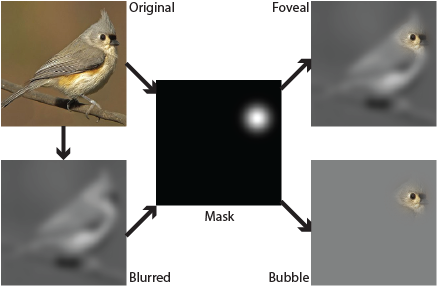

We propose a new method for turning an Internet-scale corpus of categorized images into a small set of human-interpretable discriminative visual elements using powerful tools based on deep learning. A key challenge with deep learning methods is generating human interpretable models. To address this, we propose a new technique that uses bubble images — images where most of the content has been obscured — to identify spatially localized, discriminative con tent in each image. By modifying the model training procedure to use both the source imagery and these bubble images, we can arrive at final models which retain much of the original classification performance, but are much more amenable to identifying interpretable visual elements. We apply our algorithm to a wide variety of datasets, including two new Internet-scale datasets of people and places, and show applications to visual mining and discovery. Our method is simple, scalable, and produces visual elements that are highly representative compared to prior work.
@inproceedings{MatzenICCV15,
author = {Matzen, Kevin and Snavely, Noah},
title = {BubbLeNet: Foveated imaging for visual discovery},
booktitle = {Proc. International Conf. on Computer Vision},
year = {2015},
}
Code and data
- InstagramPeople metadata (17.1 GB) - Millions of Instagram photos with face and body detections. Metadata is included, use the Instagram API to retrieve imagery.
- StreetviewCities metadata (449 MB) - Millions of Street View photos. Metadata is included, use the Street View API to retrieve imagery.
- Caffe foveal layer - Caffe layer for converting images to foveal / bubble images used in our paper. Backward operation is implemented to enable bubble localization using backprop. GPU implementation only. Written for bvlc/caffe master branch circa October 2014.
