstations in the CTC desktop NT domain to the cluster when they were not in use. To do this we had to experiment with NT trust relationships. This led to several interesting discoveries. On our cluster nodes we run NT server and on our desktops NT workstation. NT Workstation would not start jobs for a given user on a workstation if they were already logged in at that workstation. Another problem was that NT allows you to enumerate processes belonging to a particular user but there is no obvious way to differentiate which session each process was started in. For example, was the process started by the user at the console or by the scheduled job in the background? This makes cleaning up stray processes after a job completes very difficult in this environment. The NT trust relationship between the desktop domain and the cluster domain did work very well. This greatly simplifies administration since user databases do not have to be exchanged to share resources across NT domains. Our next step was to look at using trust relationships to build a large distributed NT cluster with several different NT domains involved. We quickly found that having everyone trust everyone was not going to scale. We came up with a scheme that we call a common domain. In this method there is a central domain that is adminstered by committee. That is to say the administrator participating in the distributed cluster can add or deny usage to the entire distributed resource via the common domain. Anyone who wishes to participate then sets up a trust relationship with the common domain. Our goal is to test the scalability of this solution this year and possibly extend it to have multiple common domains with distributed clusters "trust" each other. We have also spent a great deal of time on usability issues. We found that the NT programming paradigm does not lend itself to UNIX style programming where one normally telnets into a remote machine, edits code, runs make, and then submits a batch job to run their code. Using a telnet interface in NT greatly reduces the capabilities that a user has at their disposal when logged in at the console. In an attempt to make cluster access fit the NT paradigm better we developed a drag-and-drop Cluster CoNTroller interface. Cluster users now see a "Cluster" icon on their desktop similar to "My Computer" and "Network Neighborhood". To submit a job all a user needs to do is drag their exe or bat file to the cluster icon and the job is submitted. Double clicking the icon opens a window and allows a user to see the job queue and A resource map showing them which nodes are allocated to different jobs. Another ongoing effort has been porting user applications and running benchmarks for performance testing with real codes. This has been relatively successful this far but there is definitely a learning curve to overcome for many researchers who are used to the UNIX environment. The CTC cluster user community is starting to grow. Here are a few short descriptions of current users and how the Intel cluster has benefited them. Jun Xu, Mechanical and Aerospace Engineering Probability density function (PDF) methods are advanced approaches to model turbulent combustion process encountered in engineering design, for example, the design of combustors in gas-turbine engines. These methods in combination with the recent developed In Situ Adaptive Tabulation algorithm by Professor S.B. Pope can model the interaction of turbulence and chemical reactions, and therefore the phenomenon very accurately. The tradeoff, however, is that the demand of computer power by these methods is bigger than traditional methods. A parallel method, namely particle partitioning, is adopted to parallelize the PDF code developed at Cornell (i.e., PDF2DV) using MPI library. Making the use of Intel Cluster of CTC to run parallel job of PDF2DV can significant accelerate the research pace, especially if a fast switch for message passing were available. Matthew Kuntz, Physics Department Many magnetic materials, when they are magnetized, magnetize not smoothly, but in discrete jumps (avalanches). These jumps are called "Barkhausen Noise." Experiments have shown that these jumps come in all sizes with a power law distribution of sizes. Such power law distributions of "avalanches" have also been found in many disordered systems. We have been using simulations to study a simple lattice model of these systems. In order to understand the behavior of our model well, we have found it necessary to run very large simulations (because the interesting behavior involves avalanches over a large range of sizes), and to run many simulations (to get good statistics.) Recently, in our attempts to understand more aspects of the experimental systems, we have found it necessary to change to a more complicated model, and run much slower simulations. We have found the Intel machines in the Theory Center cluster to be very useful. Their high speed and large memory has allowed us to run the large simulations we need, and the large number of processors available has let us quickly explore many areas and to get good statistics. Juyang Huang, Biochemistry Molecular and Cell Biology I'm interesting in how cholesterol interacts with other bio-molecules on cell membranes. One way to study this is to model molecule lateral distributions using Monte Carlo simulation. My current project involves calculation of chemical potential of cholesterol in various environments which requires many repetitive, independent simulations runs. The Intel Cluster at Cornell Theory Center provides the ideal computation resource for my work. The Clusters allow me to submit many computation jobs at a time, right from my office. I found that using the Intel Cluster is easy and convenient, the machines are fast and capable. I got several fold increase in my productivity by using the Cluster. I'm very pleased with the result and the timely support I got from Theory Center staff and David Lifka. David Schneider, Cornell Theory Center I have been porting a generic framework for the concurrent execution of existing sequential applications There are numerous occasions where it is very advantageous to be able to coordinate the concurrent execution of multiple copies of an existing sequential code in a distributed computing environment. A number of years ago we developed a very flexible, generic framework for accomplishing this task which has been used for a wide variety of projects including:
These problems all share several key features. First, they are comprised of structurally similar but logically distinct subproblems that can be tackled independently using existing sequential application codes that are well tested, stable, reliable, but very computationally intensive. Second, a typical large-scale production run might involve hundreds or even thousands of separate input and output files and might involve hundreds of CPU hours. Third, practical time constraints and human errors frequently make it tedious or impractical to manually partition the input data, initiate processing on multiple independent machines, then move the output data back to a central location for post-processing. We have found that a flexible, generic framework for coordinating the concurrent execution of multiple instances of a sequential application code enables a relatively inexperienced user to exploit the full power of a distributed computing environment for improving throughput and minimizing manual processing errors on large production runs of this type. We have ported our concurrent execution framework, originally written for the IBM SP-2, to the NT cluster. The code itself is written in C++ and uses a queue-based master/worker model to do automatic load balancing where the contents of the queue are strings which may be executed by invocations of the standard system()library routine and the availability of network mapped file systems obviate the need for explicit duplication of executables, partition of input data sets, and collection of output data sets for postprocessing. The code uses calls to the Message Passing Interface (MPI) library for internode communication, but the modular structure of the framework itself makes it straightforward to use other internode communication protocols of various types (eg., low-level TCP/IP, remote procedure calls). This framework will be used on the NT cluster by several Theory Center affiliates for important production runs (USDA for computational genomics.
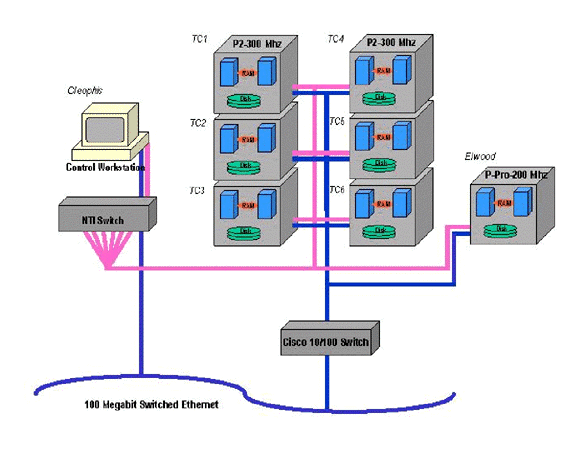
Status Q1 1998The Theory Center received six two-way SMP Pentium II machines and two two-way SMP Pentium Pros in late January 1998. In late February a Cisco 2916M-XL ethernet switch was purchased with grant funds to provide the interconnect for the cluster nodes. The Theory Center provided an NTI monitor and keyboard switch (http://www.networktechinc.com) for the NT cluster as well as a Pentium based workstation to manage the cluster from. Figure 1 shows our current cluster configuration.
Figure 1: CTC Intel Cluster Once the hardware was installed we began installing Microsoft NT Server on the cluster nodes. We experimented with the use of NT Domains for user account management and access control. One of the key issues for managing a computation cluster is being able to dynamically grant and deny access to cluster resources on a user basis. We tried to use the Win32 api to enable and disable user accounts with lists of machine names. Unfortunately, we found a limitation in the api calls that only allow 8 machines to be enumerated. This is a serious scalability design flaw in the api. We then worked on our own user management software to provide this capability based on custom NT services. After a great deal of code development we discovered a way to use NT Domain groups to accomplish this in a much more elegant way. Essentially an NT Domain user group is set up for every node in the cluster. Each node’s local user privileges are set so that only members of this group can access the machine from the console or via the network. An administrator or job scheduler can then easily enable and disable users on any nodes by adding them or removing them from the associated node user groups on the NT Domain Controller. Once these initial steps were completed we turned our efforts toward our plan for using the cluster as part of a scalable, distributed computational resource as we described in the proposal. The following work was done toward each of the steps in our research.
We tested the usability and scalability of two publicly available MPI implementations for NT. The first version was from Portugal (http://dsg.dei.uc.pt/~fafe/w32mpi). It was based on p4 developed at Argonne National Laboratory. It had many problems the worst of which were unreliable job startup and leaving orphaned processes behind on the nodes that could only be cleared by a system reboot. We also tried a message-passing scalability test. The master process of the MPI code would malloc space for a buffer of increasing size. This buffer was then sent from one slave process on each node to the next and finally back to the master processes in a ring. The round trip travel time was then calculated to see how well the network communication system of the cluster scaled. As it turned out only very small buffers could be used (less than one megabyte) because the MPI_SEND calls were not implemented correctly and would cause a core dump for larger buffers. Next we tried the version from Mississippi State University (http://www.erc.msstate.edu/mpi/mpiNT.html). It was based on MPICH developed at Argonne National Laboratory and Mississippi State. The MPI calls were all implemented correctly but we could not to get inter-process communication to work across a network. All the slave processes had to be on the same node. We could not determine why this would not work on the cluster. The real problem with this version was that the NT service that was required on each node ran user processes as an NT administrator. For security reasons this was unacceptable. We recently found and purchased MPI/Pro from MPI Software Technologies (http://www.mpi-softtech.com/ ). We will be beta-testing their early release this spring and summer. MPI Software Technologies is a new company started by Dr. Anthony Skjellum who lead the Mississippi State MPI development effort. This commercial version addresses many of the problems found in the public domain versions. Another advantage with this version is that it supports the Microsoft Visual Studio C as well DEC’s Visual Fortran (http://www.digital.com/fortran). The public domain versions only supported C which limits their usefulness for many scientific codes. We have also recently purchased KAI OpenMP (http://www.kai.com) for parallel programming on SMP nodes with DEC’s Visual Fortran. We will be studying the combination of this with MPI/Pro for distributed shared-memory applications. We have investigated the use of NT job scheduling systems like Condor, HPVM, and LSF. These systems focus on load balancing of serial and small parallel jobs. Our interest is in the scalability of computational clusters for use with massively parallel applications so they are not useful in our environment. These products have also not addressed the more difficult issues of distributed security and administration, which we feel are critical to any systems ultimate acceptance. In a separate project we have been developing a job scheduling system for dedicated NT clusters used for computational science. This system will benefit from the use of NT Domain groups described earlier for distributed security. We plan to implement ARMS on top of that scheduler and the EASY-LL scheduler running on the Cornell IBM SP system. MPI is a critical requirement for most of the applications that we plan on porting to the NT cluster. The problems with the MPI versions we’ve had access to thus far have limited the work we have been able to do in this area. Once we begin beta-testing MPI/Pro we will be trying our MPI scalability tests on both 10T and 100T ethernet networks to see how well the software works in both modes. Based on these results we will begin testing real applications with message-passing requirements that can be met by the clusters network infrastructure. We have been planning to run some large-scale production genetics codes on the cluster which may potentially out-perform the IBM SP. These codes are multi-threaded and have minimal network requirements. We have begun porting these to the cluster. We have recently started discussing using the cluster for some financial risk analysis programs as well.
|
|
Last modified on: 10/07/99 |