Beehive requires a protocol to replicate objects at the replication levels determined by the analytical model. In order to be deployable in wide area networks, the replication protocol should be asynchronous and not require expensive mechanisms such as distributed consensus or agreement. In this section, we describe an efficient protocol that enables Beehive to replicate objects across a DHT.
Beehive's replication protocol uses an asynchronous and distributed algorithm to implement the optimal solution provided by the analytical model. Each node is responsible for replicating an object on other nodes at most one hop away from itself; that is, at nodes that share one less prefix than the current node. Initially, each object is replicated only at the home node at a level k = logbN, where N is the number of nodes in the system and b is the base of the DHT, and shares k prefixes with the object. If an object needs to be replicated at the next level k-1, the home node pushes the object to all nodes that share one less prefix with the home node. Each of the level k-1 nodes at which the object is currently replicated may independently decide to replicate the object further, and push the object to other nodes that share one less prefix with it. Nodes continue the process of independent and distributed replication until all the objects are replicated at appropriate levels. In this algorithm, nodes that share i+1 prefixes with an object are responsible for replicating that object at level i, and are called i level deciding nodes for that object. For each object replicated at level i at some node A, the i level deciding node is that node in its routing table at level i that has matching i+1 prefixes with the object. For some objects, the deciding node may be the node A itself.
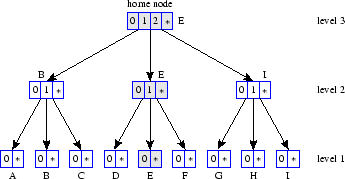 |
This distributed replication algorithm is illustrated in Figure 2. Initially, an object with identifier 0121 is replicated at its home node E at level 3 and shares 3 prefixes with it. If the analytical model indicates that this object should be replicated at level 2, node E pushes the objects to nodes B and I with which it shares 2 prefixes. Node E is the level 2 deciding node for the object at nodes B, E, and I. Based on the popularity of the object, the level 2 nodes B, E, and I may independently decide to replicate the object at level 1. If node B decides to do so, it pushes a copy of the object to nodes A and C with which it shares 1 prefix and becomes the level 1 deciding node for the object at nodes A, B, and C. Similarly, node E may replicate the object at level 1 by pushing a copy to nodes D and F, and node I to G and F.
Our replication algorithm does not require any agreement in the estimation of relative popularity among the nodes. Consequently, some objects may be replicated partially due to small variations in the estimate of the relative popularity. For example in Figure 2, node E might decide not to push object 0121 to level 1. We tolerate this inaccuracy to keep the replication protocol efficient and practical. In the evaluation section, we show that this inaccuracy in the replication protocol does not produce any noticeable difference in performance.
Beehive implements this distributed replication algorithm in two phases, an analysis phase and a replicate phase, that follow the aggregation phase.
During the analysis phase, each node uses the analytical model and the latest known estimate of the Zipf-parameter to obtain a new solution.
Each node then locally changes the replication levels of the objects according to the solution.
The solution specifies for each level i, the fraction of objects, xi that need to be replicated at level i or lower.
Hence,
![]() fraction of objects replicated at level i+1 or lower should be replicated at level i or lower.
Based on the current popularity, each node sorts all the objects at level i+1 or lower for which it is the i level deciding node.
It chooses the most popular
fraction of objects replicated at level i+1 or lower should be replicated at level i or lower.
Based on the current popularity, each node sorts all the objects at level i+1 or lower for which it is the i level deciding node.
It chooses the most popular
![]() fraction of these objects and locally changes the replication level of the chosen objects to i, if their current replication level is i+1.
The node also changes the replication level of the objects that are not chosen to i+1, if their current replication level is i or lower.
fraction of these objects and locally changes the replication level of the chosen objects to i, if their current replication level is i+1.
The node also changes the replication level of the objects that are not chosen to i+1, if their current replication level is i or lower.
After the analysis phase, the replication level of some objects could increase or decrease, since the popularity of objects changes with time. If the replication level of an object decreases from level i+1 to i, it needs to be replicated in nodes that share one less prefix with it. If the replication level of an object increases from level i to i+1, the nodes with only i matching prefixes need to delete the replica. The replicate phase is responsible for enforcing the correct extent of replication for an object as determined by the analysis phase. During the replicate phase, each node A sends to each node B in the ith level of its routing table, a replication message listing the identifiers of all objects for which B is the i level deciding node. When B receives this message from A, it checks the list of identifiers and pushes to node A any unlisted object whose current level of replication is i or lower. In addition, B sends back to A the identifiers of objects no longer replicated at level i. Upon receiving this message, A removes the listed objects.
Beehive nodes invoke the analysis and the replicate phases periodically. The analysis phase is invoked once every analysis interval and the replicate phase once every replication interval. In order to improve the efficiency of the replication protocol and reduce load on the network, we integrate the replication phase with the aggregation protocol. We perform this integration by setting the same durations for the replication interval and the aggregation interval and combining the replication and the aggregation messages as follows: When node A sends an aggregation message to B, the message contains the list of objects replicated at A whose i level deciding node is B. Similarly, when node B replies to the replication message from A, it adds the aggregated access frequency information for all objects listed in the replication message.
The analysis phase estimates the relative popularity of the objects using the estimates for access frequency obtained through the aggregation protocol. Recall that, for an object replicated at level i, it takes 2(logN-i) rounds of aggregation to obtain an accurate estimate of the access frequency. In order to allow time for the information flow during aggregation, we set the replication interval to at least 2logN times the aggregation interval.
Random variations in the query distribution will lead to fluctuations in the relative popularity estimates of objects, and may cause frequent changes in the replication levels of objects. This behavior may increase the object transfer activity and impose substantial load on the network. Increasing the duration of the aggregation interval is not an efficient solution because it decreases the responsiveness of system to changes. Beehive limits the impact of fluctuations by employing hysteresis. During the analysis phase, when a node sorts the objects at level i based on their popularity, the access frequencies of objects already replicated at level i-1 is increased by a small fraction. This biases the system towards maintaining already existing replicas when the popularity difference between two objects is small.
The replication protocol also enables Beehive to maintain appropriate replication levels for objects when new nodes join and others leave the system. When a new node joins the system, it obtains the replicas of objects it needs to store by initiating a replicate phase of the replication protocol. If the new node already has objects replicated when it was previously part of the system, then these objects need not be fetched again from the deciding nodes. A node leaving the system does not directly affect Beehive. If the leaving node is a deciding node for some objects, the underlying DHT chooses a new deciding node for these objects when it repairs the routing table.